1. dom4j

2. 使用dom4j解析xml文档:
<1> 准备好需要解析的文件 (NewFile.xml)
<!-- NewFile.xml -->
<?xml version="1.0" encoding="UTF-8"?> <!-- XML的文档声明, 必须放在第01行 --> <goodslist> <!-- 标签是大小写敏感的, 与HTML不同 --> <good id="1001" production_date="2018-4-1"> <!-- 每个标签都可以拥有属性, id是属性名, "1001"是属性值,必须使用双引号引用。它们都是自定义的 --> <price>12</price> <name>香蕉</name> <place>广州</place> </good> <good id="1002"> <price>39</price> <name>苹果</name> <place>北京</place> </good> <good id="1003"> <price>33</price> <name> 芒果</name> <place>上海</place> </good> </goodslist>
<2> 引入jar包dom4j
<3> 创建一个解析XML的类 (parseXML)
<3-1>官方文档:
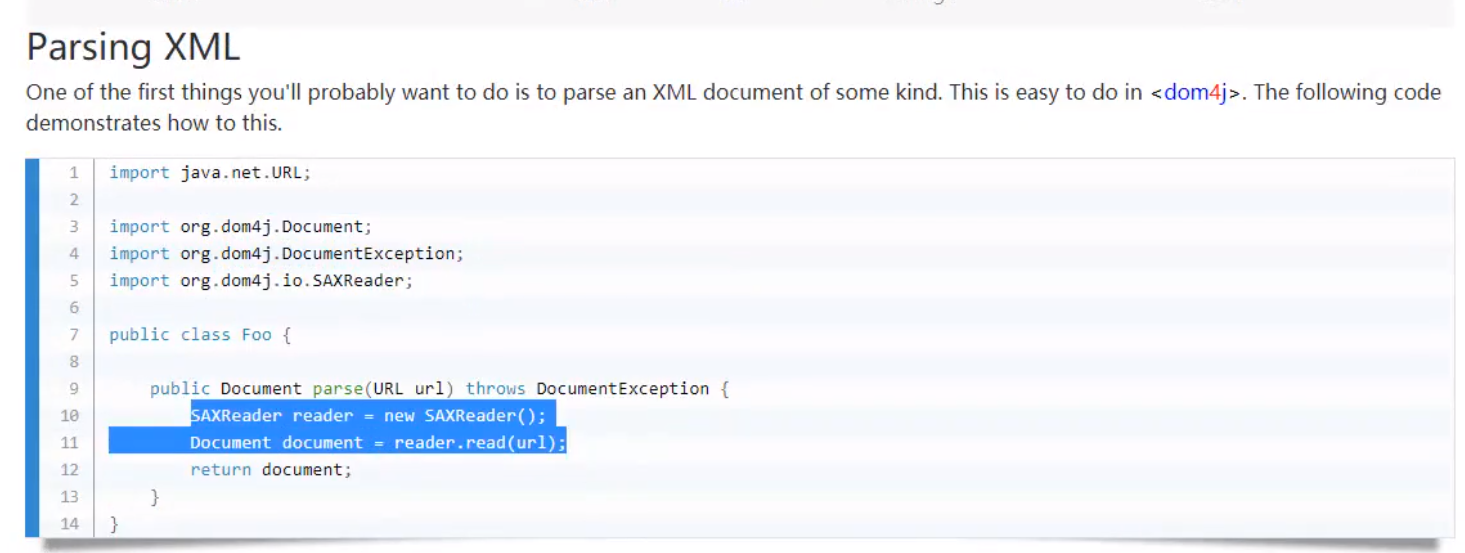
url 代表需要解析的文档的路径
<3-2>
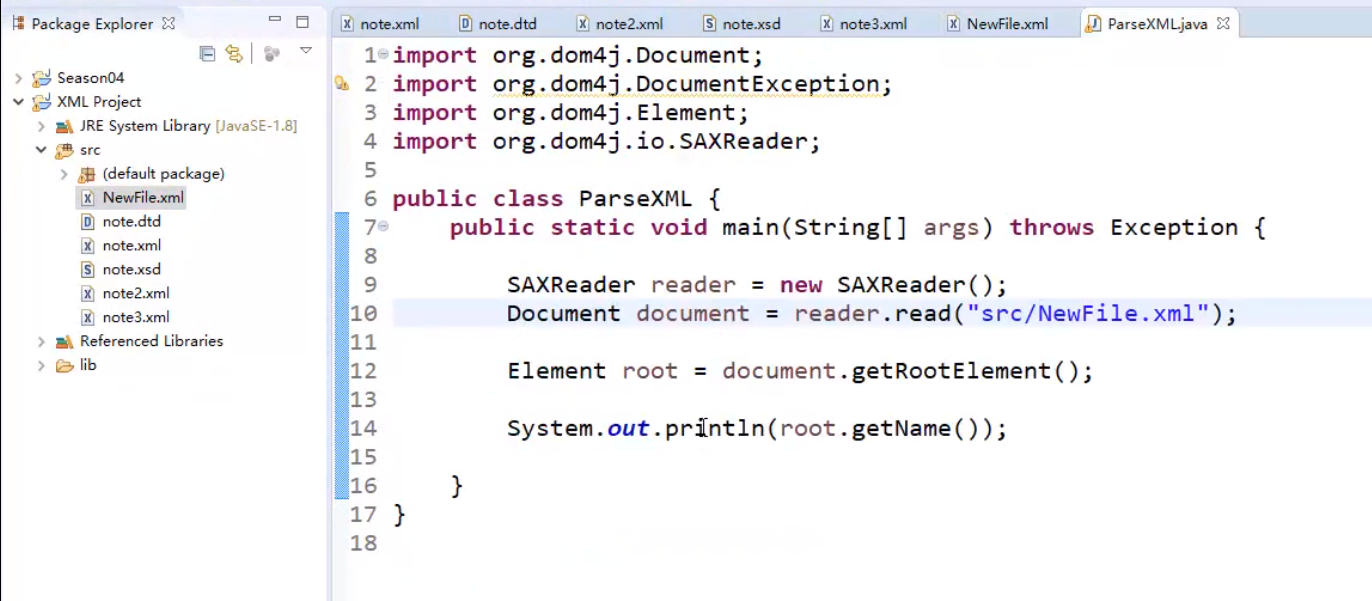
通过 document.getRootElement 获得根标签, 最终的输出结果是 goodslist
<3-3>
通过根标签, 可以获得子标签
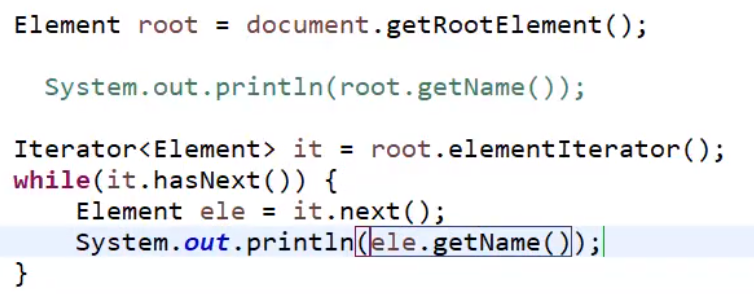
如图,输出了所有子标签的名字(不输出“孙子”元素)
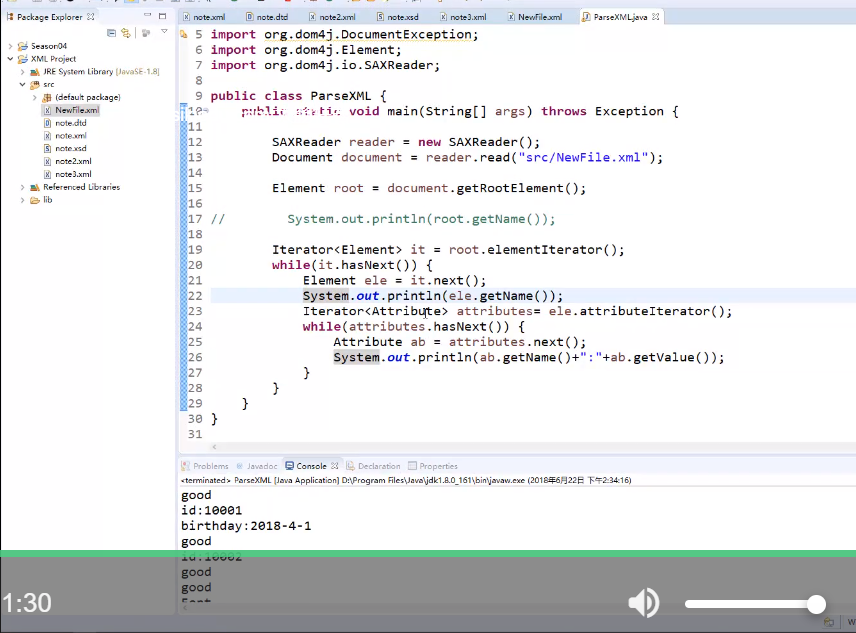
<3-4> 输出标签下的属性名与属性值

<3-5> 总体效果