OID
1,对象里面没有主键的概念,对象中对应主键的属性,称为OID(对象标识符);
2,OID用来唯一标明一个对象实体(加上对象类型)
3,OID在对象里面不见得只有一个属性;(映射复合主键)
4,OID是一种特殊的属性,所以属性上的column,type,access都可以在<id>元素使用;
5,OID分为自然主键和代理主键;
1),代理主键:没有任何业务逻辑的主键;
2),自然主键:有业务逻辑的主键;
推荐使用代理主键;
6,一般情况下,会使用OID来重写equals和hashCode方法;
主键生成策略:
1,assigned:针对自然主键来说;(手动设置主键值,都用assigned)
assigned只能针对一个自然主键来说;
2,uuid:使用UUID来生成主键;
1),主键的类型必须是string;
2),主键的值是hibernate生成的,所以hibernate在插入对象之前,已经知道对象的主键值了;
3),可以使用UUID,
3,increment;递增;
1),主键类型需要是long ,integer等可以增加的数字类型;
2),首先查询出当前表最大的id,id+1再设置为当前对象的主键值;
3),hibernate会把每一个类型的increment值缓存起来,提高性能;
4),hibernate在插入对象之前,已经知道对象的主键值了
5),increment性能较高,不能在集群的环境下使用;
4,identity;使用数据库本身的自增主键生成方式;
1),对于MYSQL来说,其实我们使用native的时候,就是使用了identity方式;
2),要使用identity,必须要求数据库支持自增的方式,SQL SERVER(identity)
3),oracle不支持identity方式;
4),不支持数据库的迁移;
5,native:native就是使用数据库支持的主键生成方式;
对于MYSQL来说,使用identity;
对于ORACLE来说,使用sequence;
6,TableGenerator;使用一个额外的表(默认hibernate_sequences)来模拟序列生成器;
1),如果没有其他配置,hibernate会使用一个叫做default的序列生成器为所有的对象生成主键;
2),可以设置segment_value来为每一个对象单独创建一个序列生成器;
3),默认情况下,每生成一个主键需要两个SQL,性能不高(1,select:获取当前id;2,update:更新next_val)
4),性能提升,increment_size:设置一次可以取多少个值;(但是会造成id的不连续,cache)
5),数据库无关的,(在迁移的时候要拷贝hibernate_sequences表);
6),所以hibernate在插入对象之前,已经知道对象的主键值了;
7),table是一种非常好的主键生成方式;
选择:
1,判断使用自然主键还是代理主键;(自然主键assigned)
2,是否需要有数据库迁移的需求;(使用数据库无关的生成策略;)
3,性能
4,是否在集群环境使用;
5,单应用使用navtive;
session的方法补充,session提供了各种对象持久化的方法;
1,save:保存对象;
2,delete:删除对象;
3,update:修改对象;
4,get:通过主键得到一个对象;
5,createQuery:创建一个查询对象;
6,clear:清除一级缓存所有对象;
7,evict:清除一级缓存中指定的对象;
8,close:关闭session;
补充的方法:
1,saveOrUpdate:保存没有id的对象,修改有id的对象;
2,load
1),get方法,在调用get方法的时候就会立刻去发送一条SELECT查询,如果没有结果,返回null,如果有结果,返回对象,
2),load方法和get一样,也能够查询指定id的对象;
3),load方法把真正执行select延后到了使用这个对象的时候,我们叫做延迟加载;
4),什么叫使用这个对象?在使用对象非主键属性的时候;
5),load方法的原理:
1),load方法返回的对象是hibernate动态为我们的domain创建的一个子类;
2),hibernate在这个子类里面重写了非主键的属性的getter方法,和tostring方法;
3),hibernate为这个子类添加了一个(是否加载完成)的状态;如果在调用这个对象的getter方法的时候,这个对象还没有被加载,就发送SQL去查询对象,并且把查询到的结果设置到对象中,并设置是否加载完成状态为[加载完成];如果之后再去调用getter方法,因为已经加载完成了所以,只需要直接返回这些属性的值就可以了;
4),hibernate使用javassist来完成延迟加载子类的动态生成;
5),如果在session关闭之前没有去实例化延迟加载对象,会报no session错误
6),用load方法返回的对象永远不可能为空;
7),如果load方法返回的对象在使用的过程中发现数据库里面没有值对应,报错;
8),如果要使用load方法,请保证id在数据库中一定存在;
3,persist:
1),把对象保存到数据库中;
2),persist方法要执行,必须在事务空间之内;
4,merge:
1),相当于update方法;
2),merge方法要执行,必须在事务空间之内;
hibernate对象状态
1,几个问题:
1),主键的生成策略不同,发送INSERT语句的时间不一样??????
2),删除对象的时候其实并没有立刻发送delete语句??????
3),为什么get方法得到的对象,修改了属性,会发送UPDATE语句???
结论:在hibernate当中,session的方法其实和SQL并没有任何关系;所以,要理解session的方法,要理解hibernate执行的流程,不能从SQL这个角度去理解,只能从对象的角度理解;
session的方法到底在干嘛?hibernate对SQL又是怎么处理的呢?
session的方法在促使对象的状态发生变化;
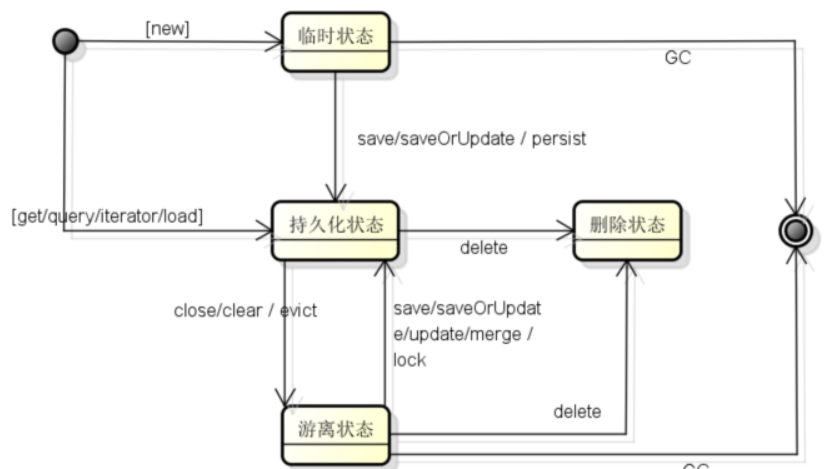
hibernate中对象的状态:
1,临时状态:刚new出来,没有id,[数据库里面没有值对应];
2,持久化状态:有id,并且被session(hibernate)管理,[数据库里面有值对应]
3,游离(脱管)状态:有id,没有被session(hibernate)管理,[数据里面有值对应]
4,删除状态:有id,计划被删除,[数据库里面有值对应]
session的方法在让对象的状态发生什么样的变化?
临时状态:
1,new 语句刚创建了一个对象。
2,删除状态的对象session提交,对象处于临时状态。
3,use_identifier_rollback
持久化状态:
1,save方法把临时对象变成持久化状态,save方法把游离对象变成另一个持久化对象。
2,get方法返回的对象是持久化状态
3,load方法返回的对象是持久化状态
4,Query.list()方法返回的实体对象是持久化状态,在处理大数据量的时候,需要及时清理缓存。
5,update方法把游离对象变成了持久化对象。
游离状态:
1,session.close()方法把所有(关闭的那个session)持久化对象变成游离对象
2,session.clear()方法把所有(调用clear方法的session)持久化对象变成游离对象
3,session.evict(Object)方法把指定的持久化对象变成游离对象。
删除状态:
1,delete方法让持久化状态和游离状态变成删除状态。但是删除状态的对象必须要等到session刷新,事务提交之后才真正的从数据表里面删除。
1,几个问题:
1),主键的生成策略不同,发送INSERT语句的时间不一样??????
答:因为save方法是把对象从临时-->持久化,它只需要去找到ID即可;不同的主键生成策略,有的必须要发送insert才能够得到id,有的不需要发送insert就能够得到id,所以这时候,就不需要发送insert语句了;
2),删除对象的时候其实并没有立刻发送delete语句??????
答:因为delete方法仅仅只是把游离对象或持久化对象变成删除对象,所以他并非不负责sql的发送;
3),为什么get方法得到的对象,修改了属性,会发送UPDATE语句???
答:这个问题应该修改为持久化对象的属性真正发生变化的时候,才会去发送UPDATE语句;
在什么时候去发送的SQL;
默认情况下,在事务提交的时候,会自动的去数据库里面同步这一次对象的变化对应的SQL;
总结:由session的持久化方法改变对象的状态,在同步session时候(默认情况是提交事务/flush),session再同步脏数据到数据库,完成内存对象和数据库内容的同步;
一句话:session负责改变状态 提交事务负责同步数据
到底在提交事务的时候,要发送哪些SQL?
1),会把由临时对象变成的持久化对象的SQL发送;--->insert;
2),会把持久化状态和游离状态变成的删除状态发送SQL--->delete;
3),会把游离状态变成持久化状态的对象发送SQL;
4),会把脏的持久化状态对象自动同步到数据库中;
5),通过session.flush方法,可以手动同步数据库;
对象的关系:
1),依赖关系:如果A对象离开了B对象就不能编译,那么A对象依赖B对象;
2),关联关系:如果A对象依赖B对象,并且把B对象作为A对象的一个属性,我们就说,A对象和B对象是关联关系;
关联关系从多重性来讲:
一对多:一个A包含多个B;
多对一:多个A属于一个B;并且一个A只能属于一个B;
多对多:一个A属于多个B,一个B可以属于多个A;
一对一:一个A属于一个B,一个B属于一个A;
关联关系从导航性来讲(java代码):通过A的某一个属性能够访问到和这个属性关联的B对象,A能够在这个关系上面导航到B;
单向;如果针对一个关联关系,只能由一边通过属性导航到另一边,
双向;如果针对一个关联关系,A能够通过属性导航到B,并且B也能够通过属性导航到A;
关系的判定:
1),关系的判定是针对实体判断,不是针对类来判断;
2),关系的判定是针对一对特定的属性判断;
3),关系的判定要结合具体的需求;
聚合关系:是一个关联关系,部分和整体的关系;部分和整体是可以单独存在的,在系统当中,一定是两个模块在分别管理整体和部分;
组合关系:是一种强聚合关系,但是部分和整理是不能单独存在的,在系统当中,一定是在一个模块中管理的;
泛化关系:继承;
单向的多对一
表的设计和SQL

映射方式

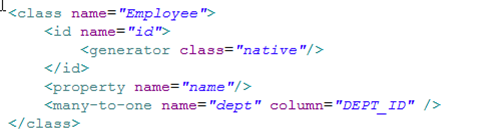
save方法的执行流程

进一步研究Get方法

进一步研究save方法
先保存many方再保存one方,会产生额外的SQL,这些SQL是由于持久化对象(many)的脏数据造成的;
单向的一对多
表的设计和SQL

映射方式


进一步研究Get方法
