问题
当使用大型数据模型,缓慢的基础数据源或Power BI中的复杂报表时,我们有时会陷入与性能问题作斗争的困境。这会花费大量的开发时间,而这些时间本来应该用于报表开发。我已经介绍了一些最佳实践和实用实施,您可以在对性能问题进行故障排除或优化Power BI报表性能时考虑这些最佳实践。
由于加载大数据模型而可能导致的典型问题包括:
- 需要不同的许可证容量来存储模型。Power Premium Pro只能容纳1GB的型号,尽管Premium允许的最大尺寸为13GB。
- 较大的数据模型大小通常会增加对诸如内存之类的容量资源的争用。这不允许在更长的时间段内同时加载更多模型,从而导致更高的收回率。
- 较大的模型实现较慢的数据刷新,从而导致较高的延迟报告,较低的数据集刷新吞吐量以及对源系统和容量资源的压力增加。
为了便于理解,本技巧分为三个帖子。
解
优化或对性能问题进行故障排除时,可以考虑几个选项,但是我将集中精力处理本系列中的以下选项。
- 实施垂直过滤
- 在Power Query中创建的自定义列的首选项
- 在数据加载选项设置中禁用“自动日期/时间”
- 使用数据的一部分进行开发或水平过滤
- 尝试在DAX度量计算中使用更多变量
- 禁用非必需表的Power Query查询负载
在本系列文章中,我仅缩小了在Power BI环境中可以完成的工作,可以在Power BI环境之外进行更多选择以加快Power BI中的查询性能,包括创建索引,通过在源处进行操作来更改数据集。在连接到Power BI等之前
本系列的第1部分将重点讨论上述前两个项目可以解决的问题。
在Power BI中实现垂直过滤
表列的两个主要目的包括报告 和模型结构。因此,优良作法是仅设计仅具有所需列的模型。无论Vertipaq存储引擎在帮助压缩和优化数据方面有多高效,实现减小模型大小的方法仍然非常重要。因此,要实现这一点,下面有一个示例,说明如何通过实现垂直过滤(即删除不必要的列)来减小大小模型。
在下图中,我已将AdventureOrder 2014数据库中的SalesOrderHeader表导入到Power BI数据模型中。
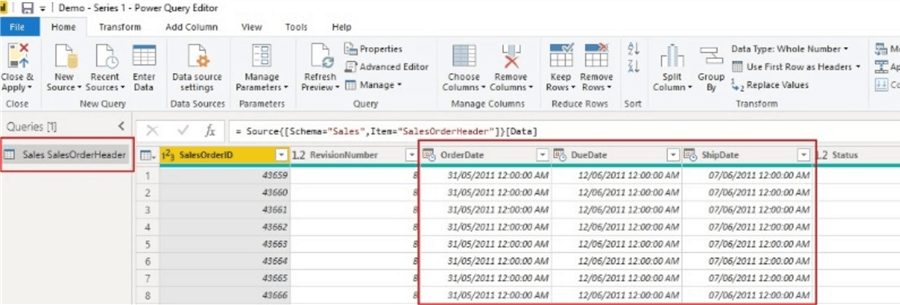
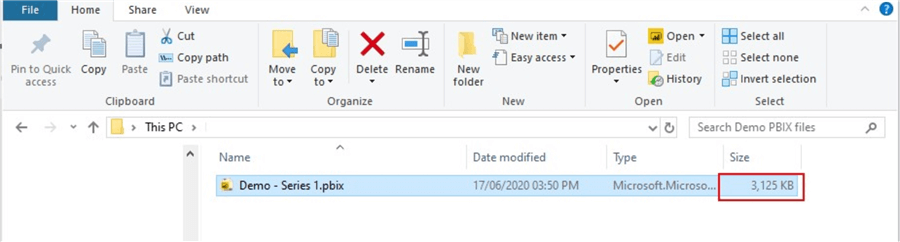
导入的表有26列,其中包括4个datetime列。因此,当我将该模型保存到文件位置时,可以查看模型的大小,如下所示,该大小当前为3,125KB。
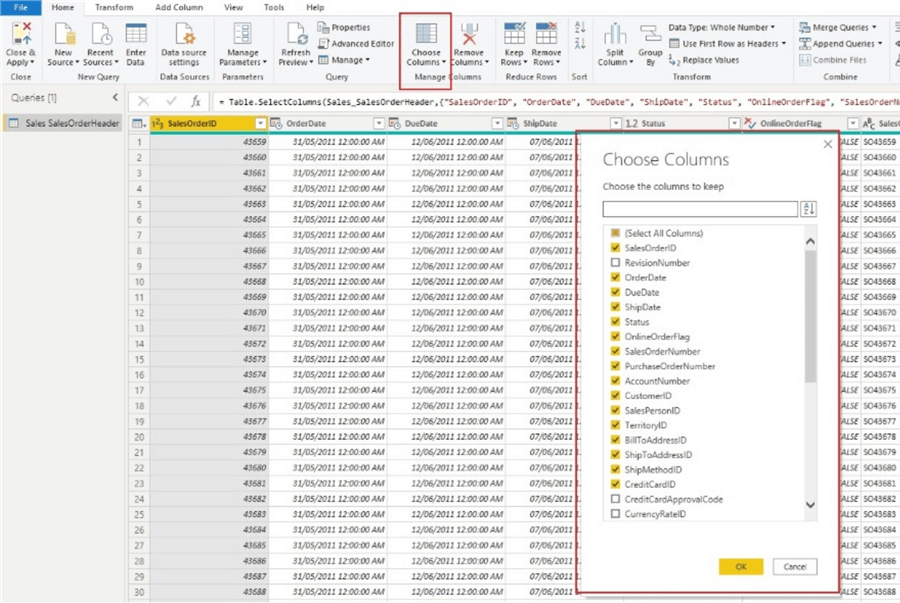
但是,如果这是一个非常大的模型,则可以想象它的大小会更大,而应用垂直过滤的方法将是删除不支持报告和模型结构的列。在下图中,我删除了大约七列。
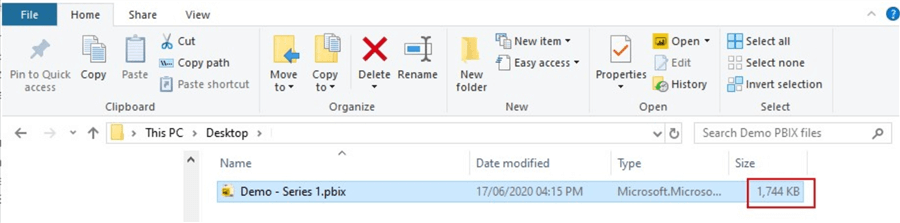
现在,如果我们再次查看PBIX文件的保存位置,我们可以看到它已将模型大小从3,125KB减少到1,744KB,大约是初始大小的一半。同样,当使用非常大的数据模型(呈指数增长)时,这可能是一个很大的差异。
在Power Query中创建的自定义列的首选项
最好的做法是创建更多的计算列,就像用M语言定义的Power Query 计算列一样。众所周知, 将表列添加为DAX计算列的效率不如使用Power Query选项有效,但是,有一些例外情况可以证明,其中某些计算列只能在DAX中完成。如下所示,需要注意的是,Vertipaq存储引擎以与Power Query M语言计算列相同的方式存储模型DAX计算列,但是在计算的DAX中效率低下和数据刷新时间延长引起的问题列的产生是由于数据结构的存储方式以及较低的压缩效率。
在下图中,我创建了一个列来更改“ OnlineOrderFlag”列的值,该列是布尔(True / False)列。如果值为“ TRUE”,我们希望为“在线”,如果值为“ FALSE”,我们希望为“店内”。这可以通过两种方式完成,即Power Query M计算列或DAX计算列。
首先,让我们看看如何在Power Query M计算列中做到这一点。
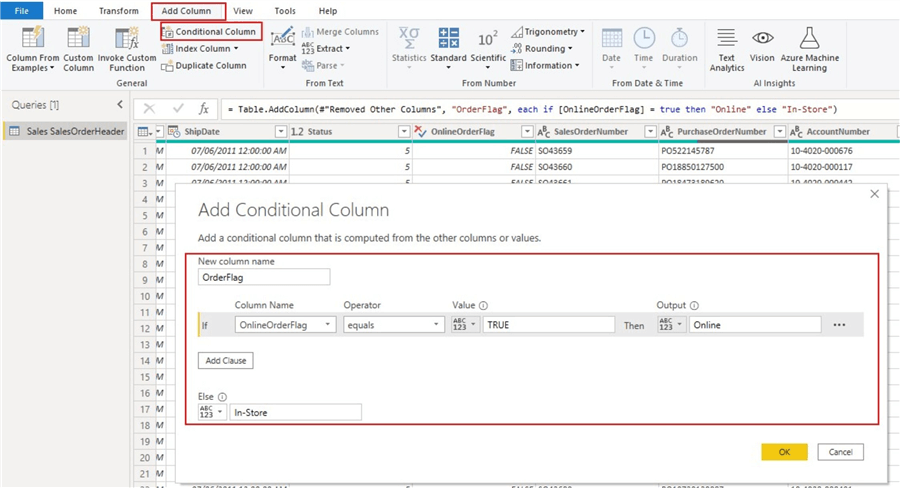
可以在下面看到新的计算列“ OrderFlag”。
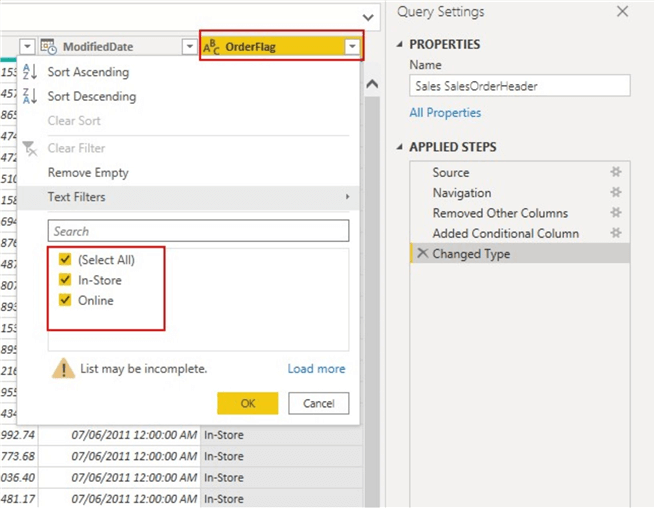
其次,我们可以在Power BI Desktop的DAX计算列中执行相同的操作,如下图所示。
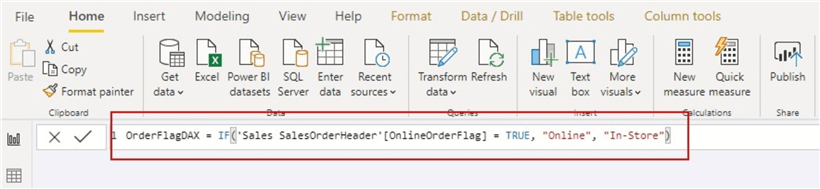
可以在下面看到新的计算列“ OrderFlagDAX”。
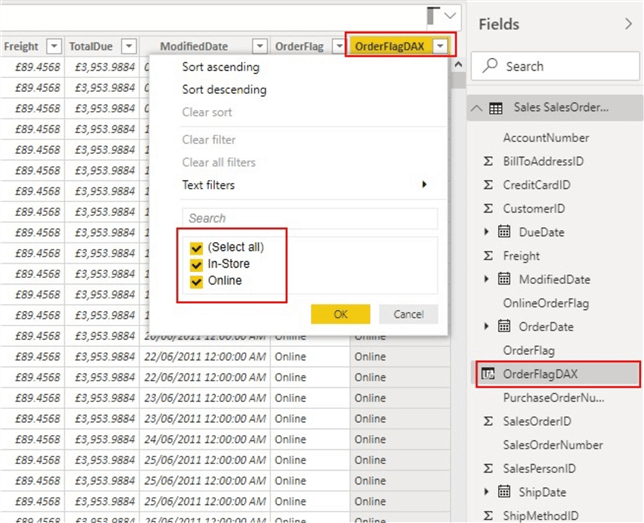
接下来,我分别为在Power Query和DAX中创建的列创建了两个Slicer视觉效果,以便我们可以比较并查看刷新后的性能。请注意,这是一个较小的模型,请想象一下对较大数据模型的影响。为了进行比较,我利用了Power BI桌面中的 Performance Analyzer,如下所示。
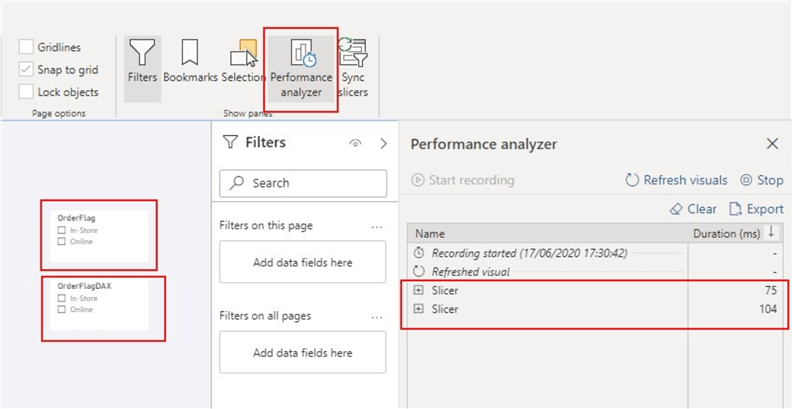
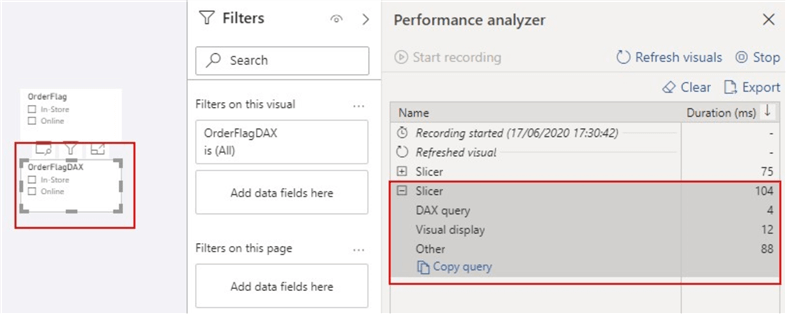
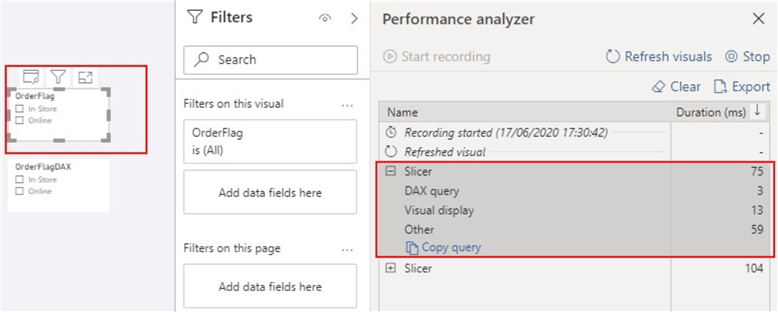
如下图所示,“ OrderFlag”大约花费75毫秒来刷新,而“ OrderFlagDAX”大约花费104毫秒来刷新。下图将显示这不是由于DAX查询的执行,而是由于切片器可视化程序用于准备查询,等待其他可视化程序完成或执行其他后台处理所需的时间。这就是效率发挥作用的地方。
在第2部分中,我们将研究禁用“自动日期/时间”和实现 水平过滤如何有助于提高性能并减少Power BI开发中的低效率。