堆和表
从逻辑上讲,元数据被表示为一组有名称的流,附带着每个流表示一类的数据。这些流被分为两种类型:元数据堆和元数据表。
String堆:这种类型的堆包括了0休止符字符的字符串,以UTF-8格式编码。这些字符串直接首尾相接。这个堆的第一个字节总是为0,而且这导致了堆中的第一个字符串总是为空字符串的结果。这个堆的最后一个字节也必须是0(换句话说,堆中的最后一个字符串,就像其它的一样,必须是0休止符)。
GUID堆:这种类型的堆包括了一些16位的二进制对象,它们是直接首尾相接。这些二进制对象的大小是固定的,因此长度参数和休止符是不需要的。
Blob堆:这种类型的堆包括了一些任意大小的二进制对象。每个二进制对象都以它的长度(以压缩的形式)作为开始。这些二进制对象在4位的边界上对齐。
长度压缩公式是相当简单的。如果这个长度(一个无符号的整数)是0x7F或者更少,它就被表示为一个1个字节;如果长度大于0x7F但是不大于0x3FFF,它就被表示为一个2位的无符号的整数,带有一个最重要的位设置。否则,它就被表示为一个4位的无符号的整数,带有两个最重要的位设置。表5-1总结了这个公式。
表5-1 Blob的长度压缩公式
|
取值范围 |
压缩大小 |
压缩值(Big Endian) |
|
0-0x7F |
1字节 |
<value> |
|
0x80-0x3FF |
2字节 |
0x8000|<value> |
|
0x4000-0x1FFFFFFF |
4字节 |
0xC0000000|<value> |
这个压缩公式在元数据中广泛应用。当然,这种压缩只工作于不超过0x1FFFFFFF(536870911)的长度数量,但是这种限制并不是一个问题,因为压缩总是应用于像长度和数量这样的值。
通用元数据头
通用元数据头由一个存储签名和一个存储头组成。存储签名是按4位排列的,有如表5-2所描述的结构。
图5-2 元数据存储签名的结构
|
类型 |
字段 |
描述 |
|
DWORD |
lSignature |
物理元数据的“魔术”签名,当前是0x424A5342,或者,被当作BSJB这些字符——4位“founding father”(创立人)Brian Harry、Susan Radke-Sproull、Jason Zander和Bill Evans的首大写字母(我最好称其为“founding”,Susan可能会反对被称为father),他们在1998年开始了运行时的开发工作。 |
|
WORD |
iMajorVer |
主版本(1) |
|
WORD |
iMinorVer |
次版本(1) |
|
DWORD |
iExtraData |
保留的;设置为0 |
|
DWORD |
iVersionString |
版本字符串的长度 |
|
BYTE[] |
pVersion |
版本字符串 |
存储头紧跟在存储签名之后,被排列在4位的边界上。它的结构是简单的,正如表5-3所示:
图5-3 元数据存储头的结构
|
类型 |
字段 |
描述 |
|
BYTE |
iFlags |
保留的;设置为0 |
|
BYTE |
|
[padding] |
|
WORD |
iStream |
流的数量 |
紧跟在存储头之后的是一个流的头的数组。表5-4描述了一个流的头的结构。
图5-4 元数据流的头的结构
|
类型 |
字段 |
描述 |
|
DWORD |
iOffset |
对于这个流在文件中的偏移量。 |
|
DWORD |
iSize |
流的字节大小。 |
|
char[32] |
rcName |
流的名称;一个以0作为休止符的不大于31个字符(包括0休止符)的ASCII字符串。这个名称可能比较短,在这种情形中,这个流的头的大小会被相应的减少,padded to 4位的边界。 |
有六种指定名称的流出现在元数据中:
#Strings:一个包括了元数据项的字符串堆(类名、方法名,字段名等等)。这个流并不包括在模块的方法中定义或引用的文字常量。
#blob:一个blob堆包括了内部的元数据二进制对象,比如说默认值、签名等。
#GUID:一个GUID堆包括了所有类别的全局的唯一标识符。
#US:一个blob堆包括了用户自定义的字符串。这个流包括了定义在用户代码中的字符串常量。这些字符串以UTD-16的编码格式保存,附带着额外的一个尾部设置为0或1的字节,用以指出在字符串中是否有大于0x007F的代码字符。这个尾部字节被添加到流线上的在由用户定义的字符串常量生成的字符串对象上的代码转换操作。这个流的最有趣的特征是,这个用户字符串不仅会被任意元数据表引用到,还会显示地被IL代码表明地址(使用ldstr指令)。此外,作为一个实际上的blob堆,US堆不仅可以存储Unicode字符串,还可以存储任意二进制对象,这使那些有趣的实现成为可能。
#~:一个压缩的(优化的)元数据流。这个流包括了一个优化的由元数据表组成的体系。
#-:一个未压缩的(未优化的)元数据流。这个流包括了一个未优化的由元数据表组成的体系,它包括了至少一个直接的搜索表(指针表)。
#~和#-流是互斥的——就是说,这个模块的元数据结构是优化的或者未优化的;而不可以在同一时间共存或者在其二者中间的另一个值。如果在流中没有存储任何项,这个流就是无效的,存储头的iStream字段会相应的减少。至少有三个流被确保是存在的:元数据流(#~或#-流),字符串流(#Strings),GUID流(#GUID)。元数据项必须至少存在于一个最小程度的配置中,即使是位于一个最不重要的模块中,并且这些元数据项必须具有名称和GUID。
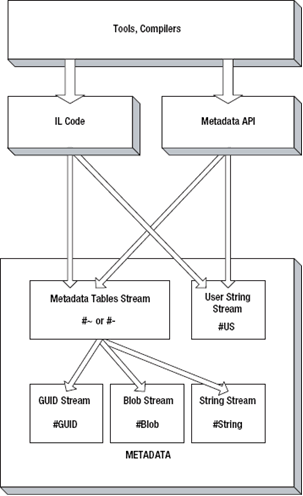
图5-3解释了元数据的通用结构。在图5-4中,你可以看到流陂其它流引用的方式,如同被外部的“消费者”引用一样,例如元数据API和IL代码。
图5-3 元数据的通用结构
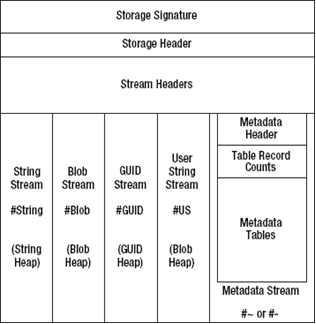
图5-4 流的引用
元数据表流
元数据流#~和#-开始于在表5-5中描述的头。
表5-5 元数据表流的头结构
|
大小 |
字段 |
描述 |
|
4字节 |
Reserved |
保留的;设置为0 |
|
1字节 |
Major |
表格式的主版本(对于1.0和1.1版本是1;对于2.0版本是2) |
|
1字节 |
Minor |
表格式的次版本(对于所有版本都是0)。 |
|
1字节 |
Heaps |
二进制标记,指出了在堆中使用的偏移量的大小。0x01用来表示字符串堆中的一个4字节无符号整数偏移量,0x02表示GUID堆,0x04表示blob堆。如果没有设置这个标记,相应的堆偏移量是一个2字节无符号整数。Stream流也可以有一个特殊的标记设置:0x02标记,指出了这个流只包括在“编辑并继续”会话期间发生的改变;而0x80标记,指出了元数据可能包括了标记为删除的项。 |
|
1字节 |
Rid |
元数据的所有表的最大记录索引的位宽;在运行期计算(在元数据流初始化期间)。 |
|
8字节 |
MaskValid |
由存在表组成的位向量,每一位表示一个相应的表(如果存在则为1)。 |
|
8字节 |
Sorted |
由分类表组成的位向量,每一位表示一个相应的表(如果分类则为1)。 |
紧跟在这个头后面的是一个顺序排列的4字节无符号整数,指出了在每个表中的MaskValid位相量上标记为1的记录数量。
像其它数据库一样,元数据有一个schema。这个schema是一个由元数据的表和列的描述符组成的体系——就这种意义来说,它是“元数据的元数据”。Schema不是元数据的一部分,也不是托管PE文件的特性;而是CLR的一个特性并且是硬编码的。它不会发生改变只有在对运行时的主版本的彻底检查并且即使在它增长性改变时(正如它在CLR的1.0和2.0版本中改变),通过添加新表并保留那些旧的没有改变的表。
每个元数据表都有一个描述在表5-6中的结构的描述符。
表5-6 元数据表描述符的结构
|
类型 |
字段 |
描述 |
|
pointer |
pColDefs |
指向一个由列描述符组成的数组的指针 |
|
BYTE |
cCols |
表中列的数量 |
|
BYTE |
iKey |
关键列的索引 |
|
WORD |
cbRec |
表中一个记录的大小 |
列描述符,也就是表描述符的pColDefs字段所指向的,具有在表5-7中描述的结构。
表5-7 元数据表的列描述符的结构
|
类型 |
字段 |
描述 |
|
BYTE |
Type |
这列代码的类型 |
|
BYTE |
oColumn |
列的偏移量 |
|
BYTE |
cbColumn |
列的字节大小 |
类型,列描述符的第一个字段,是尤其有趣的。CLR现有的发布版本中的元数据schema识别了在表5-8中描述的列的类型的编码。
表5-8 元数据表的列的类型编码
|
编码 |
描述 |
|
0-63 |
这个列保存了在另一个表中的记录索引值(RID);这个特定的编码值指出了是哪一个表。在这个列只是引用来自一个表中的记录时,RID被用作列的类型。这个列的宽度定义在元数据流头的Rid字段中。 |
|
64-95 |
这个列保存了指向另一个表的编码符号;这个特定的编码值指出了该编码符号的类型。符号是一些引用,携带着表和被引用的记录的索引。在这个列引用来自多于一个表中的记录时,符号被用作列的类型。被寻址的表和记录的索引都由编码符号值来定义。 |
|
96 |
这个列保存了一个2字节的有符号整数。 |
|
97 |
这个列保存了一个2字节的无符号整数。 |
|
98 |
这个列保存了一个4字节的有符号整数。 |
|
99 |
这个列保存了一个4字节的无符号整数。 |
|
100 |
这个列保存了一个1字节的无符号整数。 |
|
101 |
这个列保存了在字符串堆中的偏移量(#Strings流)。 |
|
102 |
这个列保存了在GUID堆中的偏移量(#GUID流)。 |
|
103 |
这个列保存了在blob堆中的偏移量(#Blob流)。 |
元数据的schema定义了45个表。一旦给定RID类型编码的范围,CLR就会有明确的增长空间。此刻,下面的表就会被定义:
[0]Module:当前模块的描述符。
[1]TypeRef:引用类的描述符。
[2]TypeDef:类或接口定义的描述符。
[3]FieldPtr:一个从类映射到字段的搜索表,该表在优化过的元数据(#~流)中并不存在。
[4]Field:字段定义的描述符。
[5]MethodPtr:一个从类映射到方法的搜索表,该表在优化过的元数据(#~流)中并不存在。
[6]Method:方法定义的描述符。
[7]ParamPtr:一个从方法映射到参数的搜索表,该表在优化过的元数据(#~流)中并不存在。
[8]Param:参数定义的描述符。
[9]InterfaceImpl:接口定义的描述符。
[10]MemberRef:成员(字段或方法)引用描述符。
[11]Constant:常量值的描述符,将存储在#Blog流中的默认值映射到相应的字段、参数和属性。
[12]CustomAttribute:自定义特性的描述符。
[13]FieldMarshal:用于托管/非托管互操作的字段或参数分组的描述符。
[14]DeclSecurity:安全描述符。
[15]ClassLayout:类布局的描述符,保存关于加载器应该如何展开相应的类的信息。
[16]FieldLayout:字段布局的描述符,详细指出了独立字段的偏移量和序数。
[17]StandAloneSig:独立的签名的描述符。签名本质上用于两种场合中:作为本地的方法变量的混合签名,以及作为间接(calli)调用IL指令的参数
[18]EventMap:一个类映射到事件的表。这不是一个直接搜索表,并确实存在于优化的元数据中。
[19]EventPtr:一个由事件的MAP映射到事件的搜索表,它不存在于优化的元数据中(#~流)。
注:MAP,由LINK工具生成的一种文本文件,其中包含有被连接的程序的某些信息,例如程序中的组信息和公共符号信息等。
[20]Event:事件描述符。
[21]PropertyMap:一个由类映射到属性的表。这不是一个直接搜索表,并确实存在于优化的元数据中。
[22]PropertyPtr:一个由属性的MAP映射到属性的搜索表,它不存在于优化的元数据中(#~流)。
[23]Property:属性描述符。
[24]MethodSemantics:方法的语义描述符,保存了关于哪个方法关联着一个特定的属性或事件以及在相应的什么场合。
[25]MethodImpl:方法实现的描述符。
[26]ModuleRef:模块引用的描述符。
[27]TypeSpec:类型规范的描述符。
[28]ImplMap:实现映射的描述符,用于由托管/非托管代码互操作组成的P/Invoke类型。
[29]FieldRVA:字段映射到数据的描述符。
[30]ENCLog:Edit-and-Continue日志的描述符,保存了关于在内存编辑期间对特定的元数据项作了哪些修改的信息。这个表不存在于优化的元数据(#~流)中。
[31]ENCMap:Edit-and-Continue映射的描述符。这个表不存在于优化的元数据(#~流)中。
[32]Asssembly:当前编译集的描述符,只能出现在主模块的元数据(#~流)中。
[33] AssemblyProcessor:这个表没有使用到。
[34]AssemblyOS:这个表没有使用到。
[35]AssemblyRef:编译集引用的描述符。
[36]AssemblyRefProcessor:这个表没有使用到。
[37]AssemblyRefOS:这个表没有使用到。
[38]File:文件的描述符,包括了关于当前编译集中其它文件的信息。
[39]ExportedType:输出类型的描述符,包括了关于被当前编译集输出的公共类的信息,这将在这个编译集的其他模块中声明。只有编译集的主模块应该携带这个表。
[40]ManifestResource:托管资源的描述符。
[41]NestedClass:嵌套类的描述符,提供了从嵌套类到它们相应的密闭类的映射。
[42]GenericParam:类型参数的描述符,用于泛型(参数化的)类和方法。
[43]MethodSpec:泛型方法实例化的描述符。
[44]GenericParamConstraint:由特定约束组成的描述符,用于泛型类和方法的类型参数。
最后三个表是在CLR2.0版本中新添加的。它们在1.0和1.1版本中并不存在。
我将在后面的章节讨论各种表及其验证规则的结构化方面,伴随着相应的ILAsm的构造器。