今天正在看书,老铁给我发来一道面试题。

初看这道题,我觉得是送分题。嘴角上扬写出一行命令:
print(list((i for i in a if '7net' not in i)))

仔细看了一眼,这道题说的是将字符删掉,好险中了他的招,然后改了一下。
an=(''.join(i.split('7net')) for i in a) print(list(an))

看了一下,没毛病,遂发给老铁,老铁瞬即回复:非也,非也。这种难度岂敢请教愚兄。此题有陷阱,若是生成列表推导或是生成器表达式抑或是map,filter,三元表达式,都改变了原来的列表生成了新的列表,其实已经不对了。
我去,没想到一个小小的面试题还暗藏玄机,我试了一下map函数,结果如下:
print(id(a[2])) xx=map(lambda x:x if '7net' not in x else ''.join(x.split('7net')) ,a) print(iter(xx)) print(iter(xx)) print(id(iter(xx)))
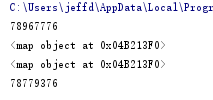
可以看出列表的第三个参数的id地址已经变化了,这个值并未包含‘7net’,所以此时列表其实已经不是最初的列表了(就是新列表了)。
看到这里,我想只能使用列表的删除方法才能完成原地修改了。
nn= (a.remove(i[1]) for i in list(enumerate(a)) if '7net' in i[1]) print(list(a))

生成器表达式中的remove并未生效,并没有改变原来的列表。
但是放到列表推导中却是可以的。
print(id(a)) nn= [a.remove(i[1]) for i in list(enumerate(a)) if '7net' in i[1]] print(list(a)) print(id(a))

print(id(a)) nn=[a.remove(i) for i in a if '7net' in i] print(a) print(id(a))

列表与生成器不同,在for循环中修改会导致索引前移,漏删元素。
但是这并不是我们需要的结果,我们需要的是在原来的基础上修改字符串而不是移除。
''.join(i.split('7net'),字符串是不可以原地修改的。所以这样必定会改变列表。
写到这,我基本上已经断定了,是不能写出这道题的了。因为python中的列表实际上是一个元素内存地址的存储序列,列表只是存储了一个类似指针的地址空间指向内部元素的实际存储地址。而,我们生成新的字符串就是让这些内存地址指向新的值,而新的值需要开辟新的内存空间来存储,那么只要换了新的字符串,那么现在的列表就一定不是原先的列表了。
too young,simple,上面都是我瞎扯的。
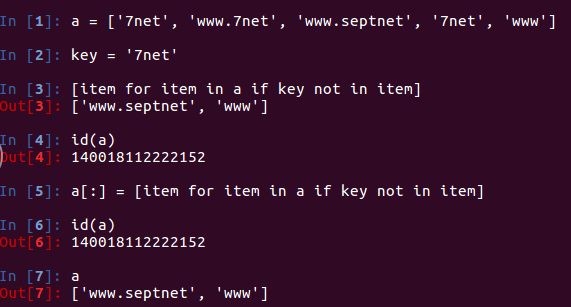
晚饭的时候,大佬贴来一段代码。仔细看了一下,将a浅拷贝,这时a还是之前的所有内存地址的序列,将原来的地址一一指向新的数据,那么列表已经原地修改。
这次看起来应该没什么问题了。
print(id(a)) a[:]=map(lambda x:x if '7net' not in x else ''.join(x.split('7net')) ,a) print(id(a)) print(a)

print('0',id(a[0])) print('1',id(a[1])) print('2',id(a[2])) print(id(a)) print('--------------------------') a[:]=map(lambda x:x if '7net' not in x else ''.join(x.split('7net')) ,a) print('0',id(a[0])) print('1',id(a[1])) print('2',id(a[2])) print(id(a)) print(a)

虽然存储字符串的地址发生了改变,但是存储列表的地址还是原地址,所以实现了原地修改。
所以正解是这样的:
a[:]=[i.replace('7net','') if '7net' in i else i for i in a]
是这样的:
a[:]=map(lambda x:x if '7net' not in x else ''.join(x.split('7net')) ,a)
还是总结一下,没有简单的问题,如果你觉得简单的话,那你真是太简单了。
欢迎指正我的错误。