双向的many2one/one2many
双向many2one/one2many的问题:
一定有额外的SQL发出;
在数据库里面,外键表示many2one或者one2many的关系,外键是没有方向的;但是在面向对象里面,关系有方向,所以两个方向都要去管理这个外键,造成的额外的SQL(这些多余的SQL都是ONE方想去管理many方造成的);
我们既想保留对象中的双向的关系;又想减少额外的SQL,所以需要像下图一样配置映射文件

对象的删除:
1,many方都可以直接删除;
2,删除one方:
1),inverse="false":可以正常删除;
Hibernate: update Employee set DEPT_ID=null where DEPT_ID=?
Hibernate: delete from Department where id=?
2),inverse="true":不能正常删除:
外键约束错误;
选择:
1,90%的情况,使用单向的many2one;(删除使用HQL;)
2,9%的情况使用双向的many2one/one2many:
1),自连接(树状结构;);
2),组合关系;
3,1%的情况使用单向的one2many;(使用两个one2many来实现many2many)
hibernate中的集合:
1,在hibernate中,集合只能使用接口
2,集合的使用;
1),Set:代表集合中的对象不能重复;集合中的对象没有顺序;对于Set集合,只能使用<set>元素来映射;
2),List:集合中的对象可以重复,集合中的对象是有顺序的;
<list name="ems" inverse="true"> <key column="Dept_ID"/> <list-index column="SEQ"/> <one-to-many class="Employee"/> </list>
1),要让one方知道many方的顺序,必须在many方的表中添加一列用来保存顺序;
2),这个顺序只有one方知道,所以,这个列应该由one方来维护;
3),在<list>元素中添加<list-index>来映射这个列;
4),不管list的inverse=true,总要发送额外的SQL去维护这个many方的顺序;
3),第二种映射List的方式:
1),如果只是想把List作为一个集合,而不让hibernate来帮我们维护顺序,就可以是用<bag>
2),bag元素不关心one中many方的顺序;
<bag name="ems" inverse="true"> <key column="Dept_ID"/> <one-to-many class="Employee"/> </bag>
3,选择:
1),确定集合中的对象是否能重复;
2),如果使用List,尽量使用bag来映射;
3),如果必须要让many方有顺序;在many方中添加一个表示顺序的属性,
1,在many方添加一个顺序的属性,并且在映射文件中设置
public class Emloyee{
private Long id;
private String name;
private Department dept;
private Integer sequence;
//省略get/set
}
<class name="Employee" table="employee">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
<property name="sequence" column="sequence"/>
<many-to-one name="dept" column="Dept_ID"/>
</class>
2,在one方的集合上面添加order-by属性
<bag name="ems" inverse="true" order-by="sequence">
<key column="Dept_ID"/>
<one-to-many class="Employee"/>
</bag>
order-by属性的意思是,在加载many方集合的时候,使用order by语句按照many方的指定属性来查询;
级联:
组合关系:强聚合关系,代表整体和部分之间不能分开,整体和部分单独存在没有意义;
分析:
1,组合关系的两个对象都是在一个模块当中管理的;都是在整体那个对象的模块中管理;
2,对于销售订单对象来说:
1),存在一个列表;
2),添加:在添加页面需要添加销售订单对象上的属性,还需要添加这个销售订单的明细数据;
3),修改:仍然在销售订单的编辑页面中完成;
4),删除:在销售订单列表中删除销售订单;
3,对于销售订单明细对象来说:
1),对于销售订单明细对象,不需要列表;
2),添加:
1),在销售订单对象的添加的时候,可以添加销售订单明细对象;
2),在销售订单对象的保存,可以添加销售订单明细对象;
3),修改:在销售订单对象的修改方法中完成的;
4),删除:在销售订单对象的修改方法中完成的;在删除销售订单的时候,也要去删除这个销售订单的明细;
分析执行流程:
1,只需要有销售订单对象的DAO接口就可以了,销售订单明细的CRUD都是在销售订单对象的DAO中完成的;
2,save:
1),保存销售订单对象;
2),保存销售订单对象对应的销售订单明细对象;
3,update:
1),修改销售订单对象(游离);
2),保存新的销售订单明细对象(临时对象);
3),修改修改过的销售订单明细对象(游离);
4),删除去掉了的销售订单明细对象(删除和主对象没有关系的销售订单明细对象);
4,delete:
1),删除销售订单对象的明细;
2),删除主对象;
使用级联来完成SaleBillDAOImpl:(在组合关系中,一般把整体称为主对象,把部分称为子对象)
1,在one方的集合上面,可以添加cascade属性,这个属性的意思就叫做级联;
2,级联能根据配置的级联策略,对这个集合里面的对象自动做一些操作;
级联策略:
1,save-update:在保存或者修改主对象的时候,去级联的持久化临时的子对象,修改游离的子对象;
2,delete:在删除主对象的时候,去级联的删除所有的子对象;
3,all:save-update+delete
4,delete-orphan:删除和主对象打破关系的子对象;
5,all-delete-orphan:all+delete-orphan
6,一般来说,对于组合关系,我们就直接使用all-delete-orphan就可以了;
PS:
Hibernate.initialize(bill.getItems());
可以使用Hibernate.initialize去初始化一个代理对象;
一对一:
1,使用many2one来实现one2one
hibernate在这种方式映射one2one不是很好理解(不讲)
2,使用主键外键的方式来实现one2one
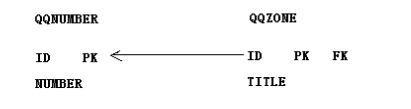
两种实现方式的区别:
1,使用第一种方式两个对象没有先后之分,都可以独立存在;
2,使用第二种方式,主对象必须先存在,再有从对象;
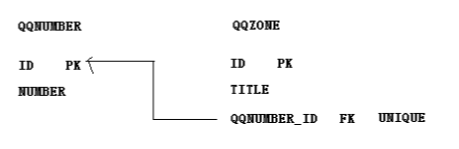
映射文件(以QQ和QQ空间的关系为例):
<class name="QQNumber" table="qqNumber">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="number" column="number"/>
<one-to-one name="zone"/>
</class>
<class name="QQZone" table="qqZone">
<id name="id" column="id">
<!-- foreign表示参照其他主键来生成主键id -->
<generator class="foreign">
<!-- 根据属性number对应的类的主键生成主键 -->
<param name="property">number</param>
</generator>
</id>
<property name="title" column="title"/>
<!-- constrained表示在主键上面添加number属性的外键约束 -->
<one-to-one name="number" constrained="true"/>
</class>
1,在从对象中,从对象的主键需要参照number属性的主键来生成,所以从对象的主键生成策略为foreign;
2,在foreign策略中,需要配置一个property(属性),告诉hibernate,从对象的主键是根据哪个属性对应的主键来生成;
3,默认情况下,one2one并没有生成从对象主键的外键约束,在从对象中的one-to-one元素中添加constrained属性来为从表的主键添加外键约束;
4,不管是先保存从对象还是先保存主对象,甚至直接保存从对象,hibernate都会先保存主对象,在保存从对象;
5,从主对象拿从对象,不存在延迟加载的问题,hibernate使用一条SQL就把主对象和对应的从对象一起查询出来了;
思考:为什么hibernate在这个地方不用延迟加载,他是不想用,还是不能用?为什么?
6,从从对象拿主对象,使用延迟加载;
1),必须在session关闭之前实例化主对象;
2),一定存在主对象;
思考:为什么从对象拿主对象又可以使用延迟加载?
选择:
1,一般情况下,都不会使用one2one关系,我们一般都直接使用单向的many2one+业务逻辑来完成one2one;
2,如果非得使用one2one,使用主键外键的方式实现;
组件关系:
粗粒度的对象设计
public class Company {
private Long id;
private String name;
private String provice;
private String city;
private String street;
private String regProvice;
private String regCity;
private String regStreet;
//省略get/set
}
细粒度的对象设计
public class Company {
private Long id;
private String name;
private Address address;
private Address regAddress;
//省略get/set
}
public class Address {
private String provice;
private String city;
private String street;
//省略get/set
}

分析:
1,对象粒度细,分工明确;
2,地址表可以被其他的表重复使用;
3,需要连接很多表才能完成查询;
为了提高性能,我们可以把address的所有内容直接放到company表中,在表里面,相当于只有一张表,在对象中,有多个对象;
我们把单独存在没有意义,必须在其他对象中存在才有意义的对象(没有自己的表,它的属性都是在主表中),把这种对象称为组件对象
我们把组件对象依赖的那个主对象,称为组件对象的宿主对象;
分析
1,对于对象来说,对象粒度够细;
2,对于宿主对象来说,查询够快;
3,组件对象的内容不能被其他对象直接使用;
映射文件:
<class name="Company" table="company"> <id name="id" column="id"> <generator class="native"/> </id> <property name="name" column="name"/> <!-- 配置组合关系 --> <component name="address"> <property name="provice"/> <property name="city"/> <property name="street"/> </component> <component name="regAddress"> <property name="provice" column="REG_PROVICE"/> <property name="city" column="REG_CITY"/> <property name="street" column="REG_STREET"/> </component> </class>
说明
1,只有一个映射文件(宿主对象的映射文件);
2,组件对象使用component元素来映射,在component元素中,使用property子元素来映射组件对象中的属性;
3,如果一个宿主对象中存在同一个组件对象2个以上;必须在其中一个的property中修改列的名字;
4,查询的时候使用一条SQL查询,不存在延迟加载问题;
many2many(以老师和学生的关系做为例子):
表的设计和SQL
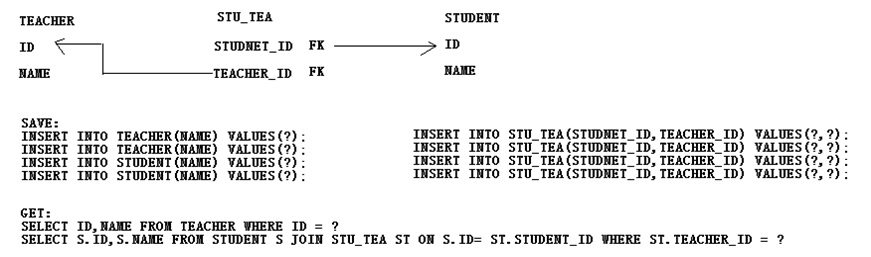
映射文件
<class name="Teacher" table="teacher"> <id name="id" column="id"> <generator class="native"/> </id> <property name="name" column="name"/> <set name="students" table="STU_TEA"> <key column="TEA_ID"/> <many-to-many class="Student" column="STU_ID"/> </set> </class> <class name="Student" table="student"> <id name="id" column="id"> <generator class="native"/> </id> <property name="name"/> <set name="teachers" table="STU_TEA" inverse="true"> <key column="STU_ID"/> <many-to-many class="Teacher" column="TEA_ID"/> </set> </class>
进一步研究:
1,在映射文件里面,set需要table属性,来告知中间表;
2,set中的key子元素代表,在中间表里面那格列作为外键关联到我自己;
3,many-to-many元素:和集合中的对象是多对多的关系;
4,many-to-many的column属性代表:在中间表里面那个列作为外键关联到对方表的主键;
5,many-to-many双方的配置其实是相反的;
6,如果配置的集合是set,hibernate会为中间表创建一个复合主键,
7,不管集合是list还是set,都需要让一边放弃对关系的维护inverse=true;
8,get的时候,使用延迟加载;
1),必须在session关闭之前初始化;
2),不能使用ifnull来判断集合中是否有对象,只能使用size()来判断;
9,一般来说,我们使用单向的many2many;
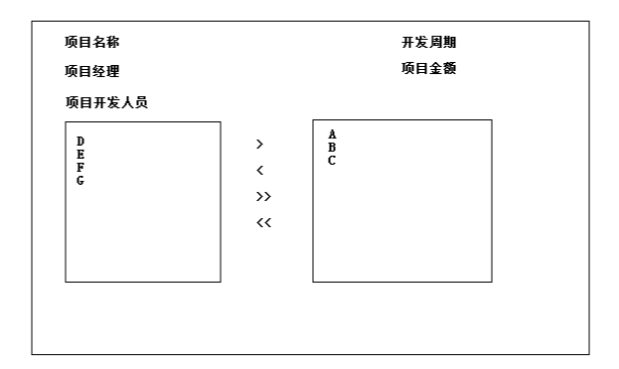
10,在项目中,我们应该让哪边来维护关系?需要看具体的设计.页面里面;
哪个模块在管理关系,我们就把关系配置在哪边(如下图的设计,便是把关系配置在项目模块).
泛化关系(继承关系):
one-table:
表结构和SQL

映射文件
<class name="Product" table="product" discriminator-value="1"> <id name="id" column="id"> <generator class="native"/> </id> <!-- discriminator表示一个鉴别器,type表示鉴别器所属列的类型 --> <discriminator column="TYPES" type="int"/> <property name="name" column="name"/> <subclass name="Book" discriminator-value="2"> <property name="isbn"/> <property name="author"/> </subclass> <subclass name="Clothes" discriminator-value="3"> <property name="color"/> </subclass> </class>
分析:
1,整个继承体系的所有对象的所有属性全部放在一张表里面;
2,只需要一个映射文件,并且这个映射文件映射整个继承体系的根对象;
3,需要创建一个鉴别器的列;
4,需要为每一个类设置对应鉴别器列的值;
5,在多态查询的时候,需要查询出所有的列,并根据鉴别器的值选择需要实例化的真正对象;
one-table的优劣势
1,优点:简单;多态查询非常块;
2,缺点:表结构不稳定;数量增长很快,要查询某一个具体的类型很慢;null字段;
没法使用非空约束;
pre-table:
表结构和SQL
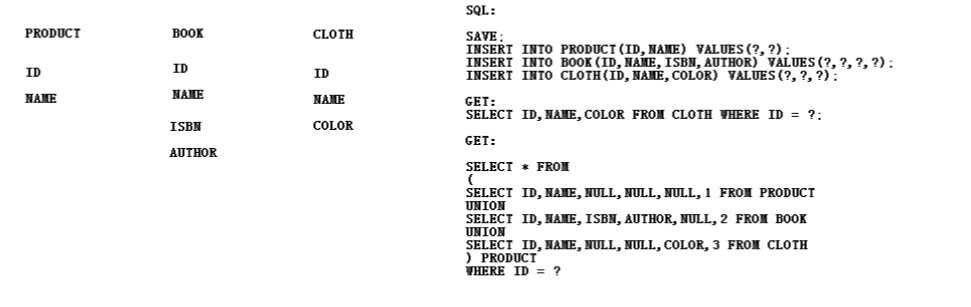
映射文件
<class name="Product" table="product"> <id name="id" column="id"> <generator class="increment"/> </id> <property name="name" column="name"/> <union-subclass name="Book" table="book"> <property name="isbn"/> <property name="author"/> </union-subclass> <union-subclass name="Clothes" table="clothes"> <property name="color"/> </union-subclass> </class>
小结:
1,继承体系中的每一个对象单独放在一个表里面;
2,为了防止id的冲突,所以per-table的方式要求id不能使用自动增长的方式;
3,使用union-subclass映射子类
4,在多态查询的时候,需要把所有的表使用union拼装成一个大表,并在这个大表中使用class来分辨具体的子类型;
优劣势:onetable的优势就是pertable的劣势;onetable的劣势就是pertable的优势
选择:
1,一般情况尽量避免使用继承;
2,如果真的需要使用继承,请使用onetable的方式;
映射枚举类型:
在枚举里面,一个枚举实例有两个值:
name:枚举的名字,可以使用枚举类型.valueOf(String)方法来还原这个枚举类型实例;
1,数据库直观;2,枚举类型位置随意变化;
ordinal:枚举在该类型中的位置;可以使用Sex.values()[0]来根据索引位置类还原这个枚举类型实例;
2,可以修改枚举类型的名字;
映射方式:
<property name="sex"> <!-- 此处类型需要引入使用枚举类的类,全限定名如下 --> <type name="org.hibernate.type.EnumType"> <!-- 引入枚举类的类型,写全限定名 --> <param name="enumClass">com.rk1632._07_enum.Sex</param> <!-- 是否使用枚举属性名作为数据库保存的方式 --> <!-- 如果为false,则会使用枚举属性的顺序作为数据库保存数据的方式(从零开始) --> <param name="useNamed">true</param> </type> </property>
1,如果使用名字的方式映射,设置useNamed为true,如果使用位置的方式,useNamed为false;
2,记得,枚举类型要写全限定名;