0 序言
比赛已经过去一段时间,现在才来写总结似乎有点儿晚,但是挡不住内心发出的强烈呼唤的声音,所以决定静下心来梳理一遍,查缺补漏。
参赛契机:
2017年9月偶然在学校的官方微信推送中看到2017年CCF大数据与计算智能大赛正式启动的信息,仔细阅读了参加规则后就决定找队友一起参赛,试一试自己的能力。
有想法就立即行动,及时把比赛信息分享出去。经过不断宣传、沟通,最终与2位同门成功组队,开启我们的首次竞赛之旅。
成绩/排名:
136/796
1 赛题(引自大赛官网)
基于主题的文本情感分析
以网上电商购物评论为例,原始的主题模型主要针对篇幅较大的文档或者评论句子的集合,学习到的主题主要针对整个产品品牌;而现实情形是,用户评论大多针围绕产品的某些特征或内容主题展开(如口味、服务、环境、性价比、交通、快递、内存、电池续航能力、原料、保质期等等,这说明相比于对产品的整体评分, 用户往往更关心产品特征),而且评论文本往往较短。
2 任务描述(引自大赛官网)
本次大赛提供脱敏后的电商评论数据。参赛队伍需要通过数据挖掘的技术和机器学习的算法,根据语句中的主题特征和情感信息来分析用户对这些主题的偏好,并以<主题,情感词>序对作为输出。
3 评分规则(引自大赛官网)
本赛题采用F1-score进行评价。
注意:
1. 如果某些row_id样本中有多个主题,您只识别出其中几个,那么会被当做漏判识别。若识别出的主题多于答案,则会被当做多判识别。
2. 在最终评测时,我们按照“主题词-情感词-情感值”为最小粒度逐条与标注数据进行比对,若三者均与答案相符,则判为情感匹配正确,否则为错误。评分计算如下:
a) 情感匹配正确数量:tp
b) 情感匹配错误数量:fp
c) 情感匹配漏判数量:fn1
d) 情感匹配多判数量:fn2
3. 最终根据以上值计算选手的准确率(P)与召回率(R),按照含有度量参数β的Fβ公式进行计算:
准确率:P=tp/(tp+fp+fn2)
召回率:R=tp/( tp+fp+fn1)
Fβ的数学定义如下:Fβ=(1+β2)∗P∗R/(
β2∗P+R)
β=1
4 比赛过程
环境和工具:
Ubuntu16.04 + Pycharm
4.1 原始数据分析
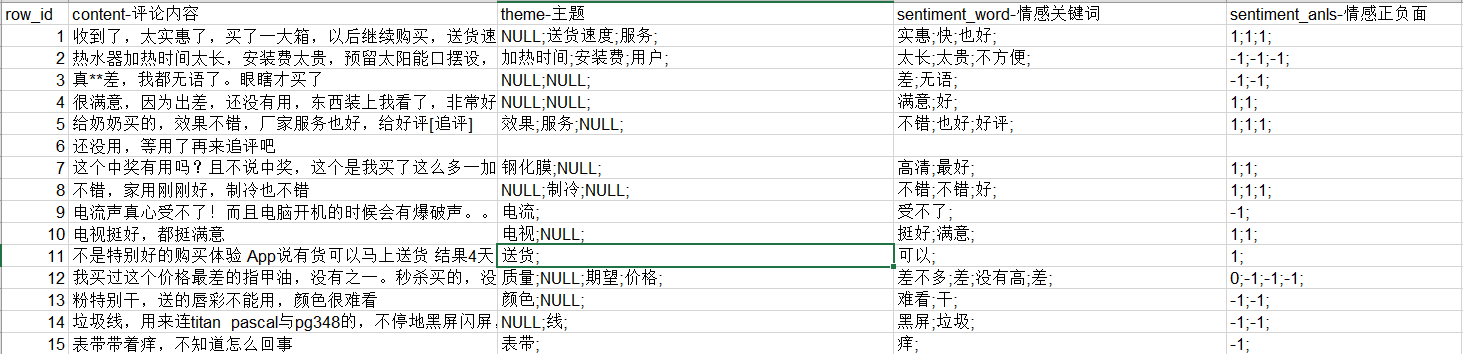
原始数据部分截图
- 包含空白的行(评论内容基本无价值,视为无效)
- 情感关键词与情感值联系密切,迅速判定从情感分析这个点入手。想到之前见过2分类的模型,现在是3分类,需要调整模型才能适用或者重新设计算法。
- 注意到情感词几乎是形容词,而主题几乎是名词,这也比较符合评论用语的习惯。考虑使用规则匹配,找到<名词,形容词>对。
- 情感值相当于标签,可以看做分类问题来处理。常用的分类模型可以尝试一下。
- 主题暂时不考虑(分任务进行)
- 评论文本需要分词,考虑使用jieba分词工具,再用word2vec转换成向量,以备后续处理。
4.2 数据预处理
这个阶段主要完成缺失值填充、重复值去除。
初步使用EXCEL 2013筛选查看了一遍数据,没有发现重复值,所以重点放在了缺失值的填充上。
2位队友和我一起筛选出包含缺失值的行,发现只要情感词缺失的,情感值和主题也缺失,再看评论内容也没有价值,所以我们讨论决定将这类数据剔除。
继续使用Python编程查看数据,发现情感关键词关联情感值和主题,决定利用情感词去填充主题。我们用最简单的思想,就是找到距离情感关键词最近的名词,把它定为主题。
对于情感值的缺失,也是依据情感关键词去做分类,最终确定对应的值。
至此,基本完成缺失值填充。
4.3 特征提取
这一步主要是针对评论内容的处理。首先就是分词,我们使用了jieba分词工具,外加它提供的自定义词典,完成分词。之后利用开源工具word2vec将分好的词转换成向量,以备后续使用。
4.4 选择模型
比赛进行到这个阶段,我们就开始广泛地查找资料。一位队友提出可以使用深度学习模型RNN来做分类,由于我完全没接触过,这部分就交给他继续跟进尝试。我和另一位队友选择使用情感词典+自定义规则构建模型,我主要负责构造情感词典,提供思路,队友则负责完善规则和优化代码。我们三人按照各自的分工分头行动,遇到问题就集中讨论。
4.5 代码实现
这里附上我们比赛的代码,细节就不在赘述。
请移步我的GitHub(https://github.com/digfound/CCFCompetition)查看,谢谢。
4.6 模型优化
由于没有找到比较合适的优化方法,所以这个步骤没有起到特别明显的作用。我们没有时间换用其他模型尝试,只是继续改进情感词典,但作用不大。
4.7 提交结果
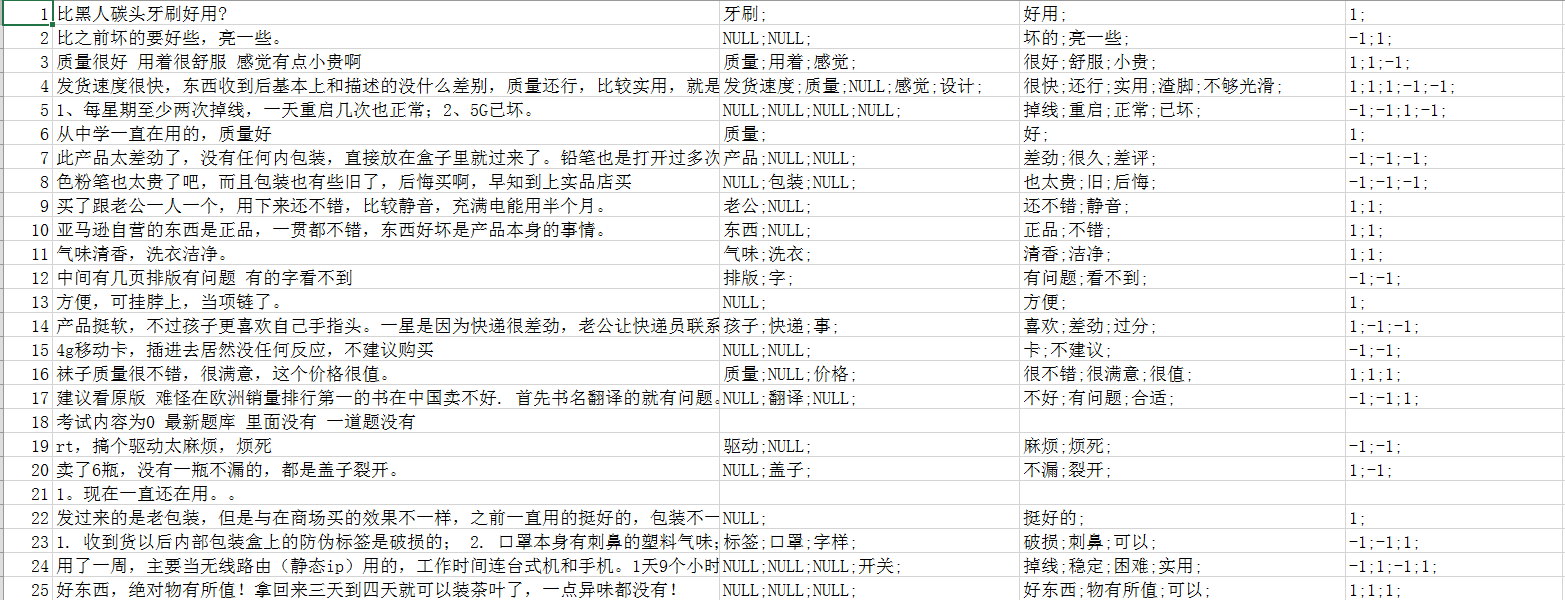
使用官网的提交系统,直接提交最后的结果文件,保存成CSV格式。
最终结果的部分截图如下:
5 致谢
- 感谢学校的微信推送,让我有遇见这次大赛的机会;
- 感谢2位同门的努力与陪伴,让我们在不断分析、讨论、研究中顺利完成比赛;
- 感谢自己的付出,让自己在专业实践方面、团队协作方面、表达沟通方面都得到不同程度的锻炼;
- 感谢其他的参赛队伍,有竞争才有进步!
6 总结反思
收获:
- 选择了与自己研究方向比较相关的赛题,加深了对平时所学理论知识的认知,特别是分词的处理和情感词典的构建;
- 在将近1个月的比赛过程中和2位队友相处比较融洽。队友们和自己的想法都得到比较充分的表达,有分歧的时候也能够理性地说服对方,锻炼了自己的思维表达能力;
- 比赛主要考察算法设计、数据处理方式等技术点,自己通过查找各种资料做参考,尝试分析解决实际问题,学习如何迁移别人的优秀经验来适应自己的需求,培养了自己的快速学习与实践能力。
不足:
- 存在第一次参赛容易出现的问题。比如磨合时间长、反馈不及时、任务分工不够清晰,导致做了一些重复的工作;
- 选择的模型比较简单,只是使用情感词典+自定义规则处理数据,导致最终的成绩不理想,与排名靠前的队伍成绩差距有点大;
- 没有找到合适的优化方法,导致调优的阶段几乎没有明显提升,所以最后无缘复赛。
7 写在最后
至此,自己能够想到的点已经写下来了,其中涉及到的理论知识点(比如数据预处理、特征提取、分词、word2vec、分类、情感分析等),之所以没有在此记录是因为本人觉得不适合将它们放在总结里,所以全部略去了,喜欢研究理论依据的博友们请自行学习。
最后,感谢各位的耐心阅读,欢迎大家给我留言,期待与你们讨论交流。