本章对元数据及其构造方式进行了概述。也还描述了元数据验证。后面的章节将会分析单独的元数据项——基于这里所表示的基础。我理解你可能的急躁——“这个家伙不要拖延时间,什么时候才能进入正题?”——但是我仍然奉劝你不要跳过本章。远远不是拖时,我只是系统地接近这个对象。这看上去可能是一样的,但是动机是完全不同的,而这正是我所关心的。
什么是元数据?
元数据的定义:描述数据的数据。然而,就像每个通常的定义一样,这个定义并没有丰富的信息。在CLR的上下文中,元数据表示由描述符组成的一套体系,这些操作符包括了在一个模块中被声明或引用的所有项。由于CLR模型天生就是面向对象的,因此在元数据中描述的项是类和它们的成员,以及它们伴随着的特性、属性和关联。
译注:这里的关联,举例而言,如继承。
从实用的观点看,元数据所扮演的角色类似于COM世界中的类库所扮演的角色。可是,在这个普通的级别上,这些类似之处只有这些,接下来则是不同点。元数据,从细枝末节上描述了模块或程序集的结构化方面,比由类库提供的数据要极大的丰富,这些类库只携带了将COM接口视为由模块所暴露的信息。重要的区别是,元数据是一个托管模块的完整部分,这意味着每个托管模块总是携带着一个关于它的逻辑结构的完全的、高级别的、正式的描述。
从结构上说,元数据是一个正规的关系型数据库。这意味着元数据被组织为一组交叉引用的二维表——而不是,例如,一个带有一棵树状结构的层联级数据库。元数据表的每一列包括了数据或者指向另一个表中的一行的引用。元数据并不包括任何重复的数据字段,数据的每个类别都只位于元数据的数据库的一个表中。如果另一个表也需要使用这个相同的数据,它将引用保存着这个数据的表。
例如,正如第一章所述,一个类定义携带了特定的二进制特性(标记)。这个类的方法的行为和特性受这个类的标记影响,因此,在一条描述了其中一个方法的元数据记录中,复制这个类的一些特性,包括标记,是非常诱人的。但是数据定义不仅导致数据库大小的增长,也会导致保持这些复制体相容的问题。
替代的,方法描述符按照这样的方式存储:父类总是能从一个给定的方法描述符中被发现。这种参考方案确实需要一定数量的搜索,而这是非常昂贵的,如果不是这种典型的基于.NET的应用程序,处理器的速度也不会是一个问题——包括通信带宽和数据完整性。
如果这样的布局对你而言看起来并不是那么有效,想一想如果你是运行时的类加载器,你通常将如何访问元数据。作为一个类加载器,你会想加载一个完整的类,包括它的所有方法、字段和其它成员。而且,正如我之前谈到的,这个类的描述符(记录)携带了指向这个方法表的记录的一个引用,这个方法表表示了这个类的第一个方法。属于这个类的方法记录的末端是定义在下一个类的方法记录的开始部分,或者(对于最后一个类)是定义在这个方法表的末端。对于字段数据也是这样的。
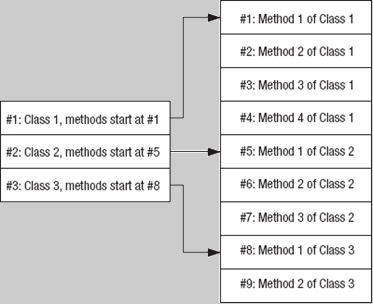
显然,这种技术需要方法表中的记录存储在它们的父类中。这同样应用于其它表映射到表的关系(类映射到字段,方法映射到参数等等)。如果这种需求被满足,元数据就被认为“优化的”(optimized)或“压缩的”(compressed)。图5-1显示了这样的元数据的一个示例。ILAsm编译器总是生成优化的元数据。
图5-1 优化的元数据的一个示例
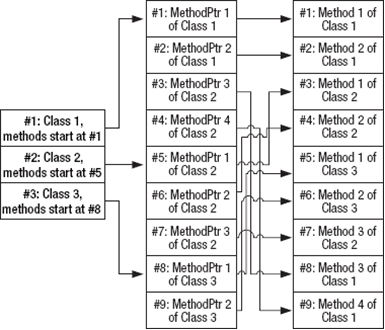
然而,臃肿的元数据发布或可增长的编译,导致了这样的结果:将这些子表插入到它们所拥有的类中是可能的。例如,类记录A可能被首先发布,紧跟其后的是类记录B,类B的方法记录,然后是类A的方法记录;或者这个顺序可能是类记录A,然后是类A的一些方法记录,紧跟其后的是类记录B,类B的方法记录,然后是类A的剩余的方法记录。
在这种情形中,额外的中间元数据表会被预定,提供了非插入式的检索表,这些表按照它拥有的类进行排序。取代以引用这些方法记录,类的记录引用了一个中间表(指针表)的记录,而且这些记录依次引用了这些方法记录,正如图5-2中列出的表格。使用了这种中间检索表的元数据被称为未优化的或未压缩的。
两种场景经常导致发布非压缩的元数据结构:“编辑和继续”场景,当一个模块被加载到内存的时候,该模块的元数据和IL代码会在这种场景中被修改,而另一种是增长的编译场景,元数据和IL代码在“安装”时被修改。
图5-1 一个未优化的元数据的例子