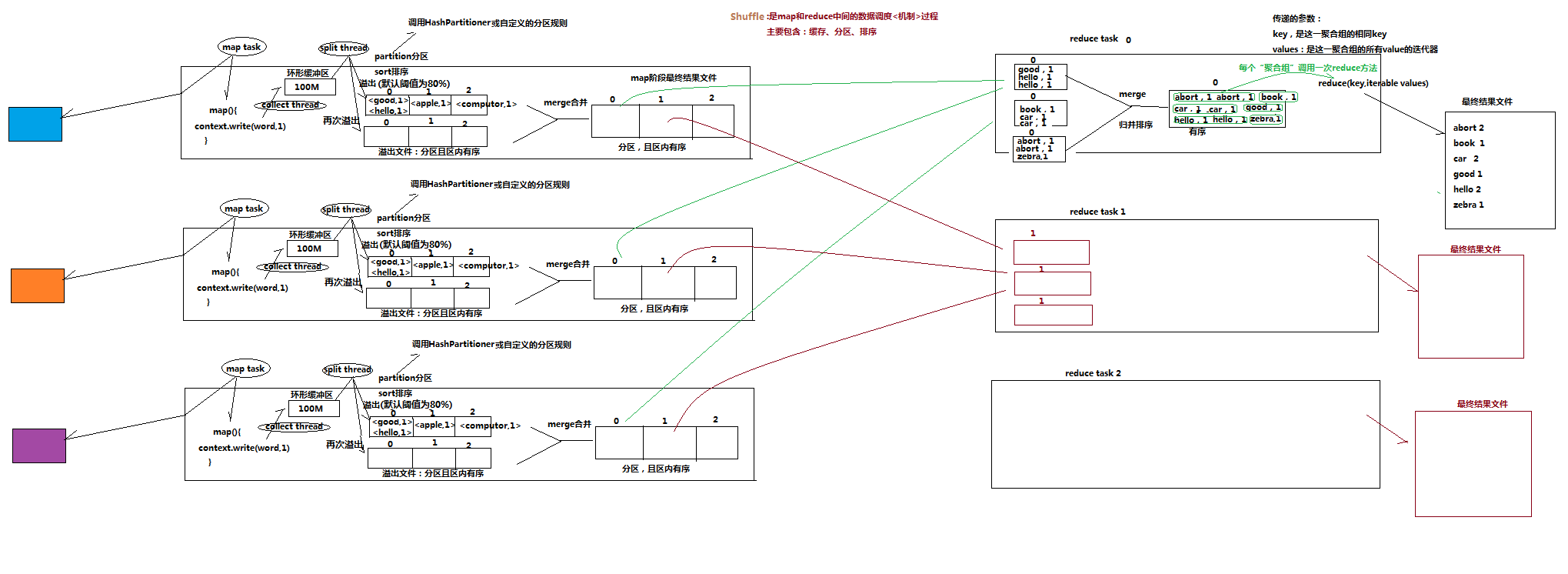
Shuffle是map和reduce中间的数据调度过程,包括:缓存、分区、排序等。
Shuffle数据调度过程:
map task处理hdfs文件,调用map()方法,map task的collect thread将map()方法结果放入环形缓冲区(默认大小100M)- 当环形缓冲区达到
阈值(80%),将会触发溢出操作,split thread线程会调用HashPartitioner或者自定义的分区规则,对缓冲区内容进行分区,区内文件内容有序。 - 当环形缓冲区再次达到阈值,会再次触发溢出操作,重复步骤2
map()方法执行结束后,会生成一系列分区且区内有序的溢出小文件。该溢出小文件不会直接交给reduce()方法,会进行merge操作,将溢出的小文件按分区进行合并,生成一个完整的分区且区内有序的大文件。- 每个
reduce task会获取每个map task阶段最终结果文件的指定分区文件内容,进行归并排序操作,按照key排序,生成一个聚合组。 - 每个
聚合组调用一次reduce()方法,key为这一聚合组的相同key,values是这一聚合组的所有value的迭代器。 - 生成最终结果文件。
Shuffle数据调度过程(大图链接):