=================第3周 超参数调试、Batch 正则化和程序框架===============
====3.1 调试处理===
对大部分机器学习应用而言,学习率alpha是需要调整的最重要的超参。
我的超参重要程度的直觉是,红色>黄色>紫色。第2和3行分别表示momentum和Adam的参数。
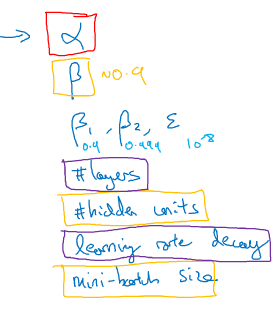
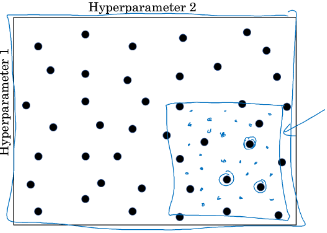
-随机搜索。随机sample超参组合,这么做的原因是,你很难一开始就知道哪个超参对你的问题来说是最重要的。举一个极端的例子,学习率alpha与epsi(Adam中防止分母为0的参数)的超参组合,5*5网格搜索发现epsi没什么影响,但只同时也只试验5个alpha值,但随机搜索就不同了。
-Coarse to fine。
====3.2 为超参选择合适的调参尺度范围====
-有些超参可以在线性范围内 随机均匀搜索,如某层的神经元个数,有些则需要在转化的尺度范围内 随机均匀搜索,如学习率,应在log线性范围内执行随机搜索(注意还是要随机!)。下图alpha为学习率,r为[-4,0]的随机数,alpha=10^r
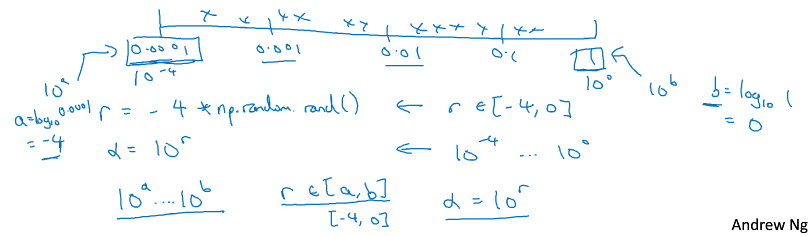
另一个例子,以指数加权平均的参数beta为例
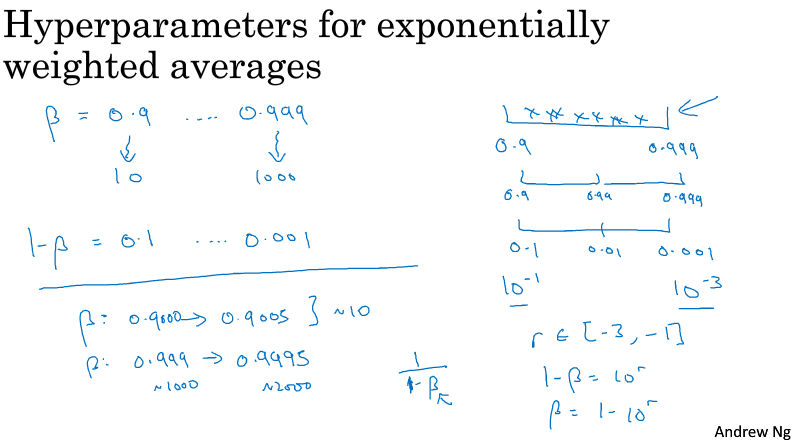
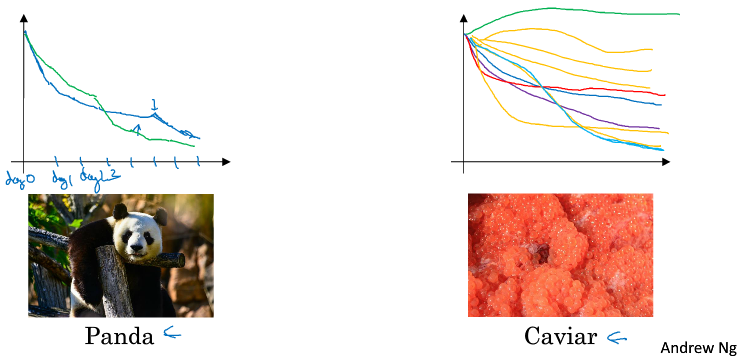
====3.3 超参数训练的实践:Pandas VS Caviar====
-在深度学习里,不同的研究领域开始相互交融,一个领域的研究方法有时 可以 / 不可以给另一个领域带来灵感,大家会跨领域阅读papers。
-但是就调参而言,Intuitions do get stale, Re-evaluate occasionally,即使在一个单一的研究问题上也是如此。
-根据你所拥有的计算资源,以及具体的application场景,通常有2种调参方式:
1.Babysitting one model. 计算资源不充足;另外有一些application,比如在线广告setting,CV,我们有如此多的data,要训练的模型非常巨大
2.Ttraining many models in parallel. 计算资源充足;
以调整学习率alpha为例,左图是逐天根据性能观察来手动改变alpha,右图是设置了一些超参后,让它们直接跑同时观察结果。虽然一次只能有一个panda宝宝,但有时我们在过了几星期之后需要babysitting另一个panda宝宝。
====3.4 正则化网络的激活函数====
-Batch normalization
makes your hyperparameter search problem much easier,
makes the neural network much more robust to the choice of hyperparameters, for there's a much bigger range of hyperparameters that work well,
will also enable you to much more easily train even very deep networks
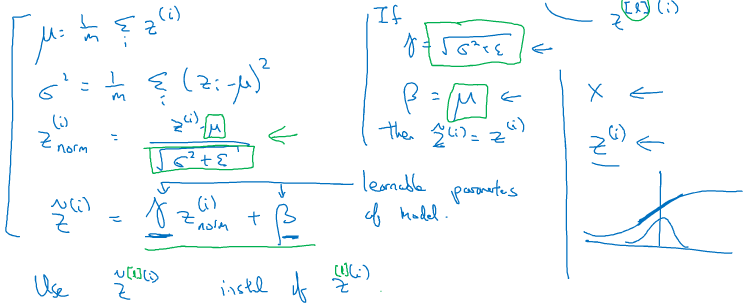
-实践中 经常做的是归一化Z,而不是激活值A。有时我们并不喜欢标准归一化,如下图右下方所示,如果激活函数值是sigmoid函数,我们并不希望大部分值全部集中在线性区域,我们希望多利用它的非线性部分。所以,Ztilde 多了两个参数,使得NN可以自己学习决定如何进行归一化。
====3.5 将 Batch Norm 拟合进神经网络====
working with mini-batch。
注意在BN中,因为Z减去平均值,其实Zi=WAi-1 + b 中的偏置 b 都会被减去。所以在使用BN中,可以省略偏置参数 b。这个偏置效果其实由上图的beta控制了
下面在求dgama和dbeta时没有除以1/m,是具体实现细节的问题,在python实现时已经对每个样本的导数除以对应的1/m,所以求dgama和dbeta时直接加一起就行了
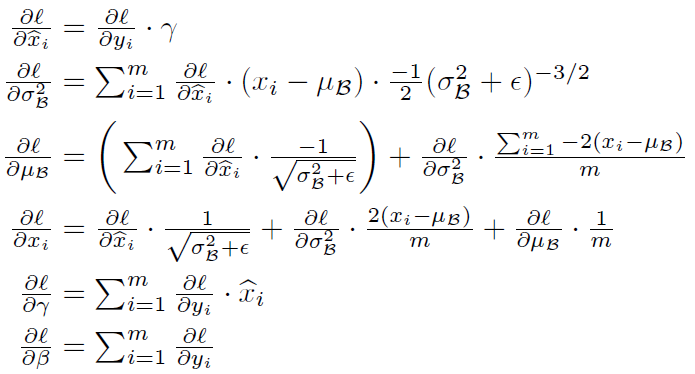
====3.6 Batch Norm 为什么奏效?====
1. 之前说过的,类似代价函数图由椭圆变成圆,加速收敛
2. Covariate shift问题。
It reduces the amount that the distribution of these hidden unit values shifts around (隐藏值分布的变化程度).
It limits the amount to which updating the parameters in the earlier layers can affect the distribution of values xth layer receives. It really causes these values to become more stable, so that the later layers of the neural network has more firm ground to stand on.
在某种程度上,每个层可以自己单独学习,a little bit more independently of other layers, 后层网络的学习变得更容易,这也有助于加速整个网络的学习
-某种程度的正则化效果。I wouldn't really use batch norm as a regularizer。

====3.7 测试时的 Batch Norm====
在实践中,任何合理的方式估算u和sigma,在测试中应该都会是有效的。但是人们通常使用指数加权平均

====3.8 Softmax 回归====
softmax激活函数,与之前介绍的sigmoid和relu这些激活函数不同,softmax激活函数接受的参数必须是一个向量!当然啦,因为它要计算一个概率分布嘛。
====3.9 训练一个 Softmax 分类器====
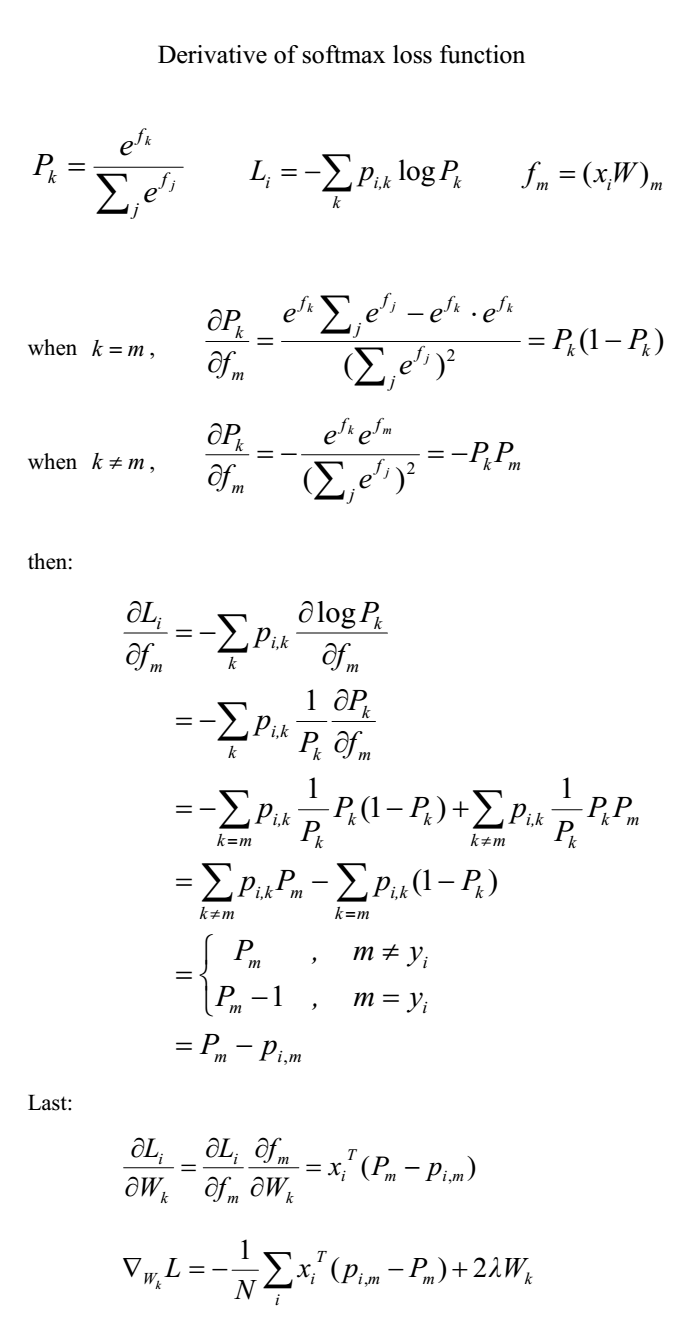
====3.10 深度学习框架====

====3.11 TensorFlow====
