本章深入到可执行文件的内部,进而探索元数据的概念。
a.cs
using System; using System.IO; public class zzz { public static void Main() { zzz a = new zzz(); a.abc(); } public void abc() { FileStream s = new FileStream("C:\\mdata\\b.exe", FileMode.Open); BinaryReader r = new BinaryReader(s); s.Seek(128 + 4 + 20 + 208, SeekOrigin.Begin); int rva, size; rva = r.ReadInt32(); size = r.ReadInt32(); int where = rva % 0x2000 + 512; s.Seek(where + 4 + 4, SeekOrigin.Begin); rva = r.ReadInt32(); where = rva % 0x2000 + 512; s.Seek(where, SeekOrigin.Begin); byte a, b, c, d; a = r.ReadByte(); b = r.ReadByte(); c = r.ReadByte(); d = r.ReadByte(); Console.WriteLine("{0}{1}{2}{3}", (char)a, (char)b, (char)c, (char)d); int major = r.ReadInt16(); Console.WriteLine("Major Version {0}", major); int minor = r.ReadInt16(); Console.WriteLine("Minor Version {0}", minor); int reserved = r.ReadInt32(); Console.WriteLine("Reserved {0}", reserved); int len = r.ReadInt32(); Console.WriteLine("Length of string {0}", len); for (int i = 1; i <= len; i++) { byte e = r.ReadByte(); Console.Write("{0}", (char)e); } Console.WriteLine(); int leftover = len % 4; Console.WriteLine("Four Byte boundary {0}", leftover); for (int i = 1; i <= leftover; i++) s.Seek(1, SeekOrigin.Current); int flags = r.ReadInt16(); Console.WriteLine("Flags {0}", flags); } }
Output:
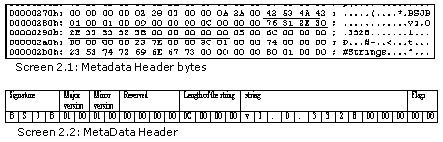
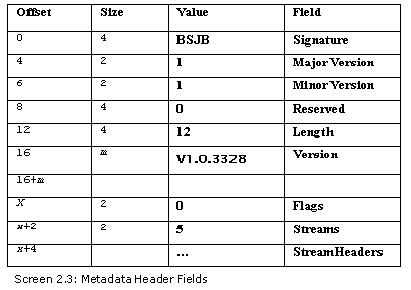
BSJB
Major Version 1
Minor Version 1
Reserved 0
Length of string 12
v1.0.3328
Four Byte boundary 0
Flags 0
程序直接开始于15个数据目录项之后,也就是CLR头开始的地方。在提取出文件中的地址后,我们到达这个位置。在这个位置后的8个字节用于表示元数据的另一个数据目录项。我们使用前面的方法跳转到磁盘上元数据的开始位置。
元数据头的开始4个字节包括另一个魔数:BSJB,这是由建立元数据标准的4个人的名字的首字母组成的。J代表Jim Hess。正如你即将看到的那样,元数据的结构是一门很不错的艺术。
随后我们遇到的是元数据的主版本和次版本,分别是1和0。文档清楚规定——这些值目前不再使用了。紧跟着的是一个整数,它被标记为保留的。之后是另一个整数,它指定了后面的字符串的长度。
字符串长度被指定为12,这表示下面12个字节包括了一个字符串值。显然,值v1.0.3328就是通过这12个字节来表示的。
在命令提示符中,指定下面的命令:
Output:
c:\mdata>csc
Microsoft (R) Visual C# .NET Compiler version 7.00.9372.1
for Microsoft (R) .NET Framework version 1.0.3328
Copyright (C) Microsoft Corporation 2001. All rights reserved.
注意到.NET框架的版本对应到字符串的值。为了到达下一个字节,我们不得不克服当前32位机器所面对的障碍。按照这类机器的说明手册,所有内容都是在4字节边界上对齐的。
因此,在将长度除以4之后得到的余数,就是向前移动的字节数量。在元数据的世界里,4字节边界上的对齐仍然流行。在我们的示例中,由于字符串的长度为12,所以就不需要进行填充了。最后,我们会遇到一个标志字段,它的值为0。
从上面的表格中,看上去好像最后两个字段是由我们生成的。然而,并不是这样的。我们认识到,一个单独的程序对于分析流字段是至关重要的。因此,我们合并下面的描述流实体的程序。
a.cs
using System; using System.IO; public class zzz { public static void Main() { zzz a = new zzz(); a.abc(); } public void abc() { long startofmetadata; FileStream s = new FileStream("C:\\mdata\\b.exe", FileMode.Open); BinaryReader r = new BinaryReader(s); s.Seek(128 + 4 + 20 + 208, SeekOrigin.Begin); int rva, size; rva = r.ReadInt32(); size = r.ReadInt32(); int clihdr = rva % 0x2000 + 512; Console.WriteLine("clihdr on disk: " + clihdr); s.Seek(clihdr + 4 + 4, SeekOrigin.Begin); rva = r.ReadInt32(); clihdr = rva % 0x2000 + 512; s.Seek(clihdr, SeekOrigin.Begin); startofmetadata = s.Position; Console.WriteLine("Start of Metadata on disk : " + startofmetadata); s.Seek(4 + 2 + 2 + 4 + 4 + 12 + 2, SeekOrigin.Current); int streams = r.ReadInt16(); Console.WriteLine("No of Streams {0}", streams); int[] offset = new int[streams]; int[] ssize = new int[streams]; int i = 0; for (i = 0; i < streams; i++) { offset[i] = r.ReadInt32(); ssize[i] = r.ReadInt32(); Console.Write("Offset {0} Size {1} ", offset[i], ssize[i]); while (true) { byte b = r.ReadByte(); if (b == 0) break; Console.Write("{0}", (char)b); } Console.WriteLine(); while (true) { if (s.Position % 4 == 0) break; byte b = r.ReadByte(); if (b != 0) { s.Seek(-1, SeekOrigin.Current); break; } } } } }
Output
clihdr on disk: 520
Start of Metadata on disk : 636
No of Streams 5
Offset 108 Size 208 #~
Offset 316 Size 116 #Strings
Offset 432 Size 12 #US
Offset 444 Size 16 #GUID
Offset 460 Size 36 #Blob
这个程序是前面那个程序的升级版。文件中元数据的开始位置存储在一个变量中,并恰当地命名为startofmetadata。这个变量在下一个程序中被广泛使用。变量值只是为了便利和验证。
在到达文件中的元数据之后,元数据头中的下面30个字节就会被访问到。它们的细节已经在前面的程序中显示出来了。
按照顺序,下面两个字节包括了在元数据中出现的流的数量。最多总是有5个流。
元数据世界中的任何内容都存储在流中。这是我们在检索元数据信息时要处理的基本实体。在这些包括了流的数量的字段之后,是流头(stream header)。

流头附着在一个特定的模式上。由于这里有总共5个流,所以也就存在5个流头。流头由偏移量、大小和流名称组成。偏移量与元数据位置有关。大小总是4的倍数,与对齐问题保持一致,并且它则指定了在磁盘上流数据的大小。最后是名称,它是以null终止的。然而,需要填充字节来满足对齐中的复杂性。
为了存储偏移量和大小,需要为每个流创建两个整型数组。
取决于存储在流中的值,创建一个数组来存储偏移量和大小。在相应的数组中分别读取4个字节的偏移量和大小。从而,每个字节都会被读取到,直到遇到一个null或0值。同时,每个字节以ASCII格式显示。在成功读取到流后,4字节对齐也已经考虑在内了。
元数据世界的底层规范是为效率而设计的,而不是为了直接理解。因此,为了维护效率,使用0来填充字符串。
在我们进一步缩小范围以显示存储在这些字符串偏移量上的数据之前,我们需要知道位移位操作的概念。
a.cs
using System; public class zzz { public static void Main() { Console.WriteLine(3 >> 1); Console.WriteLine(8 >> 2); Console.WriteLine(9 >> 3); } }
Output
1
2
1

数字3开始的两位为on。>>是右移位。因此,使用>>1,所以的位向右移动1位,结果是第1位被“挤出”边界,而第2位变成了第1位,以此类推。在最左边被分配了一个新值0。从而,最后结果为1。
在第二个例子中,数字8的第4位为on。通过右移2位,所有的位都被移动了2次,结果为一个新的值2。在第三个例子中重复了同样的过程,这里第4位和第1位是on。第1位被“挤出”边界,而第4位变成了第1位。
与之相反的操作是左移操作,这里操作符使用了<<。在左移的过程中,最右边的位被“挤出”,而在最右边的新引进的位上填充0值。
右移操作的结果就是除法运算。从而,右移2位的结果就是除以4,等等以此类推。这与左移是相反的,后者其实就是乘法。
a.cs
using System; using System.IO; public class zzz { public static void Main() { zzz a = new zzz(); a.abc(); } int[] offset; int[] ssize; byte[] metadata; byte[] strings; byte[] us; byte[] guid; byte[] blob; long valid, sorted; int nooftables; byte[][] names; public void abc() { long startofmetadata; FileStream s = new FileStream("C:\\mdata\\b.exe", FileMode.Open); BinaryReader r = new BinaryReader(s); s.Seek(360, SeekOrigin.Begin); int rva, size; rva = r.ReadInt32(); size = r.ReadInt32(); int where = rva % 0x2000 + 512; s.Seek(where + 4 + 4, SeekOrigin.Begin); rva = r.ReadInt32(); where = rva % 0x2000 + 512; s.Seek(where, SeekOrigin.Begin); startofmetadata = s.Position; s.Seek(4 + 2 + 2 + 4 + 4 + 12 + 2, SeekOrigin.Current); int streams = r.ReadInt16(); offset = new int[5]; ssize = new int[5]; names = new byte[5][]; names[0] = new byte[10]; names[1] = new byte[10]; names[2] = new byte[10]; names[3] = new byte[10]; names[4] = new byte[10]; int i = 0; int j; for (i = 0; i < streams; i++) { offset[i] = r.ReadInt32(); ssize[i] = r.ReadInt32(); j = 0; byte bb; while (true) { bb = r.ReadByte(); if (bb == 0) break; names[i][j] = bb; j++; } names[i][j] = bb; while (true) { if (s.Position % 4 == 0) break; byte b = r.ReadByte(); if (b != 0) { s.Seek(-1, SeekOrigin.Current); break; } } } for (i = 0; i < streams; i++) { Console.Write("Offset {0} Size {1} ", offset[i], ssize[i]); j = 0; while (true) { if (names[i][j] == 0) break; Console.Write("{0}", (char)names[i][j]); j++; } Console.WriteLine(); } for (i = 0; i < streams; i++) { if (names[i][1] == '~') { metadata = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) metadata[k] = r.ReadByte(); } if (names[i][1] == 'S') { strings = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) strings[k] = r.ReadByte(); } if (names[i][1] == 'U') { us = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) us[k] = r.ReadByte(); } if (names[i][1] == 'G') { guid = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) guid[k] = r.ReadByte(); } if (names[i][1] == 'B') { blob = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) blob[k] = r.ReadByte(); } } int reserved = BitConverter.ToInt32(metadata, 0); Console.WriteLine("Reserved {0}", reserved); Console.WriteLine("Major Table Verison {0}", metadata[4]); Console.WriteLine("Minor Table Verison {0}", metadata[5]); Console.WriteLine("Heap Sizes {0}", metadata[6]); Console.WriteLine("Reserved {0}", metadata[7]); valid = BitConverter.ToInt64(metadata, 8); Console.WriteLine("Tables Bit Vector {0}", valid.ToString("X")); nooftables = 0; for (int k = 0; k <= 63; k++) { nooftables += (int)(valid >> k) & 1; } Console.WriteLine("No of Tables {0}", nooftables); sorted = BitConverter.ToInt64(metadata, 16); Console.WriteLine("Sorted Tables Bit Vector {0}", sorted.ToString("X")); } }
Output:
Offset 108 Size 208 #~
Offset 316 Size 116 #Strings
Offset 432 Size 12 #US
Offset 444 Size 16 #GUID
Offset 460 Size 36 #Blob
Reserved 0
Major Table Verison 1
Minor Table Verison 0
Heap Sizes 0
Reserved 1
Tables Bit Vector 900001447
No of Tables 8
Sorted Tables Bit Vector 2003301FA00
上面的程序是了解元数据内部的“旅程”的开始。在元数据头中定位文件指针后,我们把流的名称存储在一个数组中。在前面的程序中,我们只显示了名称字段中的每个字节。
为了存储这些名称,需要创建一个很大的由数组组成的数组,其中每个子数组都保存一个字符串。由于有5个流,所以要创建5个子数组。除此之外,还要分配子数组的大小为10,因为我们知道不存在超过10个流名称的情形。
就像前面那样,在for循环中,为每个流读取偏移量和大小,并且它们被放置在它们相应的数组位置上。变量j用于索引内部的数组,而变量i用于索引外部的数组。在退出第一个while循环时,名称数组是以null终结的——只是为了方便打印。因此,对前面程序的第一个增强就是,所有的流名称都被放入一个数组中。
为了验证我们的操作,每个流的大小、偏移量和名称都会被打印出来。名称数组是使用while循环来显示的,当它遇到一个0值时会终止。这就解释了程序的上半部分。
程序的下半部分处理了5个流的数据。我们选择在5个独立的数组中存储5个流的数据。这不仅加速了这个程序的执行过程,还容易理解。这些规则适用于从数组的一个流中读取数据,对于从所有其它流中读取数据都是相同的。
这里,实例变量用于创建数组,因此允许访问所有的函数。这5个实例变量是元数据~、string、US、GUID和BLOB。然后,使用for循环迭代5次,由5个if语句组成。每个流名称的第2个字节用来检查一个特定的字符。第1个字节被忽略,因为所有的流名称会在第1个字节中存储一个#字符。虽然我们已经比较了整个字符串,但是此刻,我们打算使之更加简单容易。因此,我们采用了这个方法。
如果第2个字节是~,表明这个流存储了元数据表的细节。稍后我们将解释这一点。相应的大小数组存储了流的大小,它决定了数组的大小。相应的偏移量数组具有一个值,它指向流数据的开始位置,作为一个距离元数据头的开始位置的偏移量。元数据头的开始位置存储在名为startofmetadata的变量中。
因此,文件指针初始定位在这个流数据的开始位置,而后在这个偏移量变量上重新定位。既然我们定位在流数据的开始位置,我们使用for循环来填充元数据数组。
我们利用ReadByte函数每次读取一个单独的字节,作为替代,我们可以使用ReadBytes函数。ReadBytes函数从当前流中读取一个特定数量的字节到一个字节数组中,然后立即跳转当前文件指针位置到这些字节之前。使用同样的机制,其它4个数组也是如此填充的。结果是,5个数组都会被组成元数据流的数据填充。最必要的流是#~流。因此,让我们详细分析它的格式。

用于#~流的数据开始于4个保留字节。从而,它们的值都是0。
我们使用到了BinaryReader类和BitConverter类的方法。当BinaryReader类每次读取多个字节时,BitConverter类就将被提取的字节转换为一个合适的类型。BitConverter类的静态方法ToInt32获取两个参数,即字节数组和偏移量。它从数组中的偏移量中得到32位并将它们转换为一个32位或一个4字节的整数值。
提供给这个函数的参数是数组metadata和偏移量0。
值0表示这个函数必须读取开始的4个字节。在一个数组的情形中,计数从0开始而不是1。文档规定,这个保留的字段应该总是为0。
之后的2个字节包括了表结构的主版本号和次版本号。到现在为止,主版本号是1,次版本号是0。由于它们是简单的字节,所以我们从数组本身中直接读取到它们。没有必要实现BitConverter类的任何方法。
下一个字节涉及了堆的大小,稍后会进行介绍。在堆的大小之后,是一个保留字节,值为1。在保留字节之后的8个字节(一个长整数),包括了现有表的编号的数量。
如今,你可能对常常遇到术语“表”(table)而没有任何附加其上的解释而感到十分不爽。不要再生闷气了,朋友。我们会为你提供解释并揭开它的神秘面纱。
所有的元数据都是以表的形式内部存储的。在元数据的领域中有43种表的类型。所有类或类型都存储在一个表中,而所有的方法都存储在另一个表中,以此类推。每个表都在表字段中分配了1个位。视这个位字段的状态而定,就可以确定一个特定表的存在。进一步而言,文件中存在的表的数量,依赖于被切换成on的位的数量。
当现在为止,表中最大的位是0x2b,也就是43。然而,其中一些位从来也没有用到,而另一些位又并不能存储任何信息。
在我们探究全部范围的表之前,让我们首先计算一下存在于文件中的表的数量。使用一个for循环直到结束,它重复执行代码64次。从而,变量k被分配0到63的值。所有的位都右移k次,然而,执行和值1的AND位运算。
我们在更深层次上再次说明下面的语句:
nooftables += (int)(valid >> k ) & 1;
变量k在for循环的第一次迭代中为0。因此,该语句对valid >> k进行判断。右移0位表示在字段中的位不发生任何改变。和1的AND运算将检查最右边的位是否包括值1。最后的结果将会是1或0。因此,1或0都将被添加到变量nooftables上。
在循环的第二次迭代中,当变量k的值为1时,相应的语句为:
nooftables += (int)(valid >> 1 ) & 1;
从而,字段中所有的位都会被向右移动1位。这样做的结果是,第1位被丢弃,而第2位变成第1位。如果这个位是on,获得的结果就是1,而变量nooftables增加1。
在下一轮,该语句变成:
nooftables += (int)(valid >> 2 ) & 1;
因此,按照这样,在valid字段中的每个位都会被确认,以决定是否它包括值1。
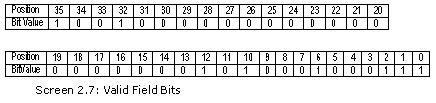
valid字段是一个位向量,它有8个位是on。因此,最终会为这个最小的exe文件创建8个表。变量nooftables确证了这个值。表字段之后是一个称为sorted表位向量的长整数。稍后我们将关注这个字段。
a.cs
using System; using System.IO; public class zzz { public static void Main() { zzz a = new zzz(); a.abc(); } string[] tablenames; int tableoffset; int[] rows; int[] offset; int[] ssize; byte[] metadata; byte[] strings; byte[] us; byte[] guid; byte[] blob; long valid, sorted; int nooftables; byte[][] names; public void abc() { long startofmetadata; FileStream s = new FileStream("C:\\mdata\\b.exe", FileMode.Open); BinaryReader r = new BinaryReader(s); s.Seek(360, SeekOrigin.Begin); int rva, size; rva = r.ReadInt32(); size = r.ReadInt32(); int where = rva % 0x2000 + 512; s.Seek(where + 4 + 4, SeekOrigin.Begin); rva = r.ReadInt32(); where = rva % 0x2000 + 512; s.Seek(where, SeekOrigin.Begin); startofmetadata = s.Position; s.Seek(4 + 2 + 2 + 4 + 4 + 12 + 2, SeekOrigin.Current); int streams = r.ReadInt16(); offset = new int[5]; ssize = new int[5]; names = new byte[5][]; names[0] = new byte[10]; names[1] = new byte[10]; names[2] = new byte[10]; names[3] = new byte[10]; names[4] = new byte[10]; int i = 0; int j; for (i = 0; i < streams; i++) { offset[i] = r.ReadInt32(); ssize[i] = r.ReadInt32(); j = 0; byte bb; while (true) { bb = r.ReadByte(); if (bb == 0) break; names[i][j] = bb; j++; } names[i][j] = bb; while (true) { if (s.Position % 4 == 0) break; byte b = r.ReadByte(); if (b != 0) { s.Seek(-1, SeekOrigin.Current); break; } } } for (i = 0; i < streams; i++) { if (names[i][1] == '~') { metadata = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) metadata[k] = r.ReadByte(); } if (names[i][1] == 'S') { strings = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) strings[k] = r.ReadByte(); } if (names[i][1] == 'U') { us = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) us[k] = r.ReadByte(); } if (names[i][1] == 'G') { guid = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) guid[k] = r.ReadByte(); } if (names[i][1] == 'B') { blob = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) blob[k] = r.ReadByte(); } } valid = BitConverter.ToInt64(metadata, 8); nooftables = 0; tableoffset = 24; rows = new int[64]; Array.Clear(rows, 0, rows.Length); for (int k = 0; k <= 63; k++) { int tablepresent = (int)(valid >> k) & 1; if (tablepresent == 1) { rows[k] = BitConverter.ToInt32(metadata, tableoffset); tableoffset += 4; } } tablenames = new String[]{ "Module" , "TypeRef" , "TypeDef" ,"FieldPtr","Field", "MethodPtr","Method","ParamPtr" , "Param", "InterfaceImpl", "MemberRef", "Constant", "CustomAttribute", "FieldMarshal", "DeclSecurity", "ClassLayout", "FieldLayout", "StandAloneSig" , "EventMap","EventPtr", "Event", "PropertyMap", "PropertyPtr", "Properties","MethodSemantics","MethodImpl","ModuleRef", "TypeSpec","ImplMap","FieldRVA","ENCLog","ENCMap","Assembly", "AssemblyProcessor","AssemblyOS", "AssemblyRef","AssemblyRefProcessor", "AssemblyRefOS", "File","ExportedType","ManifestResource","NestedClass", "TypeTyPar","MethodTyPar" }; for (int k = 0; k <= 63; k++) { if (rows[k] != 0) Console.WriteLine("Table {0} Rows {1} ", tablenames[k], rows[k]); } Console.WriteLine("Actual Tables start at {0}", tableoffset); } }
Output:
Table Module Rows 1
Table TypeRef Rows 3
Table TypeDef Rows 2
Table Method Rows 2
Table MemberRef Rows 3
Table CustomAttribute Rows 1
Table Assembly Rows 1
Table AssemblyRef Rows 1
Actual Tables start at 56
既然我们已经确定在文件中存在8个表,下一步就是在每个表中获取表的类型以及所包含的行数。上面的大部分代码保持不变。
我们将开始于下面一行代码:
valid = BitConverter.ToInt64(metadata, 8);
变量tableoffset被设置为24,从而包括了初始的头成员。
for循环的实现和前面一样,值k 的范围从0到63。初期,右移操作的结果(可能是值0或1),被添加到变量nooftables中。
然而,在这个程序中,结果被存储在变量tablepresent中
int tablepresent = (int)(valid >> k) & 1;
值1表示这个表被定位在指定位的位置上。因此,在收到这个回复时,在rows表中相应的项被初始化为一个存在于指定偏移量的值,这是一个包括在变量tableoffset中的值,即24。然后,由于4字节被考虑在内,变量tableoffset会增加4。
if (tablepresent == 1) { rows[k] = BitConverter.ToInt32(metadata, tableoffset); tableoffset += 4; }

在sorted字段之后的字节是一系列整数,它们包括了封闭在每个表中的行的数量。因此,这里存在8个表,那么8个值都被放置在头的结尾。每个值都涉及到一个相应的存在于文件中的表。
因此,变量tableoffset指向第一个整数,它包括了在第1个表类型中行的数量。按照顺序,第2个整数包括了在第2个表类型中行的数量,以此类推。从而,每个新的位都被设置为on,这里存在一个整数表示行的数量。一个整数占据了4个字节。因此,tableoffset的值会对于每个被添加的整数为增加4。
因此,在每个实例中,k表示位的索引,而tableoffset指向表中的行。这个数组类的静态函数Clear,从指定位置清除了数组的名称。这个函数的第1个参数是arrayname。第2个参数是开始位置的指针或索引。第3个参数是结束位置的索引,它包括了要被清除的字节的数量。由于我们想要清除整个数组,所以指定偏移量为0,并且以数组的长度作为最后一个参数。
因此,当循环结束时,row数组将包括存在于表中的行的数量,以及不存在于表中的值0。
现在,让我们为存在于程序中的表尝试并标识tablenames。
元数据世界中的每个表都被分配了一个数字和一个名称。因此,我们创建一个字符串数组,并在正确的索引位置上包括3个提到过的名称。带有数字0的表被称为模块(Module),而带有数字1的表被称为TypeRef,以此类推。
现在,使用for循环,连同if语句一起,迭代64次,显示表的类型。这只能在那些存在的表或带有一行或多行数量的表上实现。通过读取tablenames数组中的索引来显示表的名称。
最后,显示存储在tableoffset变量中的值。它指向表数据。现在,在讨论表数据之前,让我们展示一下#Strings流。
a.cs
using System; using System.IO; public class zzz { public void DisplayGuid(int st) { Console.Write("{"); Console.Write("{0}{1}{2}{3}", guid[st + 2].ToString("X"), guid[st + 1].ToString("X"), guid[st].ToString("X"), guid[st - 1].ToString("X")); Console.Write("-{0}{1}-", guid[st + 3].ToString("X"), guid[st + 4].ToString("X")); Console.Write("{0}{1}-", guid[st + 6].ToString("X"), guid[st + 5].ToString("X")); Console.Write("{0}{1}-", guid[st + 7].ToString("X"), guid[st + 8].ToString("X")); Console.Write("{0}{1}{2}{3}{4}{5}", guid[st + 9].ToString("X"), guid[st + 10].ToString("X"), guid[st + 11].ToString("X"), guid[st + 12].ToString("X"), guid[st + 13].ToString("X"), guid[st + 14].ToString("X")); Console.Write("}"); } public string GetString(int starting) { int i = starting; while (strings[i] != 0) { i++; } System.Text.Encoding e = System.Text.Encoding.UTF8; string s = e.GetString(strings, starting, i - starting); return s; } public static void Main() { zzz a = new zzz(); a.abc(); } int tableoffset; int[] rows; int[] offset; int[] ssize; byte[] metadata; byte[] strings; byte[] us; byte[] guid; byte[] blob; long valid; byte[][] names; public void abc() { long startofmetadata; FileStream s = new FileStream("C:\\mdata\\b.exe", FileMode.Open); BinaryReader r = new BinaryReader(s); s.Seek(360, SeekOrigin.Begin); int rva, size; rva = r.ReadInt32(); size = r.ReadInt32(); int where = rva % 0x2000 + 512; s.Seek(where + 4 + 4, SeekOrigin.Begin); rva = r.ReadInt32(); where = rva % 0x2000 + 512; s.Seek(where, SeekOrigin.Begin); startofmetadata = s.Position; s.Seek(4 + 2 + 2 + 4 + 4 + 12 + 2, SeekOrigin.Current); int streams = r.ReadInt16(); offset = new int[5]; ssize = new int[5]; names = new byte[5][]; names[0] = new byte[10]; names[1] = new byte[10]; names[2] = new byte[10]; names[3] = new byte[10]; names[4] = new byte[10]; int i = 0; int j; for (i = 0; i < streams; i++) { offset[i] = r.ReadInt32(); ssize[i] = r.ReadInt32(); j = 0; byte bb; while (true) { bb = r.ReadByte(); if (bb == 0) break; names[i][j] = bb; j++; } names[i][j] = bb; while (true) { if (s.Position % 4 == 0) break; byte b = r.ReadByte(); if (b != 0) { s.Seek(-1, SeekOrigin.Current); break; } } } for (i = 0; i < streams; i++) { if (names[i][1] == '~') { metadata = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) metadata[k] = r.ReadByte(); } if (names[i][1] == 'S') { strings = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) strings[k] = r.ReadByte(); } if (names[i][1] == 'U') { us = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) us[k] = r.ReadByte(); } if (names[i][1] == 'G') { guid = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) guid[k] = r.ReadByte(); } if (names[i][1] == 'B') { blob = new byte[ssize[i]]; s.Seek(startofmetadata + offset[i], SeekOrigin.Begin); for (int k = 0; k < ssize[i]; k++) blob[k] = r.ReadByte(); } } valid = BitConverter.ToInt64(metadata, 8); tableoffset = 24; rows = new int[64]; Array.Clear(rows, 0, rows.Length); for (int k = 0; k <= 63; k++) { int tablepresent = (int)(valid >> k) & 1; if (tablepresent == 1) { rows[k] = BitConverter.ToInt32(metadata, tableoffset); tableoffset += 4; } } xyz(); } public void xyz() { for (int k = 0; k < ssize[1]; k++) { Console.Write("{0}", (char)strings[k]); if (strings[k] == 0) Console.WriteLine(); } string s; s = GetString(10); Console.WriteLine("{0}", s); s = GetString(16); Console.WriteLine("{0}", s); DisplayGuid(1); } }
Output:
<Module>
b.exe
mscorlib
System
Object
zzz
Main
.ctor
System.Diagnostics
DebuggableAttribute
b
Console
WriteLine
b.exe
mscorlib
{A921C043-32F-4C5C-A5D8-C8C3986BD4EA}
这个程序显示了Strings流的内容。除了对函数xyz的介绍之外,代码的主要部分保持不变。简而言之,我们加载了磁盘的元数据信息到5个数组中。rows数组给出了每个表的行数。然后,我们到达了元数据数组中第一个表的tableoffset位置上。
现在,让我们探究一下xyz函数。这个函数将在今后重复遇到。此后,我们将只在xyz函数中添加所有新的代码
Strings流由以null作为终结的字符串组成。因此,在for循环中,当遇到一个null或0时,程序就会进行到下一行。通过使用Console类的不含任何参数的WriteLine函数,可以到达这个目的。
同时,这里有一个GetString函数,它会在传递一个Strings流的数组中数字或偏移量时返回一个字符串。可以通过使用Encoding类的GetString函数来达到这个目的,它接受3个参数,即一个字节数组、开始位置和结束位置。然后它会返回一个字符串。
开始位置是很容易使用的,因为它被作为GetString函数代码的一个参数来提供。然而,为了检索结束位置,要实现一个while循环,它会在遇到0时退出。在循环中,变量i被初始化为开始位置,之后,它会递增。当循环结束时,i包括字符串的结束位置。这个值被提供给Encoding类的GetString函数,它存储了字符串变量s中的返回值。GetString函数在所有的章节中会被广泛使用。
最后一个函数称为DisplayGuid。这个函数只包括Write函数。全局唯一标识符(GUID)是由16个字节组成的,即128位。这128位数字在时空中是唯一的。
因而,无论何时,一个实体必须是唯一标识的,它会被分配一个GUID。在Internet上有一个RFC算法来计算GUID。在DisplayGuid方法中,我们通过交换某些字节只是显示了GUID,这也是剩余世界显示它们的方式。我们读取GUID流到guid数组中,以免你将其忘记。