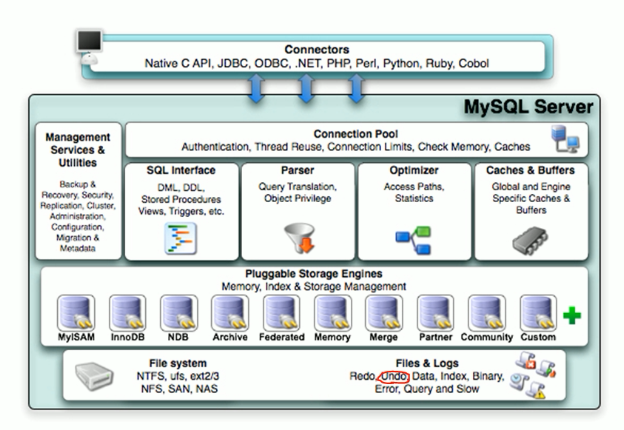
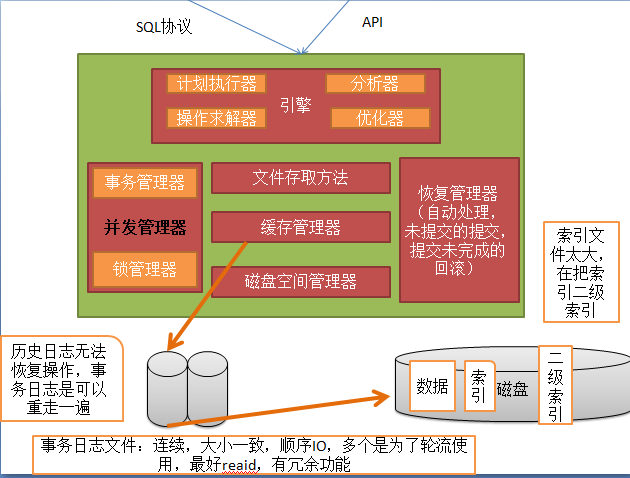
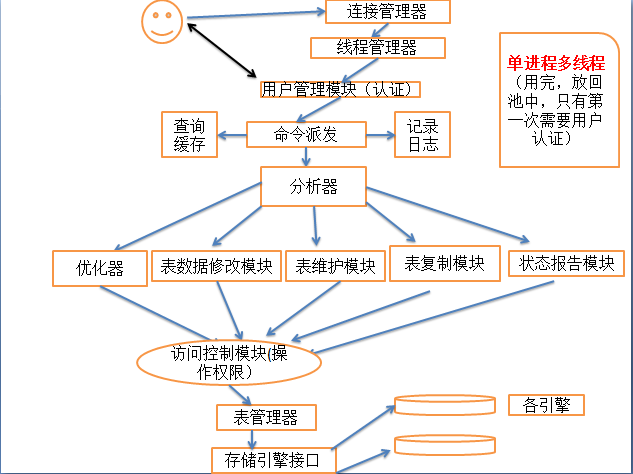
数据库: 程序=指令 + 数据 数据结构:变量,数组 I/O : 提供数据,保存数据 文件,交互式输入 持久存储 文件: 数据冗余和不一致性 数据访问困难 数据孤立 原子性问题 并发访问异常 安全性问题 DBMS: 层次型:倒装型 网状型:不易于开发,管理,都在一块混着 关系型:二维数据表(字段,记录) RDBMS:关系型管理工具 Sybase + Microsoft SQL Server Informix --> IBM DB2 Oracle <--- SUN MySQL MySQL --- > MariaDB percona公司:---> xtradb(增强版的innodb)-->用于MariaDB webscaledb -——>为web产生的web数据库 PsotgreSQL ,pgsql(性能优秀,但是市场决定一切) C/S架构: mysql --> mysqld (mysql协议) sqlite:(工作有本地的,关系型数据库接口,引擎,把数据组织成表格形似 数据库使用: 1、直接使用交互式接口; 2、使用开发程序软件: 可调用的客户端:API sqlite:客户端和服务器端在一块,不需要C/S通信了,数据保存在一个lib中,包括元数据等信息,同时又可以加载用以自己理解的形式查看 dbm:把数据保存成散列形式(哈希) SQL:structure query language DDL:定义 CREATE,DROP,ALTER DML:操作语言 INSERT,UPDATE,DELETE DCL:控制 GRANT,REVOKE DQL:查询 SELECT 事务: ACID A:原子性 ---> 要不执行,要不都执行 ,整个事务中的所有操作要么全部成功执行,要么全部失败后回滚 C:一致性 ---> 数据库总是从一个一致性状态转换为另一个一致性状态 I:隔离性 ---> 一个事务的所有修改操作在提交之前对其它事务是不可见的 D:持久性 ---> 一旦事务得到提交,其所做的修改会永久有效 提交:持久 未提交:提交,回滚 隔离:隔离级别 read uncommitted 读未提交 read committed 读提交 repeatable read :可重读 serializable:串行化 MySQL:存储引擎: MyISAM:无事务 分离索引:数据和索引分开 InnoDB:事务型 聚簇索引:数据和索引放一块 机械式硬盘:(对内存来讲,两种读写都是一样的) 随机读写:慢,磁盘指针转动需要时间 顺序读写: SQL:支持xml,可以输出为xml文件 规范:ANSI定义 SQL-86,89,92,99,03 关系数据库的约束: 主键约束,外键,唯一键,条件约束,非空约束 约束:constraint,向数据表提供的数据要遵守的限制; 主键:一个或多个字段的组合,填入的数据必须能在本表中唯一标识本行;必须提供数据,即NOT NULL; 一个表只能存在一个 惟一键:一个或多个字段的组合,填入的数据必须能在本表中唯一标识本行;允许为NULL; 一个表可以存在多个 外键:一个表中的某字段可填入数据取决于另一个表的主键已有的数据; 检查性:字段值在一定范围内 索引:将表中的一个或多个字段中的数据复制一份另存,并且此些需要按特定次序排序存储; 关系运算: 选择:挑选出符合条件的行(部分); 投影:挑选出需要的字段; 连接:表间字段的关联 数据抽象: 物理层:决定数据的存储格式,即RDBMS在磁盘上如何组织文件; 逻辑层:描述DB存储什么数据,以及数据间存在什么样的关系; 视图层:描述DB中的部分数据; 关系模型的分类: 关系模型 实体-关系模型 基于对象的关系模型 半结构化的关系模型 DBA: 开发: 数据库设计 代码设计 :存储过程,存储函数,触发器 管理: 连接管理及优化 备份及还原 数据库设计 基本语句优化 用户即权限管理 安全管理 数据库软件安装和升级 配置优化 MySQL: 高性能,完全多线程,查询缓存(小规模) 支持复制(伸缩性) Product Family: MySQL server(mysqld,mysql) MySQL Cluster MySQL Proxy MySQL Adminitrator MySQL Query Browser MySQL Workbench MySQL Arch: 真正执行SQL的是优化器之后的存储引擎,所以一个库支持一个引擎
MySQL安装: rpm 源码编译 通用二进制(已经编译好的) 版本: GA: RC: 即将变为GA beta:共测 alpha:内侧 rpm安装:client , server, shared, shared-compat 二进制安装: 插件式引擎 三种默认服务,mysqld,mysqld-safe,mysql-mtuil 默认开始的是safe 约束: 主键约束: 不能重复,不能为NULL,有且只能有一个 外键约束 唯一键约束 可以有多个,唯一,可能为NULL 检查是约束 用户自定义有效取值范围 键:(字段) 主键:能够 唯一 标识表中每一个记录的字段或字段的组合(不能重复,不能为NULL) 候选键:可以挑来做主键的组合,但是没选 初始化:提供配置文件 配置文件 .cnf 集中式的配置,多个应用程序共用的配置文件 [mysqld]: [mysql_safe] [client] # ./usr/local/mmysql/bin/mysqld --help -v | head -20 # 读取配置文件的顺序 Default options are read from the following files in the given order: /etc/mysql/my.cnf /etc/my.cnf ~/.my.cnf 使用配置文件的方式: 1、它一次查找每个需要查找的文件,结果多有文件的并集 2、如果某参数出现多次,后去读取的生效 # ./usr/local/mmysql/bin/mysqld --help -v 1、显示 mysql程序启动时可用的选项,通常是长选项 2、显示mysql的配置文件中可用的服务变量 SHOW GLOBAL VARIABLES SHOW SESSION VARIABLES 初始化的第二个操作: 1、删除所有的匿名用户 DROP USER ''@loaclhost DROP USER ''@node2 用户账号有两部分组成: user@hostname host可以使用通配符 %:任意长度的字符串 _:下划线匹配任意单个字符 2、给所有的root用户设定密码 第一种方式: SET PASSEORD FOR usernam@host = PASSEWORD('1231') 第二种范式:比较妥当的方式 UPFATE user SET password = PASSWORD('12345') WHERE user='root'; FLUSH PRIVILEGES; 第三种方式: mysqladmin -uUserName -hHost -p password 'new_password' mysqladmin -uUserName -hHost -p flush-privileges; 接入mysql服务器: mysql client <----> mysql protocol ---> mysqld mysqld 接受连接请求L: 本地通信:客户端与服务器端在同一个主机,而且还要基于127.0.0.1(localhost)地址或lo接口进行通信 Linux和UNix:unix sock /var/lib/mysql/mysql.sock windows:本地通信:共享内存,管道通信---memory,pipe 远程通信:客户端与服务器位与不同的主机,或在同一主机使用非 本地回环地址通信 tcp socket 客户端工具: mysql,mysqladmin,mysqldump,mysqlcheck 有[client]段,其中的所有项,对以上工具都是生效的。 通行的选项: -u -h -p, --password --protocol = {tcp|scok|pipe|memory} 后三者都是本地,后两者是windows上 --port 端口 --socket :指定文件名(本地通信) mysql监听端口:tcp/3306 非客户端类的管理工具: myisamchk, myisampack 第一个是检查工具 第二个是打包工具 mysql: 交互式模式: 脚本模式:输入重定向 mysql < /path/mysql.mysql 交互式模式: 客户端命令:不要分号 help:查看命令 C:不执行命令(命令结束符之前使用) G:Send command to mysql server, display result vertically. g:Send command to mysql server. q:Exit mysql. Same as quit. ! :Execute a system shell command s: Get status information from the server. . 导入mysql脚本 服务器端命令:需要命令结束符,默认分号 help 关键字:查看帮助 help contents:内容列表,获取整体,获取某个,跟上具体的名字 mysql命令行选项: --compress:压缩传输 --default-character-set:默认字符集(mysql客户端),用的很少,避免与服务器端不同的编码方式 -v -V: --ssl-ca:ca证书文件 --ssl-capath:多个ca证书,自动寻找 --ssl-cipher:冒号分割是加密方式 --ssl-verify-server-cert:验证服务器端证书 -D /--database= :直接指定要使用的库 mysql命令提示符: mysql> 等待输入命令 '> "> `> /*> 注释 */ 结束 -> :续航 支持光标移动: crtrl + w:删除 光标之前的单词 ctrl + u: 删除光标之前至命令行之前的所有内容 ctrl + y:恢复之前删除的内容 ctrl + a:行首 ctrl + e:行尾 -A:禁用命令补全 /#: 启用 当前用户家目录下 ~/.mysql.history: 命令历史 mysql的输出格式: -H: mysql -H -uroot -p 进入之后,执行的命令结果都是html格式的 -X:输出格式为xml --safe-updates:实现发送命令时拒绝 没有where 或update 命令,如果后弦限制了行数的话,也可以执行 mysqladmin工具: mysqladmin [options] command command: create:创建库 mysqladmin -uroot -p create mydb :不需要登录创建库 mysql -uroot -p -e show databases;直接查看库 drop dbName:删除库 debug:打开调试日志,并记录与mysql的error log中 status:输出状态信息 mysqladmin -uroot -p status --sleep 1 --count 5:间隔时长,显示的批次 extended-status :相当于show global status 输出mysql的各状态变量及其值 variables:mysql的各服务器变量 flush-hosts:清空主机缓存 DNS解析缓存,此前因为连接错误次数过多而被拒绝访问mysql的主机 flush-logs:日志滚动(二进制日志,中继日志) refresh:相当于同时使用 flush-hosts, flush-logs flush-ptivileges:重载授权表 reload flush-status:重置状态变量,不是清空,只把启动到现在的一些变量信息归0 flush-tables:关闭当前打开的表文件句柄(手动加锁的时候用) flush-treads:清空线程缓存 kill :杀死指定的线程(线程ID),使用逗号分隔,不能有多余的空白字符 password:修改指定用户密码 ping:服务器是否在线 processlist:各线程信息 shutdown:关闭mysql进程 start-slave:启动从服务器线程 stop-slave:关闭 GUI客户端工具: Navicat for mysql: 之前公司用的 SQLyog phpMyAdmin MySQL Front 开发DBA: 数据库设计(E-R关系图) sql开发,内置函数,存储例程(存储过程和存储函数)--尽量在服务器端执行,触发器(自动执行),事件调度器(event sechduler) 管理DBA: 安装, 升级,卸载,备份,恢复,用户管理,权限管理,监控,测试,分析,语句优化(sql语句),配置服务器(服务器变量,定制存储引擎参数,内置缓存,日志),数据字典, SQL语言的组成部分: DDL:数据定义语言 DML:数据操作语言 完整性定义语言:DDL的一部分功能 主键约束,外键约束(不是所有的引擎支持),条件约束,唯一键约束,非空约束,事物约束 视图定义:虚表,存储下来的的select语句 事务控制: 动态sql 和 嵌入sql DCL:控制(授权) 数据类型的作用: 1、存储的值类型;数据类型 2、存储空间的大小 3、定长,变长 4、如何被索引及排序:binary 是区分大小写的 5、是否能够被索引 text(只能索引左侧固定长度的信息) 数据字典:系统编目(systm catalog),并不是目录 保存数据库服务器上的元数据 初始化数据表:mysql这个库 元数据: 关系的名字 每个关系的各字段的名字 各字段的数据类型和长度 约束 每个关系上的视图的名字及视图的定义 授权用户的名字 用户的授权和账号信息 统计类的数据: 每个关系字段的个数 每个关系中函数 每个关系的存储方法 保存元数据的数据库: information_schema 元数据,统计类信息, 虚的,不存在,在内存中,类似于/dev/映射为的设备文件 performance_schema 性能信息 SQL语句: 数据类型: 字符型: 不区分大小写: char varchar text: 区分大小写: binary varbinary blob:二进制的大对象 数值型 精确数值型 整型 十进制数据: 近似数值型 单精度 双精度 日期型 时间型 日期型 日期时间型 时间戳 YEAR 布尔型:非真正的bool型 tinyint 内建型 ENUM, SET(枚举,集合) 数值型: TINYINT:精确 SMALLINT MEDIUMINT INT BIGINT DECTML FLOAT DOUBAL 字符型: CHAR VARCHAR TINYTEXT MEDIUMTEXT LONGTEXT BINARY VARINARY BLOB MEDIUMBOLB 变长 是需要结束符的 尽量不要使用text,索引空难,而且以对象索引,存在于数据库外的某个位置,数据库存指针 尽量别可变长度,影响索引 char --- 最多255个字符 varchar --- 最多65535个字符 tinytext --- 最多255个 CHAR , VARCHAR, TEXT字符型常用的属性修饰符: NOT NULL:非空约束 NULL:运行为空 DEFAULT ‘string':不适用于text CHARACTER SET ' 字符集':指定字符集 (从小到大范围继承) 查看字符集: SHOW CHARACETER SET; SHOW VARIABLES LIKE '%CHAR%' 支持的排序规则: SHOW COLLATION; BINARY,VARBINARY, BLOB:二进制存储,字节的大小排序 NOT NULL NUL DEFAULT : 不适用于BLOB 数值型:常用属性修饰符 TINYINT 0-255 1字节 SMALLINT 0-65535 2 MEDIUMINT 0-16777215 3 INT 0-4亿 4字节 AUTO_INCREMENT :自动增长 前提:非空,唯一,支持索引(用过之后,就不会再用,即便前面数删除了),非负值。 SELECT LAST_INSERT_ID():显示插入语句用了多少,但是准确,如果批量插入,只记录1次 使用 DROP FROM table;再插入数据,LAST_INSERT_ID() 从当前数据增长 最好使用 TRUNCATE table; 就1开始 UNSIGNED:无符号 NULL, NOT NULL , DEFAULT 不能加引号 浮点型:支持使用精度 NULL , NOT NULL , DEFAULT,UNSIGNED 日期: DATE 3 字节 DATETIME 8字节 TIME 3字节 YEAR 1字节 NOT NULL NULL DEFAULT ENUM:最大65535个字符,字符串,只能选一个 SET:单个字符, 或几个字符,用的时候,是挑几个的组合,而且使用的是索引 可以支持多个字节。 NOT NULL NULL DEFAULT ‘’ MySQL mysql_mode:sql 模型: 常用的模式: TRADITIONAL:传统模式 STRICT_TRANS_TABLES:事务的表严格模式 STRICT_ALL_TABLES:所有的都 严格 SHOW GLOBAL VARIABLES LIKE '%mode%' 设定服务器变量的值:(仅用于支持动态的变量) 支持修改的服务器变量: 动态变量:mysql运行时修改 静态变量:于配置文件中修改,重启后才能生效 服务器变量从其生效范围: 全局变量:服务器级别的,修改之后,仅对新建立的会话有效 会话变量:仅对当前的会话有效 会话建立时 ,从全局继承各变量 查看服务器变量: SHOW GLOBAL[SESSION] VARIABLES [LIKE ' '] :默认session SELECT @@{GLOABL|SESSION}.sql_mode 或者在 information_schema 库中,表中查看 修改变量: 前提:默认只有root才有权限修改全局 SET global | session variable_name=''; 例如: SET SESSION SQL_MODE=‘’ 修改了去全局,对当前会话无效,对新建会话有效。 注:无论是全局还是会话级别的动态变量的修改,在重启mysql后,都会失效,想永久有效,一般放下配置文件的[mysqld] mysql --help -v : 带-- 命令行参数, 不加的是配合文件参数,有重叠,但不一定相同 MySQL的大小写问题: sql的关键字和函数名,是不区分大小写的。 数据库,表,视图的名字,取决于 文件系统,linux区分,windows不区分(移植库 可能会出现问题) 存储过程和存储函数,事件调度器不区分大小写 触发器区分大小写 表别名 区分大小写 主键,唯一键是否区分大小写:字段类型,binary区分大小写,char 不区分 SQL表,库管理语句: 数据库: 创建数据库: CREATE DATABASE | SCHEMA [IF NOT EXISTS] [CHARACTER SET = ''] [COLLATE = ''] db_name; 默认字符集:等号可有可无 CHARACTER SET = 排序:等号可有可无 COLLATE = 默认值: DEFAULT 删除库: DROP DATABASE | SCHEMA [IF EXISTS] db_name 修改数据库: [CHARACTER SET = ''] [COLLATE = ''],也可以升级数据字典 ALTER DATABASE | SCHEMA db_name [CHARACTER SET = ''] [COLLATE = ''] 表创建方式一: 数据表:键是索引,索引不一定是键,键有约束 HELP CREATE TABLES; ------- CREATE [TEMPORARY] TABLE [IN NOT EXISTS] tb_name (create_definition ,...) [table_options] [partition_options] (create_definition ,...): 字段定义:字段名,类型,类型修饰符 键,约束或索引: PRIMARY KEY, UNIQUE KEY, FOREIGN KEY, CHECK {INDEX | KEY} create table t1 (Name varchar(30) not null , age tinyint unsigned not null,primary key(Name,age)); 多字段组成的主键 [table_options]: ENGINE= engine_name; AUTO_INCREMENT [=] value 从几开始 CHARACTER SET [=] characte—name COLLATE [=] collation_name COMMATION [=] 'STRING' 注释 DELAY_KEY_WRITE [=] {0|1}:索引降低写,提高查,每次修改都要重新构建,过一会再写入 ROW_FORMAT [=] {DEFAULT|DYNAMIC|FIXED|COMPRESSED|REDUNDANT|COMPACT} 表格式 TABLESPACE tablespace_name [STORAGE {DISK|MEMORY|DEFAULT}] 表空间 create table t1 (Name varchar(30) not null , age tinyint unsigned not null,primary key(Name,age)) engine='MyISAM'; 添加引擎 SHOW ENGINES; 存储引擎 SHOW TABLE STATUS LIKE 't1'G mysql> SHOW TABLE STATUS LIKE 't1'G *************************** 1. row *************************** Name: t1 Engine: InnoDB Version: 10 Row_format: Compact Rows: 0 Avg_row_length: 0 Data_length: 16384 Max_data_length: 0 Index_length: 0 Data_free: 10485760 Auto_increment: NULL Create_time: 2018-10-26 09:41:59 Update_time: NULL Check_time: NULL Collation: utf8_general_ci Checksum: NULL Create_options: Comment: MyISAM表每个表都有是哪个文件,都位于数据库目录中: tb_name.frm: 表结构定义 tb_naem.MYD:数据文件 tb_name.MYI:索引文件 InnoDB 有两种存储方式: 1、默认:每个表有一个独立文件和一个多表共享的文件 tb_name.frm:表结构的定义,位于数据库目录(与数据库同名的目录) ibdata#:共享的表空间文件(所有的表),默认位于数目录(datadir指向的目录)中 2、独立的表空间文件,每表有一个表结构文件一个独有的表空间文件,包括索引。 修改配置文件:[mysqld] show global variables like '%innodb%'; | innodb_file_per_table | OFF | tb_name.frm:每表一个表结构文件 tb_name.ibd:一个独有的表空间文件 表创建方式二:(复制表数据 CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name [(create_definition,...)] [table_options] [partition_options] select_statement 表创建方式三:基于某张表,创建空表(复制表结构) CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name { LIKE old_tbl_name | (LIKE old_tbl_name) } 表删除: DROP [IF EXISTS] tb_name [CASCADE -- 级联,关联的也会删除] 修改: ALTER TABLE tb_name 修改字段定义: 插入新字段: ALTER TABLE t1 ADD IID INT NOT NULL; 删除字段: ALTER TABLE t1 DROP IID; 修改字段: 修改字段名称; | CHANGE [COLUMN] old_col_name new_col_name column_definition [FIRST|AFTER col_name] ALTER TABLE t1 CHANGE Name Sname char(10) NOT NULL; 修改字段类型及属性等: | MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name] ALTER TABLE t1 MODIFY Name varchar(30) AFTER age; 添加索引: ALTER TABLE t1 ADD INDEX (Sname);把某个字段作为索引 给某个字段添加索引: CREATE INDEX idx_name ON tb_name(字段(指定长度)):指定长度:如果该字段的索引到了一定值后不会再改变,可以节省空间 查看索引: show indexes from t1; 删除一个索引; ALTER TABLE t1 DROP INDEX Sname; DROP INDEX idx_name ON tb_name SHOW INDEX_STAISTICS;查看索引利用情况 修改约束,键,索引 表改名: RENAME [TO|AS] db_name 也可以直接使用: mysql> RENAME TABLE old_name TO new_name; 不建议修改引擎:(它会新建一个表,把数据复制过去) 要是修改,直接指定 指定排序标准的字段: ORDER BY col_name 转换字符集及排序规则: CONVERT TO CHARACTER SET charset_name [COLATE collation_name] SQL查询语句: 单表查询:简单查询 多表查询:连续查询 联合查询: 单表查询:简单查询 选择和投影: 选择:挑选要显示的行: 投影:挑选要显示的字段 投影:SELECT 字段1,字段2,... FROM 表名; SELECT * FROM tb_name; 选择:SELECT 字段 FROM tb—name WHERE 子句; 布尔条件表达式 比较操作符: =:等值比较 <=> : 跟NULL 比较不会出现错误的 等值比较 <> != :不等比较 < > <= >= IS NULL:不能用= IS NOT NULL: LIKE:模糊匹配 % _ RLIKE:支持使用正则表达式的 REGEXP: IN:某一字段的值是否在指定的列表中 BETWEEN ,,, AND,,, : 在,,,之间 WHERE Age NETWEEN 10 AND 30; CREATE TABLE students (SID INT UNSIGNED AUTO_INCREMENT NOT NULL unique key,Name CHAR(10) NOT NULL, AGE INT UNSIGNED NOT NULL ,Gender ENUM('M','F') NOT NULL, Tutor CHAR(20)); INSERT INTO students VALUES ( , , ,) INSERT INTO tb_name (co1,co2) VALUES(VA1,VA2) 组合条件测试: NOT ! AND && OR || XOR:异或 排序: ORDER BY ' ' ASC 默认升序 ORDER BY ' ' DESC 降序 select * from students order by -classid desc;将NULL 放到最后 mysql内置的聚合函数: SUM(), AVG(), MAX() , MIN(),COUNT() SELECT SUM(Age) FROM students; 分组:以什么为条件,分组 GROUP BY SELECT gender,sum(age) fromstudents GROUP BY gender; 对GROUP BY的结果做过滤,使用having, 注:where用在group by之前 SELECT gender,sum(age) fromstudents GROUP BY gender having gender='M' 返回有限 的行 limit select* from, students limit 2 select* from, students limit 2,3 # 偏移两行,显示三行 SELECT语句的执行流程: FROM --> WHERE --->GROUP BY ---> HAVING ---> ORDER BY --SELECT ---> LIMIT SELECT语句后: DISTINCT:重复的值 只显示一次 SQL_CACHE:缓存与查询缓存中, SQL_NO_CACHE:不缓存 多表操作:
内连接:交集,缺点是,如果有的 NULL 不显示 老方法:where 判断 select * from students as s, teachers as t where s.teacherid=t.tid; 如果有相同的字段,可以加上表名.字段 select stuid,s.name,tid, s.name from students as s, teachers as t where s.teacherid=t.tid; 新方法:inner join ... on..... select s.name, s.age,t.name from students s inner join teachers t on s.age=t.age; 左外连接: 左边表的全部内容,右边的处理交集,都为NULL, left outer join select * from students s left outer join teachers t on s.teacherid=t.tid; 右外连接:right outer join ... on ... 注意表的先后顺序; 对结果再次过滤: select * from students s left outer join teachers t on s.teacherid=t.tid where t.age>50; 左外连接去掉交集: select * from students s left outer join teachers t on s.teacherid=t.tid where t.tid is null; 右外连接去掉交集: 完全外链接:并集 select* from students s full outer join teachers t on s.teacherid=t.tid -----mysql 不支持 左外连接+ 右外连接+ union select * from students s left outer join teacher t on s.teacherid=t.tid -> union -> select * from stundents s right outer join teachers t on s.teacherid=t.tid 完全外连接去除交集: 上米昂的完全外链接,去掉公共部分 自连接:SELEsCT t.name,s.name FROM students s , students t where s.TID=t.tezcherID +-------+---------------+-----+--------+---------+-----------+ | TID | Name | Age | Gender | ClassID | TeacherID | +-------+---------------+-----+--------+---------+-----------+ | 1 | Shi Zhongyu | 22 | M | 2 | 3 | | 2 | Shi Potian | 22 | M | 1 | 7 | | 3 | Xie Yanke | 53 | M | 2 | 16 | | 4 | Ding Dian | 32 | M | 4 | 4 | | 5 | Yu Yutong | 26 | M | 3 | 1 | 子查询: 在查询中嵌套的查询 用于WHERE中的子查询: 1、用于比较表达式中的子查询 子查询的返回值只能有一个 2、用于EXISTS中的子查询 判断存在与否 3、用于IN 中的子查询 判断存在于指定的列表中 SELECT name,classid from students 用于From的子查询: SELECT alias.co1,... FROM (select clause) as alias where condition SELECT S.Name,s.Age, s.gender FROm (SELECT * FROM students WHERE gender='M') as s WHERE Age > 25 MySQL不擅长子查询,应该避免使用,尽量使用联合查询 MySQL的联合查询: 表结构的合并: 纵向合并:字段数一直,数据类型一致。 union: select stuid,name,age,gender from students union select * from teachers; 有一模一样的数,是可以去重的。 但是谁union谁是有区别的,还有字段名字 select * from teachers union select stuid,name,age,gender from students ; 自己union 自己,就会去重,但是一般都是有主键的; 横向合并: cross join:交叉乘积 select * from students cross join teachers; +-------+---------------+-----+--------+---------+-----------+-----+---------------+-----+--------+ | StuID | Name | Age | Gender | ClassID | TeacherID | TID | Name | Age | Gender | +-------+---------------+-----+--------+---------+-----------+-----+---------------+-----+--------+ | 1 | Shi Zhongyu | 22 | M | 2 | 3 | 1 | Song Jiang | 45 | M | | 1 | Shi Zhongyu | 22 | M | 2 | 3 | 2 | Zhang Sanfeng | 94 | M | | 1 | Shi Zhongyu | 22 | M | 2 | 3 | 3 | Miejue Shitai | 77 | F | | 1 | Shi Zhongyu | 22 | M | 2 | 3 | 4 | Lin Chaoying | 93 | F | | 1 | Shi Zhongyu | 22 | M | 2 | 3 | 5 | Yu Yutong | 26 | M | EXPLAIN select 语句: 显示查询详细细节,可以看用到索引没 等信息 mysql> EXPLAIN select * from students s, teachers t where s.teacherid = t.tidG *************************** 1. row *************************** id: 1 select_type: SIMPLE table: s type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 25 Extra: *************************** 2. row *************************** id: 1 select_type: SIMPLE table: t type: ALL possible_keys: PRIMARY key: NULL key_len: NULL ref: NULL rows: 4 Extra: Using where; Using join buffer 视图: 虚表 存储下来的 select 语句:执行结果返回 create view stu AS SELECT Name,Age FROM students; show tables; show create view stu;查看创建过程 可以设置用户 访问view,就只能访问某些字段 插入数据: 可以插入数据,同时插入到原表中,但是如果视图设置了过滤条件,比如age>30 插入的20 ,是插不到视图,但是还是能插到原表中 删除: DROP VIEW stu; 查看waring:只能在刚出现warings后查看,在期间执行其他语句后,就查不到了 show warings; 插入:INSERT 第一种: INSERT INTO tb_name [(col1,col2...)]{VALUES|VALUE} (val11,val12...) (val21,val22...) 第二种: INSERT INTO tb_nam SET col=val1 ,col2=val2 第三种: INSERT INTO tb_name SELECT clause RAPLACE: 如果定义了主键的,唯一键的,只能替换,重复的不能插入 使用方式同INSERT 更新:可以多表,一般少用 UPDATE UPDATE [LOW_PRIORITY] [IGNORE] table_reference SET col_name1=val1 [, col_name2=val2] ... [WHERE where_condition] [ORDER BY ...] [LIMIT row_count] UPDATE 通常必须使用WHERE 子句或者 LIMIT 限制要修改的行数 UPDATE student_count SET student_count=student_count+1; --safe-update:避免因为没有where 全改了 DELETE: DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name [WHERE where_condition] [ORDER BY ...] [LIMIT row_count] DELETE FROM students WHERE stuid = uid; 函数:不怎么使用 函数是有作用域的,某个库的,不能被其他库调用,(通过其他方式可以实现) show function status; 查看所有的函数 存储于mysql库中的proc表中 DELIMITER ; 设置语句结束符 函数:系统函数和自定义函数 系统函数:https://dev.mysql.com/doc/refman/5.7/en/func-op-summary- ref.html 自定义函数 (user-defined function UDF) 保存在mysql.proc表中 创建UDF CREATE [AGGREGATE] FUNCTION function_name(parameter_nametype,[parameter_name type,...])RETURNS {STRING|INTEGER|REAL} runtime_body 说明: 参数可以有多个,也可以没有参数 必须有且只有一个返回值 自定义函数 创建函数 示例:无参UDF CREATE FUNCTION simpleFun() RETURNS VARCHAR(20) RETURN "Hello World!”; 查看函数列表: SHOW FUNCTION STATUS; 查看函数定义 SHOW CREATE FUNCTION function_name 删除UDF: DROP FUNCTION function_name 调用自定义函数语法: SELECT function_name(parameter_value,...) 示例:有参数UDF DELIMITER // CREATE FUNCTION deleteById(uid SMALLINT UNSIGNED) RETURNS VARCHAR(20) BEGIN DELETE FROM students WHERE stuid = uid; RETURN (SELECT COUNT(stuid) FROM students); END// DELIMITER ; 自定义函数中定义局部变量语法 DECLARE 变量1[,变量2,... ]变量类型 [DEFAULT 默认值] 说明:局部变量的作用范围是在BEGIN...END程序中,而且定义局部变量语句必须在 BEGIN...END的第一行定义 示例: DELIMITER // CREATE FUNCTION addTwoNumber(x SMALLINT UNSIGNED, Y SMALLINT UNSIGNED) RETURNS SMALLINT BEGIN DECLARE a, b SMALLINT UNSIGNED; SET a = x, b = y; RETURN a+b; END// DELIMITER ; 为变量赋值语法 SET parameter_name = value[,parameter_name = value...] SELECT INTO parameter_name 示例: ... DECLARE x int; ----只能在函数中调用 SELECT COUNT(id) FROM tdb_name INTO x; RETURN x; END// MySQL管理: 第一层:面向连接,用户请求的连接,管理释放。 Mysql是明文的,支持文本和二进制两种格式的传输。 加密:基于SSL 第二层:MySQL核心服务层,BIF(内置函数),视图等。。。 分析器:语法分析,语句切片等完成优化(yacc,lex分析器,开源的) 优化器:语句重构,多表查询,调整顺序,选择开销最小的索引 EXPLAIN: 第三层:存储引擎,负责数据的存储和提取。 MySQL锁: 执行操作时,施加的锁模式: 读锁:共享锁,A读,不会影响B的读 写锁:独占锁,排他锁,不能查,写, 其他可能查到,因为缓存,要不这样,关闭query_cache_wlock.... 锁粒度: 表锁:table lock 锁定了整张表 行锁:row lock 锁定了需要的行 粒度越小,开销越大,但并发性越好 锁的实现位置: MySQL锁(第二层):显示锁,可以手动施加 存储引擎锁(第三层):隐式锁,自动的 显示锁: LOCK TABLES; UNLOCK TABLES; LOCK TABLES tbl_name lock_type [, tbl_name lock_type] ... UNLOCK TABLES; 施加读锁,不影响别人读,但是别人不能锁,只有释放,别人才能写,自己也不能写 施加写锁, 别人不能读,也不能写 InnoDB存储引擎 也支持另外一种显示锁(锁定挑选出的部分行,行级锁) SELECT .... LOCK IN SHARE MODE; SELECT .... FOR UPDATE; 先 show tables classes status; 查看引擎类型 注意:锁是在执行语句的过程中加入的,语句执行完,就失效了 SELECT * FROM classes WHERE ClassID <= 3 LOCK IN SHARE MODE; SELECT * FROM classes WHERE ClassID <= 3 FOR UPDATE; 事务:Transaction 事务就是一组原子性的查询语句(查询—*****),也即将多个查询当作一个独立的工作单元。 ACID测试:能满足ACID 的测试,就表示能支持事务,兼容事务 A:atomictiy原子性,一个事务被视为一个不可分割的单元,要不执行,要不都不执行 C:Consistency ,一致性, A 转账B 总金额是不变的,从一个一致性状态,到另一个一致性状态 I:isolation,隔离性,事务所做的操作,在提交之前,别人是看不到的 A -300的过程,别人看不到A 减少了300 (在没提交之前) D:durability,持久性,一旦事务提交了,其所作的修改就会永久有效 隔离级别: READ - UNCOMMITED :读尚未提交,安全性差,并发好点(别人也能看到你没有提交的数据),会出现脏读,出现不可重复读(两次结果不一致,一个是未提交,一个是提交之后) READ - COMMITTED (读提交,未提交的看不到,不可重读) REPEATABLE READ(可重读,解决脏读),出现幻读 ---mysql,两个人同时是操作数据库,未提交,看到两种不同结果 A 删除了一条,也提交了 B 还是没有看到删除的,只有自己提交,在开启,才能看到删除的 便于数据备份,备份过程中数据不变 SERIALIZABLE 可串行化,隔离级别最高,但是性能太低(事务串行执行) 事务的未提交读 组织别人的写 A 为提交 B 阻塞 > start transaction > commit > rollback 全部回滚 > savepoint point_name > rollabck to point_name 提交事务后,不能回滚的(显示开启,显示提交) innodb支持自动提交事务(非显示开启),每一条语句都是一个事务,行级锁 SHOW GLOBAL VARIABLES LIKE '%commit%' SET GLOBAL autocommit = 0(记得手动开启,手动提交) 查看隔离级别: SHOW GLOBAL VARIABLES LIKE '%iso%' 或 SELECT @@global.tx_isolation 注意:服务器端修改 transaction-tx_isolation 建议:对事务要求不特别的严格,可以使用读题交 MySQL如何实现: MVCC:多版本并发控制的内在机制实现的 每个事务启动时,InnoDB为每个启动的事务提供一个当下的快照,后续的操作,都在快照上操作 为了实现此功能,InnoDB 会为每个表提供两隐藏的字段: 一个用于保存行的创建时间,一个用于保存行的失效时间 里面存储的是系统版本号: 只在两个隔离级别下有效:读提交,可重读(默认) MySQL存储引擎: SHOW ENGINES; SHOW TABLES STATUS [LIKE ''] [WHERE 语句] SHOW TABLES STATUS IN hellodb; SHOW TABLE STATUS IN hellodb WHERE name='classes'G :查看库中某个表的引擎 *************************** 1. row *************************** Name: classes 表名 Engine: InnoDB 存储引擎 Version: 10 版本 Row_format: Compact 行格式(创建表的时候有)ROW_FORMAT [=] {DEFAULT|DYNAMIC|FIXED|COMPRESSED|REDUNDANT|COMPACT} 表格式 Rows: 9 表中的行数,innodb未必精确,mvcc机制导致可能存在镜像 Avg_row_length: 1820 行的平均长度(字节) Data_length: 16384 表的数据总体大小 Max_data_length: 0 表的最大空间 Index_length: 0 索引的最大长度 Data_free: 9437184 可以用来存储的空间,但是未用的空间,也包括删除行释放的空间 Auto_increment: 10 自动增长(下一ge的值) Create_time: 2018-10-26 11:52:27 表创建时间 Update_time: null 表数据的最近一次的修改时间 Check_time: NULL 使用CHECK TABLE 或myisamchk最近一次检测标的时间 Collation: utf8_general_ci 排序规则 Checksum: NULL 如果启用,则为表的checksum Create_options: 创建表时指定的其他选项 Comment: 表的注释、如果是视图,显示VIEW,其他的为NILL 存储引擎也通常称为’表类型‘ MyISAM: db_name.frm db_name.MYD db_name.MYI InnoDB: 第一种格式:innodb_file_per_table=off 共享表空间 ibdata # 达到一定大小,启动新的(数据目录下) tb_name.frm 第二种;innodb_file_per_table=on 独立表空间 每个表在数据库目录下存储两个文件 tb_name.frm tb_name.idb 表空间:table space 由InnoDB管理的特有格式数据文件,Innodb使用聚簇索引 show engines; SHOW VARIABLES LIKE '%ENGINE%'; default_storage_engine 服务变量实现 各存储引擎的特性:存储引擎比较:https://docs.oracle.com/cd/E17952_01/mysql-5.5-en/storage-engines.html 事务日志:随机IO 改为顺序IO(是一段连续的空间) 数据目录下 ib_logfile{1,0},一般是两个 InnoDB: 事务:事务日志 外键: MVCC: 聚簇索引: 聚簇索引之外的索引,通常称为 辅助索引,不是指向数据,而是指向聚餐索引的 聚簇索引和数据是存放在一块的。一张表,聚簇索引只能有一个。否则就会乱套 辅助索引可以多个。 辅助索指针指向的是聚簇索引(InnoDB) 辅助索引 ---> 聚簇索引 ---> 数据本身 主键 作为聚簇索引。 辅助索引、聚簇索引 是基于位置的。 辅助索引、聚簇索引都是 B+tree 索引(也就是说内部结构) 行级锁:间隙锁 支持辅助索引 支持自适应的hash索引 支持热备份 MyISAM: 全文索引 (Mroonga引擎) 压缩(做数据仓库,节约空间,IO次数减少) 空间索引(通过空间函数) 表级锁 延迟更新索引 不支持事务 不支持外键 不支持MVCC 不支持行级锁 奔溃后,无法安全恢复 使用场景:只读数据(数据仓库),较小的表,能忍受数据丢失(崩溃后,数据恢复能力差,非事务) ARCHIVE: 仅支持INSERT 和 SELECT 支持很好的压缩 适用于存储日志信息,或其他按时间序列实现的数据采集类的应用。 支持行级锁和专用缓存区 CSV: CSV存储引擎使用逗号分隔值格式将数据存储在文本文件中。可以使用 CSV引擎以CSV格式导入和导出其他软件和应用程序之间的数据交换 不支持数据索引 仅适用于数据交换场景 BLACKHOLE : 黑洞存储引擎接受但不存储数据,检索总是返回一个空集。该功 能可用于分布式数据库设计,数据自动复制,但不是本地存储 没有存储机制,常用于多级复制架构中做中转服务区 MEMORY: 保存数据在内存中,内存表,实现临时表,保存中间数据,周期性的聚合数据等。 仅支持hash索引,适用表级锁,不支持BLOB 和text数据类型 MRG_MYISAM: 把两个MyISAM连到一起,能够将多个MyISAAM合并成一个虚表 NDB: MySQL CLUSTER 中专用的存储引擎 第三方存储引擎: OLTP:在线事务处理: XtraDB:增强版的InnoDB, 由Percona提供 编译安装时,下载xtradb 的原码 替换mysql存储引擎中的InnoDB的原码 PBXT:MariaDB自带 支持引擎级别的复制操作 支持引擎级别的外加约束, 对SSD磁盘提供适当支持 支持MVCC TokuDB: 使用Fractal Trees索引,没有锁片问题,适合在大数据领域,有和好的压缩比 被引入 MariaDB 列式存储引擎: Infobright:目前较有名的劣势引擎,适用于海量数据存储场景,PB级别的,专为数据分析和数据仓库设计 InfiniDB MonetDB LucidDB 开源社区存储引擎: Aria:前身Maria, 可理解为增强版的MyIS AM ,支持奔溃后恢复,支持数据缓存 Groona:全文索引引擎,用在搜索引擎上。Mroonga是改进版 QQGraph:Open Query开发,支持图结的存储引擎 SphinxSE:整合到MariaDB 中,全文搜索服务器提供了sql接口 Spider:将数据切片,能将数据分成不同的切片,比较透明的实现了分片,并支持在分片上支持并行查询 如何选择: 是否需要事务 是否需要备份,以及备份类型 崩溃后的恢复 ; 特有的特性(如,利用特有特性) 如果多个要求一致,做性能测试,再做出选择 索引类型: 聚簇索引 辅助索引 B树索引 R树索引 hash索引 全文索引 Mysql用户管理: 用户账号: username@hostname, password 用户账号管理: CREATE USER DROP USER RENAME USER SET PASSWORD 权限管理: GRANT:同时还可以创建用户 REVOKE: CREATE TEMPORARY TABLES:创建临时表,内存中 SHOW PROCESSLIST:显示当前运行的所有线程(跟用户相关的)mysqladmin那块有提到 MySQL权限级别: 库级别: 表级别: 字段级别: 管理类: CREATE USER CREATE USER username@hostname [ IDENTIFIED BY [PASSWORD] 'password' ] CREATE USER test@'192.168.%.%' IDENTIFIED BY '123456' 主机可以使用通配符: testuser@'192.168.100.1__' ----> 100-199 查看用户能都使用的权限: SHOW GRANTS FOR 'test'@192.168.%.%'; RENAME USER .... TO ...: RENAME USER 'test1'@'192.168.%.%' TO 'jack'@'192.168.%.%' SET: SET PASSWORD [FOR user] = { PASSWORD('cleartext password') | OLD_PASSWORD('cleartext password') | 'encrypted password' } SET PASSWORD FOR 'bob'@'%.example.org' = PASSWORD('cleartext password'); GRANT: 管理类权限: CREATE TEMPORARY TABLES CREATE USER FILE SHOW DATABASES SHUTDOWN SUPER REPLICATION SLAVE 复制 REPLICATION CLIENT LOCK TABLES PROCESS 数据库级别,表级别 的权限: ALTER:修改表 ALTER ROUTINE:修改存储函数,存储过程 CREATE :创建表,库 CREATE ROUTEINE CREATE VIEW 视图 DROP:删除表,库 EXECUTE:执行函数或存储过程 GRANT OPTION:转增权限 INDEX: SHOW VIEW:是否有权限查看view 数据操作(表级别: SELECT INSERT UPDATE DELETE 字段相关的: SELECT (col,...) UPDATE(COl ,....) INSERT(col, ....) 命令: GRANT priv_type [(column_list)] [, priv_type [(column_list)]] ... ON [object_type] priv_level TO user_specification [, user_specification] ... [REQUIRE {NONE | ssl_option [[AND] ssl_option] ...}] [WITH with_option ...] GRANT PROXY ON user_specification TO user_specification [, user_specification] ... [WITH GRANT OPTION] object_type: TABLE | FUNCTION | PROCEDURE priv_level: * | *.* | db_name.* | db_name.tbl_name | tbl_name | db_name.routine_name user_specification: user [ IDENTIFIED BY [PASSWORD] 'password' | IDENTIFIED WITH auth_plugin [AS 'auth_string'] ] ssl_option: SSL with_option: GRANT OPTION | MAX_QUERIES_PER_HOUR count 多少次查询 | MAX_UPDATES_PER_HOUR count 更新次数 | MAX_CONNECTIONS_PER_HOUR count 最大建立个数 | MAX_USER_CONNECTIONS count 使用同一个账户,同时连接几次 GRANT CREATEE ON hellodb.* TO 'test'@'%' IDENTIFIED BY '123456' 获得创建库的权限,必须对库的所有表有权限,才能创建库 REVOKE:收回授权: REVOKE priv_type [(column_list)] [, priv_type [(column_list)]] ... ON [object_type] priv_level FROM user [, user] ... REVOKE ALL PRIVILEGES, GRANT OPTION FROM user [, user] ... REVOKE CREATE ON test.t FROM test@'%' 授权信息表: mysql库下的 db:库级别的权限 host:主机级别,废弃 tables_priv:表级别 colomns_priv:列级别的 procs_priv:存储过程和存储函数相关的授权 proxies_priv:代理用户的权限 FLUSH!!!!!!!!!!!!! 如果连接多次被拒绝了,需要清理一下host文件 如果root用户密码忘了? 配置mysqld中添加:skip-grant-tables 如何从mysql 升级到 mariadb MySQL查询缓存: 用于保存Mysql 查询语句返回的完整结果,被命中时,Msyql 会立即返回,省去解析,优化,执行等过程。 如何检查缓存: Mysql保存数据于缓存中: 把select语句本身做hash计算,计算的结果作为key,查询的结果作为value 次数命中率,字节命中率 什么样的语句不能被缓存: 查询语句中有一些不确定数据,用户自定义函数,存储函数,用户定义变量,临时表,系统表,或权限表 缓存带来的额外开销: 1、每个查询都得先查询是否命中 2、查询结果先缓存 3、内存有限,而且还要分配内存大小,lru删除,还可能产生内存碎片等等 mysql> show global variables like 'query_cache%'; +------------------------------+----------+ | Variable_name | Value | +------------------------------+----------+ | query_cache_limit | 1048576 | | query_cache_min_res_unit | 4096 | | query_cache_size | 16777216 | | query_cache_type | ON | | query_cache_wlock_invalidate | OFF | +------------------------------+----------+ query_cache_type:查询缓存类型,是否开启缓存功能,开启方式有三种,ON, OFF ,EDMAND DEMAND SELECT SQL_CACHE .... select语句只有加SQL_CACHE这句,才缓存 query_cache_size:缓存使用的总空间,单位字节,大小是1024的整数倍 mysql启动时,一次性分配,并立即初始化这里的指定大小空间 如果修改此大小,会清空全部缓存,并重新初始化 query_cache_min_res_unit:存储缓存的最小内存块 (query_cache_size - Qcache_free_memory)/Qcache_queries_in_cache 获取一个理想值 query_cache_limit:一个查询语句缓存的最大值(先缓存,如果超过了,再删除 ,又降低性能) 手动使用SQL_NO_CACHE 可以人为的避免尝试缓存返回结果超出此参数限定值的语句 query_cache_wlock_invalidate: 如果某个表被其他的用户锁住,是否从缓存中返回结果,OFF 表示返回。 如何判断命中率: 次数命中率: 状态变量是统计值,服务器变量是设定值******** SHOW GLOBAL STATUS LIKE 'Qcache%' mysql> SHOW GLOBAL STATUS LIKE 'Qcache%'; +-------------------------+----------+ | Variable_name | Value | +-------------------------+----------+ | Qcache_free_blocks | 1 | | Qcache_free_memory | 16759696 | | Qcache_hits | 0 | | Qcache_inserts | 0 | | Qcache_lowmem_prunes | 0 | | Qcache_not_cached | 3 | | Qcache_queries_in_cache | 0 | | Qcache_total_blocks | 1 | +-------------------------+----------+ Qcache_hits:命中次数 Qcache_free_memory:尚且空闲的空间,尚未分配 事先申请好的内存空间: Qcache_free_blocks:空闲块数 Qcache_total_blocks:总块数 Qcache_queries_in_cache:缓存中缓存的查询个数 Qcache_inserts :缓存插入次数 Qcache_not_cached :没有缓存的 Qcache_lowmem_prunes:内存太少,修剪(腾出)内存的次数 碎片整理: FLUSH QUERY_CACHE: 把小的集合起来 清空缓存: RESET: 命中率的估算方式: mysql> SHOW GLOBAL STATUS WHERE variable_name='Qcache_hits' OR variable_name='com_select'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | Com_select | 3 | | Qcache_hits | 0 | +---------------+-------+ 缓冲命中,Com_select是不会增加 所以命中率 Qcache_hits / (Qcache_hits + Com_select) 也参考另外一个指标:命中和写入的比率 Qcache_hits / Qcache)inserts 的值,大于3 表示缓存是有效的。 缓存优化使用的思路: 1、批量写入,而非多次单个写入 2、缓存空间不宜过大,因为大量缓存失效,会导致服务器假死 3、必要时,使用SQL_CACHE 和SQL_NO_CACHE 手动控制缓存 4、对写密集型的应用场景来说,警用缓存反而能提高性能 M有SQL日志: 查询日志:查询相关的信息 慢查询日志:查询执行时长超过指定时长的查询,未必是语句查询慢,可能被其他线程阻塞 错误日志:启动,关闭,复制线程(从服务器) 二进制日志:mysql中引起数据变化,mysql服务器改变的信息(修改的信息)MySQL复制的基本凭据 中继日志:保存在从服务器上的日志,跟主服务器上的二进制日志相同,用完可以删除。 事务日志:已提交数据,保存,未提交数据,回滚。 随机IO 转换为 顺序IO 日志文件组:至少有两个日志文件 注意:尽可能使用小事务 因为,如果事务大,事务日志中放不下,就会存到磁盘中,但是如果回滚,磁盘中的也得删除,这样,开销就会增大 ib_logfile{1|0} 两个 InnoDB_buffer支持read操作 如何尽量保证事务日志和数据的安全: 1、磁盘,事务日志,分别放在raid上(raid 10, 或raid 1) 2、做镜像 mysql> show global variables like 'innodb%'; +---------------------------------+------------------------+ | Variable_name | Value | +---------------------------------+------------------------+ | innodb_log_buffer_size | 8388608 | | innodb_log_file_size | 5242880 | | innodb_log_files_in_group | 2 | | innodb_log_group_home_dir | ./ | | innodb_max_dirty_pages_pct | 75 | | innodb_max_purge_lag | 0 | | innodb_mirrored_log_groups | 1 | | innodb_old_blocks_pct | 37 | | innodb_old_blocks_time | 0 | 查询日志;默认关闭 ---- 一般不要开启 (动态变量) log = ON|OFF 是否记录所有的语句的日志信息与一般产需日志文件(general_log) log_output = TABLE| FILE | NONE :TABLE 和FILE 可以同时出现,用逗号分隔 general_log:是否启用查询日志 general_log_file:定义了一般查询日志保存文件 ---一般是 主机名。log 此选项 ,取决 log_output 是什么类型,只有FILE 的时候,次选项才能生效 开启:(两个都得打开) SET GLOBAL log='ON' SET GLOBAL general_log='ON' 记录到数据库: SET GLOBAL log_output=’table'; mysql.general_log 表中 慢查询日志: mysql> show global variables like 'long%'; 指定时间,多长时间才算慢 +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ slow_query_log OFF|ON 是启用慢查询 ,输出位置取决于log_ouput=FILE| TABLE| NONE log_slow_queries ON|OFF slow_query_log_file /mydata/data/node1-slow.log 如果log_ouput = FILE保存位置 记录到: mysql.low_log查看 错误日志: 服务器启动和关闭信息: 服务器运行中的错误信息 事件调度器运行一个事件产生的信息; 在复制架构中从服务器上启动从服务器线程时产生的信息; log_error /mydata/data/node1.err log_warnings 1 :是否记录警告信息 二进制日志:记录的是,可能修改数据,或修改数据的信息 一般在数据目录下 使用 mysqlbinlog 查看 position:位置 time:时间 滚动:每一个日志文件不能过大 1、按照大小 2、按照时间 3、按照服务器启动 SHOW BINARY LOGS; 从开始到当前mysql服务器使用了的二进制文件 记录在 x.index文件中 功能: 时间点恢复: 复制: PURGE:删除日志 PURGE { BINARY | MASTER } LOGS { TO 'log_name' | BEFORE datetime_expr } 示例: PURGE BINARY LOGS TO ‘mariadb-bin.000003’;删除3之前的日志 PURGE BINARY LOGS BEFORE '2017-01-23'; PURGE BINARY LOGS BEFORE '2017-03-22 09:25:30'; 删除所有二进制日志,index文件重新记数 RESET MASTER [TO #]; 删除所有二进制日志文件,并重新生成日志文 件,文件名从#开始记数,默认从1开始,一般是master主机第一次启动时执行,MariaDB10.1.6开始支持TO # SHOW MASTER STATUS;查看日志信息 FLUSH LOGS;重启一个新的日志文件,滚动日志 SHOW BINARY LOGS; mysql> SHOW BINARY LOGS; +---------------+-----------+ | Log_name | File_size | +---------------+-----------+ | binlog.000015 | 724935 | | binlog.000016 | 733481 | +---------------+-----------+ SHOW BINLOG EVENTS 查看二进制文件 SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count] eg: SHOW BINLOG EVENTS IN 'aria_log.00000001' SHOW BINLOG EVENTS IN 'aria_log.00000001' FROM 66761: 从指定的位置查看 mysqlbinlog: --start-time --stop-time --start-poditon --stop-positon mysqlbinlog --start-positon= mysql-bin.log000001 > /a.sql server-id: 服务器身份标识 Mysql记录二进制日志格式有两种: 1、基于语句:statment, 2、基于行:row:更精确 CURRENT_DATE():这种,只能基于行,基于语句,时间就不对了 3、混合模式:mixed 二进制日志文件的内容格式: 时间发生的时间和日期 服务器的ID 事件的结束位置 事件的类型 原服务器生成此事件的线程ID 语句的时间戳和写入二进制日志文件的时间差 错误代码 事件内容 事件位置,也就是下一个事件的开始位置 服务器参数: log-bin log-bin-trust-function-creators sql_log_bin sync_binlog:记录缓冲的 多久同步到磁盘中,0 不同步 log-bin = {ON|OFF|path} 文件路径,哪个路径下的文件中 ON 默认 mysql...00001 sql_log_bin = {ON|off} 会话级别参数,是否记录到二进制文件中,只有SUPER权限才可以修改 binlog_format = {statement | row|mixed} max_binlog_cache_size = 二进制日志缓冲空间大小,仅用于缓冲实物类的语句 max_binlog_stmt_cache_size = 非事务类和事务类 共用的空间大小 max_binlog_size 二进制日志文件的大小 建议:二进制日志 与 数据文件 不要放在同一设备上 中继日志: relay-log | relay_log | relay_log_index | relay_log_info_file relay-log.info | relay_log_purge ON 是否清理不用的中继日志 | relay_log_recovery OFF | relay_log_space_limit 0 空间大小是否有限定 备份 和 恢复: 1、灾难恢复 2、审计 (某一数据在某一时刻是什么样的) 3、测试 备份:目的用于恢复,对备份数据做定期的恢复测试 备份类型: 根据备份时,服务器是否在线: 冷备:离线状态 热备:基于事务的 温备:全局施加共享锁,阻止写 根据备份的数据集: 完全备份: 部分备份: 根据备份时的接口(直接备份数据文件还是通过mysql服务器导出数据) 物理备份:直接复制数据文件的备份方式,存储引擎必须一致 逻辑备份:把数据从库中提取出来保存为文本文件,可以基于网络恢复,与存储引擎无关,避免数据恢复 缺点:速度慢,占据空间大。无法保证浮点数的精度,还原回来的数据需要 重建索引。(不适合数据量大的,慢) 工具:mysqldump 根据备份时是备份变化数据,还是整个数据: 完全备份; 增量备份: | |_________1________2________3 |---------> -------> --------> 完全备份 + 增量备份 + 二进制即使点恢复 + 回滚 差异备份:(容易备份) | |_________1________2________3 |---------> |------------------> |----------------------------> 备份策略: 选择备份时间,备份方式,备份成本(锁时间,备份时长,备份负载),恢复成本 备份对象: 数据; 配置文件 代码:存储过程,存储函数,触发器 OS相关的配置文件:crontabl配置计划及相关脚本 跟复制先关的配置信息 二进制日志文件。 常用的工具: mysqldump:逻辑备份工具 InnoDB 热备,MyISAM温备,Aria温备 备份和恢复时间较慢 mysqldumper:多线程MySQLdump 很难实现差异或增量备份; lvm-snapshot: 接近于热备的工具:因为要先请求全局所,而后创建快照,并在创建快照完成后释放全局锁 cp,tar等工具物理备份, 备份和恢复速度快 无法做增量备份,请求全局锁需要等待一段时间 SELECT:部分备份工具: SELECT 语句 INTO OUTEFILE '/path/to/somefile' 恢复:LOAD DATA INFILE '/path/to/somefile' 仅备份数据,不会备份关系 Innobase:商业备份,innobackup Xtrabackup:由percona提供的开源备份工具。 InnoDB热备,增量备份 MyISAM温备,完全备份,不支持增量 物理备份,速度快 mysqlhotcopy:几乎冷备 具体使用 mysqldump:逻辑备份时文本信息,可以二次编辑 还原的时候如果库不在,需要手动闯将 步骤:备份单个库(备份的文件里没有创建库的语句,所以建议使用--databases 1、mydqldump -uroot -hlocalhost -p hellodb > /tmp/bdb.sql /tmp/bdb.sql 是可以vim打开,二次编辑 2、恢复的时候,先创建库, CREATE DATABSE hellodb 3、导入:mysql-uroot -hlocalhost -p hellodb < /tmp/bdb.sql 步骤:备份所有库 msyqldump --all-databases > /tmp/all.sql 步骤:部分指定的多个库,不需要手动创建库 mysqldump --databases db1 db2 > /tmp/m.sql 注意:备份前要加锁 --lock-all-tabes:请求锁定所有表之后备份(读锁),对MyISAM,InnoDB,Aria 做温备 --single-transaction:能够对InnoDB引擎 实现热备(就不用--lock-all-tabes) 备份代码: --events:备份事件调度器代码 --routines:备份存储过程和存储函数 --triggers:备份触发器 备份时 滚动日志: --flush-logs:备份前,请求到锁之后滚动日志 复制时的同步标记: --master-data = 0,1,2 0:不记录 1:记录为CHANGE MASTER 语句 2:记录为是注释的CHANGE MASTER 的语句 使用mysqldump备份: 请求锁:--lock-all-tables或--singe-transaction 进行INNODB热备 滚动日志: --flush-logs 选定要被扥的库: --databases 指定二进制日志文件及位置 --master-data 实例: 手动施加全局锁: 1、FLUSH TABLES WITH READ LOCK:缓存中的同步到磁盘,同时施加全局读锁 2、FLUSH LOGS 3、SHOW MASTER STATUS 4、mysqldump --databases hdb > /tmp/hdb.sql 5、UNLOCK TABLES; mysqldump --databases hdb --lock-all-tables --flush-logs > /tmp/hdb2.sql (温备) 热备:(全是innodb引擎) mysqldump --databases hdb --single-transaction --flush-logs > /tmp/hdb2.sql 恢复: 即使点恢复 一次完成过程: 备份: 1、先查看 存储引擎: 2、 mysqldump --databases hdb --lock-all-tables --flush-logs --master-data=2 > /tmp/hdb2.sql (温备) 查看hdb2.sql 有一句:注释掉的语句: -- CHANGE MASTER TO MASTER_LOG_FILE='master-bin.00005',MASTER_LOG_POS=367 也就是说,下次即使点恢复,从此二进制文件的367位置开始往后 3、备份之后,又在表中插入数据等操作,而后,不小心把表删了 4、恢复到表删除之前: 4.1、先找到二进制文件,并备份保存 4.2、mysqlbinlog --start-positions=367 master-bin.00005 在里边找,不小心删除的语句之前的一个位置 4.3、保存二进制文件 mysqlbinlog --start-positions=367 --stop-positons=669 master-bin.00005 > /tmp/hdb2.inc.sql 4.4、因为不需要恢复的日志,不需要记录,所以先关掉, SET SESSION sql_log_bin=0 5、导入完全备份: SHOW MASTERS STATUS;查看位置对不 mysql> source /tmp/hdb2.sql 6、增量 恢复: mysql> source /tmp/hdb2.inc.sql 7、SET SESSION sql_log_bin=1 注:恢复,关闭二进制文件,关闭其他用户连接(关闭全局二进制日志) 备份策略:基于mysqldump 备份:mysqdump +二进制日志文件 周日做一次完全备份:备份的同时滚动日志(下次二进制就从新的文件开始) 周一-周六:备份二进制日志 恢复: 完全备份 +各二进制文件至此刻事件 lvm-snapshot: 快照卷,获得文件的一致性通路 作为原卷的访问路径, 刚创建是没有内容,指向原卷, 修改的数据,文件先复制到快照卷,未修改的来自原卷,修改的来自快照卷 1、事务日志 跟 数据文件 必须在同一个卷上,两个卷不能保证时间一致 2、创建快照卷之前,要请求全局锁; 快照创建完之后,释放锁 3、请求全局锁完成之后,做一次日志滚动。做二进制日志文件及位置标记 实例:/mydata/data 1、lvs 看下逻辑卷 LV VG mydata myvg 2、FLUSH LOGS WITH LOCK READ; 刷新日志,并施加锁 3、mysql -e 'show master status' > /binlog.pos 记录位置 4、lvcreat -L 100M -s -n mydata-snap -p -r /dev/myvg/mydata lvs :查看 5、unlock tables; 6、挂载 快照卷 mount /dev/myvg/mydata /mnt -o ro 7、之后又进行了操作,如插图数据 8、开始备份 cd /mnt/data/ cp data/ /backup/data-2018-10-25 -a (归档模式,保证原权限) 9、卸载快照卷 10、一不小心删了/mydata/data/ 11、二进制文件在 /mydata/binlog/ 12、到新电脑上,安装mysql 13、cp /backup/data-2018-10-25/* /mydata/data/ 确保权限mysql.mysql 14、启动mysqld 15、基于二进制还原 原电脑上 根据刚才记住的位置,和文件 导出二进制文件内容 mysqlbinlog --start-positions=367 /mydata/binlog/master-bin.000009 | mysql Xtrabackup(percona):实现增量备份 innobackupex:需要服务器处于运行状态 注意: 1、要将数据和备份放在不同的磁盘设备上,异机 或异地设备存储最为理想 2、备份的数据,应该周期性的进行还原测试 3、每一次灾难恢复后,都应该做一次完全备份 4、针对不同规模或级别的数量,要定制好备份策略 5、做好二进制日志备份,并跟数据 放在不同磁盘上, 从备份中恢复应该遵循步骤: 1、停止MySQL服务器(mysqldump不能) 2、记录服务器的配置和文件权限 3、将数据从备份移到MySQL数据目录中,执行方式,依赖于工具 4、改变配置和文件权限 5、以限制访问模块重启服务器,mysql的--skip-networking选项跳过网络功能 方法:编辑my.cnf skip-networking soket=/tmp/mysql-recorvery.socket 6、载入逻辑备份(如果有) ,而后检查和重放二进制日志 7、检查已经还原的数据 8、重新以完全访问模式重启服务器。 注释前面在my.cnf中添加的选项,并重启 SELECT .... INTO OUTEFILE '/tmp/stu.sql.txt' 这种方式需要手动创建表格式 testtb LOAD DATA INFILE '...' INTO TABLE testtb