0x00 概述
kafka server虽然原则上是兼容详细的client,但只是高版本的Server端兼容低版本的Client端;
在有高版本Client端连接时,会导致低版本Server集群会hang住,严重的话直接导致 kafka broker进程僵死,同时也会导致其他0.9.0.1的客户端僵死。
0x01 案发现场
1.1 生产端疯狂告警
在一个月黑风高的夜晚,我们kafka生产端开始疯狂告警,出现大量程序队列堵塞、数据写入失败、写入性能下降的告警。
-
程序Bug?
-
网络抖动?
-
集群抖动?
-
服务过载?
我们先看看生产端程序的日志:
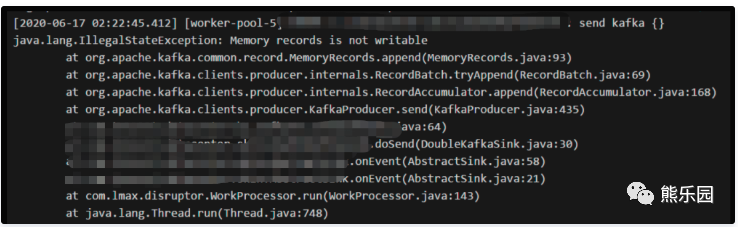
在生产端采用参数调优、增大并发、服务重启等一系列手段而无果后,我们将问题排查锁定在后端kafka集群。
1.2 集群异常日志与分析
我们看到服务端频繁有如下异常日志:
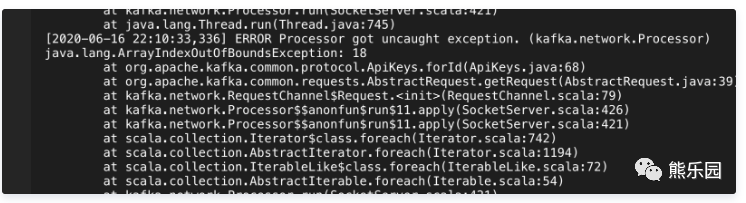
从google的信息来看,可能是由于高版本的客户端连接集群而发送了kafka服务端不支持的请求。
0x02 问题追踪与解决
2.1 开启Trace日志
正常日志级别下,日志是比较稀疏,我们把异常前一条相关日志的消费组提取出来进行分析,发现其完全是一个正常版本的客户端。且其日志时间与异常日志时间间隔较大(约7s),直接相关性不大。
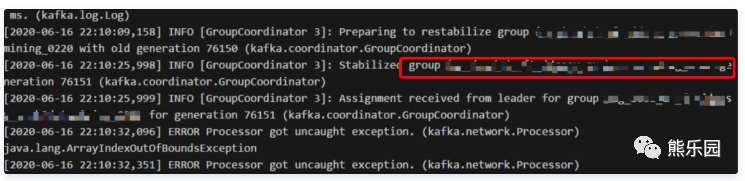
快速瞄了kafka服务端SocketServer.scala的源码得知: 想要精确查询到每个request日志需要开启trace日志。如图修改配置文件:
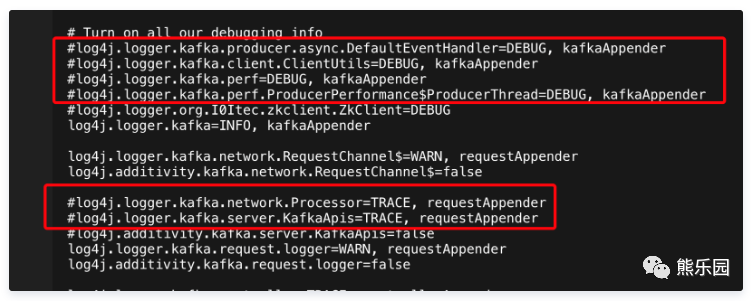
2.2 日志分析
我们检索server.log日志,进行分析

事后复盘时发现从kafka-request.log日志排查这类问题更方便一些
2.3 寻找异常任务
我们通过来源连接的ip与端口,定位到对应storm任务的日志,果然存在高版本客户端连接的问题。且任务启动时间与数据写入异常时间点完全吻合。
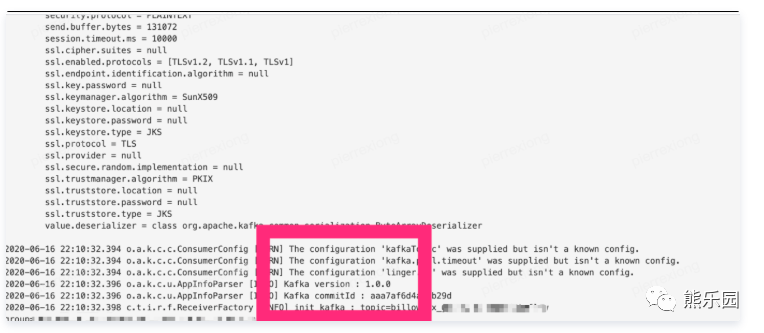
kill任务后集群逐渐恢复,数据写入恢复正常。
0x03 深入分析
现场临时恢复了,但我们对问题深入的分析才刚刚开始。
既然问题源自异常连接,那我们首先需要回顾一下kafka的网络通信模型。
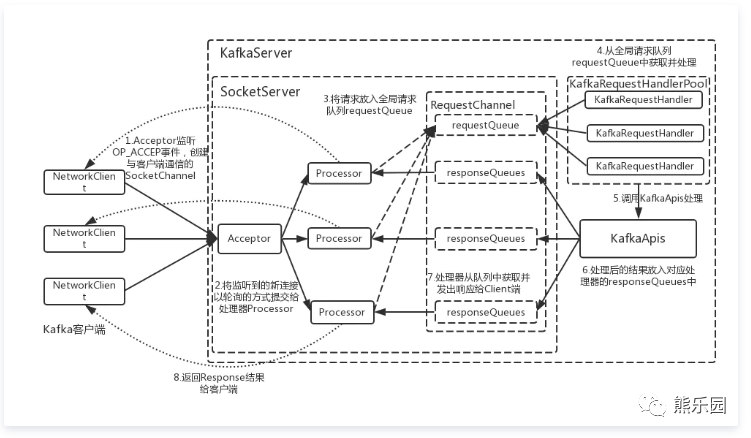
3.1 kafka的网络通信模型
熟悉kafka的同学都知道,kafka的网络通信模型是1(1个Acceptor线程)+N(N个Processor线程)+M(M个业务处理线程)。
|
线程数 |
线程名 |
线程具体说明 |
|---|---|---|
|
1 |
kafka-socket-acceptor_%x |
Acceptor线程,负责监听Client端发起的请求 |
|
N |
kafka-network-thread_%d |
Processor线程,负责对Socket进行读写 |
|
M |
kafka-request-handler-_%d |
Worker线程,处理具体的业务逻辑并生成Response返回 |
Kafka网络通信层的完整框架图如下图所示:
3.2 为什么会数组越界
从源码org.apache.kafka.common.protocol.ApiKeys可以看出0.9.0.1的kafka集群支持如下ApiKey的请求:
PRODUCE(0, "Produce"), FETCH(1, "Fetch"), LIST_OFFSETS(2, "Offsets"), METADATA(3, "Metadata"), LEADER_AND_ISR(4, "LeaderAndIsr"), STOP_REPLICA(5, "StopReplica"), UPDATE_METADATA_KEY(6, "UpdateMetadata"), CONTROLLED_SHUTDOWN_KEY(7, "ControlledShutdown"), OFFSET_COMMIT(8, "OffsetCommit"), OFFSET_FETCH(9, "OffsetFetch"), GROUP_COORDINATOR(10, "GroupCoordinator"), JOIN_GROUP(11, "JoinGroup"), HEARTBEAT(12, "Heartbeat"), LEAVE_GROUP(13, "LeaveGroup"), SYNC_GROUP(14, "SyncGroup"), DESCRIBE_GROUPS(15, "DescribeGroups"),
并将ApiKey整合成一个数组,这样getRequest()就能把客户端对应Apikey的请求引导到对应的处理方法。
static { int maxKey = -1; for (ApiKeys key : ApiKeys.values()) { maxKey = Math.max(maxKey, key.id); } codeToType = new ApiKeys[maxKey + 1]; for (ApiKeys key : ApiKeys.values()) { codeToType[key.id] = key; } MAX_API_KEY = maxKey; }
2.2.0对应的org.apache.kafka.common.protocol.ApiKeys发现,kafka随着版本升级已经新增了大量Apikey
SASL_HANDSHAKE(17, "SaslHandshake", SaslHandshakeRequest.schemaVersions(), SaslHandshakeResponse.schemaVersions()), API_VERSIONS(18, "ApiVersions", ApiVersionsRequest.schemaVersions(), ApiVersionsResponse.schemaVersions()) { @Override public Struct parseResponse(short version, ByteBuffer buffer) { // Fallback to version 0 for ApiVersions response. If a client sends an ApiVersionsRequest // using a version higher than that supported by the broker, a version 0 response is sent // to the client indicating UNSUPPORTED_VERSION. return parseResponse(version, buffer, (short) 0); } }, CREATE_TOPICS(19, "CreateTopics", CreateTopicsRequest.schemaVersions(), CreateTopicsResponse.schemaVersions()),
DELETE_TOPICS(20, "DeleteTopics", DeleteTopicsRequest.schemaVersions(), DeleteTopicsResponse.schemaVersions()),
DELETE_RECORDS(21, "DeleteRecords", DeleteRecordsRequest.schemaVersions(), DeleteRecordsResponse.schemaVersions()), INIT_PRODUCER_ID(22, "InitProducerId", InitProducerIdRequest.schemaVersions(), InitProducerIdResponse.schemaVersions()), OFFSET_FOR_LEADER_EPOCH(23, "OffsetForLeaderEpoch", false, OffsetsForLeaderEpochRequest.schemaVersions(), OffsetsForLeaderEpochResponse.schemaVersions()), ADD_PARTITIONS_TO_TXN(24, "AddPartitionsToTxn", false, RecordBatch.MAGIC_VALUE_V2, AddPartitionsToTxnRequest.schemaVersions(), AddPartitionsToTxnResponse.schemaVersions()), ADD_OFFSETS_TO_TXN(25, "AddOffsetsToTxn", false, RecordBatch.MAGIC_VALUE_V2, AddOffsetsToTxnRequest.schemaVersions(), AddOffsetsToTxnResponse.schemaVersions()), END_TXN(26, "EndTxn", false, RecordBatch.MAGIC_VALUE_V2, EndTxnRequest.schemaVersions(), EndTxnResponse.schemaVersions()), WRITE_TXN_MARKERS(27, "WriteTxnMarkers", true, RecordBatch.MAGIC_VALUE_V2, WriteTxnMarkersRequest.schemaVersions(), WriteTxnMarkersResponse.schemaVersions()), TXN_OFFSET_COMMIT(28, "TxnOffsetCommit", false, RecordBatch.MAGIC_VALUE_V2, TxnOffsetCommitRequest.schemaVersions(), TxnOffsetCommitResponse.schemaVersions()), DESCRIBE_ACLS(29, "DescribeAcls", DescribeAclsRequest.schemaVersions(), DescribeAclsResponse.schemaVersions()), CREATE_ACLS(30, "CreateAcls", CreateAclsRequest.schemaVersions(), CreateAclsResponse.schemaVersions()), DELETE_ACLS(31, "DeleteAcls", DeleteAclsRequest.schemaVersions(), DeleteAclsResponse.schemaVersions()), DESCRIBE_CONFIGS(32, "DescribeConfigs", DescribeConfigsRequest.schemaVersions(), DescribeConfigsResponse.schemaVersions()), ALTER_CONFIGS(33, "AlterConfigs", AlterConfigsRequest.schemaVersions(), AlterConfigsResponse.schemaVersions()), ALTER_REPLICA_LOG_DIRS(34, "AlterReplicaLogDirs", AlterReplicaLogDirsRequest.schemaVersions(), AlterReplicaLogDirsResponse.schemaVersions()), DESCRIBE_LOG_DIRS(35, "DescribeLogDirs", DescribeLogDirsRequest.schemaVersions(), DescribeLogDirsResponse.schemaVersions()), SASL_AUTHENTICATE(36, "SaslAuthenticate", SaslAuthenticateRequest.schemaVersions(), SaslAuthenticateResponse.schemaVersions()), CREATE_PARTITIONS(37, "CreatePartitions", CreatePartitionsRequest.schemaVersions(), CreatePartitionsResponse.schemaVersions()), CREATE_DELEGATION_TOKEN(38, "CreateDelegationToken", CreateDelegationTokenRequest.schemaVersions(), CreateDelegationTokenResponse.schemaVersions()),
RENEW_DELEGATION_TOKEN(39, "RenewDelegationToken", RenewDelegationTokenRequest.schemaVersions(), RenewDelegationTokenResponse.schemaVersions()),
EXPIRE_DELEGATION_TOKEN(40, "ExpireDelegationToken", ExpireDelegationTokenRequest.schemaVersions(), ExpireDelegationTokenResponse.schemaVersions()),
DESCRIBE_DELEGATION_TOKEN(41, "DescribeDelegationToken", DescribeDelegationTokenRequest.schemaVersions(), DescribeDelegationTokenResponse.schemaVersions()),
DELETE_GROUPS(42, "DeleteGroups", DeleteGroupsRequest.schemaVersions(), DeleteGroupsResponse.schemaVersions()),
ELECT_PREFERRED_LEADERS(43, "ElectPreferredLeaders", ElectPreferredLeadersRequestData.SCHEMAS,
从日志可以看出这次服务端数组越界的index是18,对应的客户端ApiVersions请求,从名字可以推测还是高版本kafka客户端的高频请求,而0.9.0.1只支持0~16的请求,所以有相关异常。
3.3 为什么会导致集群hang住
受益于java类语言的异常机制,scala程序还是相对健壮。我们需要深入研究一下为何一个小小的数组越界的影响范围超过了单次请求,甚至会导致整个集群不稳定。
借助日志,我们知道应该从SocketServer.scala的kafka.network.Processor入手(kafka基于java nio实现了高性能SocketServer,据说实现相对优美,有时间再细品)。
override def run() { startupComplete() while(isRunning) { try { // setup any new connections that have been queued up configureNewConnections() // register any new responses for writing processNewResponses() // 重写了selector try { selector.poll(300) } catch { case e @ (_: IllegalStateException | _: IOException) => error("Closing processor %s due to illegal state or IO exception".format(id)) swallow(closeAll()) shutdownComplete() throw e } selector.completedReceives.asScala.foreach { receive => try { val channel = selector.channel(receive.source) val session = RequestChannel.Session(new KafkaPrincipal(KafkaPrincipal.USER_TYPE, channel.principal.getName), channel.socketAddress) val req = RequestChannel.Request(processor = id, connectionId = receive.source, session = session, buffer = receive.payload, startTimeMs = time.milliseconds, securityProtocol = protocol) requestChannel.sendRequest(req) } catch { // 重点,这里没有捕获数组越界异常!导致被外围的异常捕获,后续逻辑没有处理 case e @ (_: InvalidRequestException | _: SchemaException) => // note that even though we got an exception, we can assume that receive.source is valid. Issues with constructing a valid receive object were handled earlier error("Closing socket for " + receive.source + " because of error", e) close(selector, receive.source) } selector.mute(receive.source) } selector.completedSends.asScala.foreach { send => val resp = inflightResponses.remove(send.destination).getOrElse { throw new IllegalStateException(s"Send for ${send.destination} completed, but not in `inflightResponses`") } resp.request.updateRequestMetrics() selector.unmute(send.destination) } selector.disconnected.asScala.foreach { connectionId => val remoteHost = ConnectionId.fromString(connectionId).getOrElse { throw new IllegalStateException(s"connectionId has unexpected format: $connectionId") }.remoteHost // the channel has been closed by the selector but the quotas still need to be updated connectionQuotas.dec(InetAddress.getByName(remoteHost)) } } catch { // We catch all the throwables here to prevent the processor thread from exiting. We do this because // letting a processor exit might cause bigger impact on the broker. Usually the exceptions thrown would // be either associated with a specific socket channel or a bad request. We just ignore the bad socket channel // or request. This behavior might need to be reviewed if we see an exception that need the entire broker to stop. case e : ControlThrowable => throw e case e : Throwable => error("Processor got uncaught exception.", e) } } debug("Closing selector - processor " + id) swallowError(closeAll()) shutdownComplete() }
SocketServer有小段的异常捕获,假如单端异常影响范围是有限。但是在第二小段的异常捕获却没有捕获数组越界异常,直接导致其被外围的异常捕获退出而不处理接下来的逻辑,从而会漏处理一些Request,从而导致一些关键的Request异常(如broker之间通信、生产程序与broker通信),从而导致整个集群出现问题数据写入异常。
0x04 事后总结
这次问题本质上是0.9.0.1版本kafka的bug。
总所周知,kafka虽然原则上是支持向下兼容,但只是高版本的服务端兼容低版本的客户端。在有高版本客户端连接时,集群会hang住,严重的话直接导致broker进程僵死,同时也会导致其他0.9.0.1的客户端僵死。
4.1 改进方案一览表
|
周期 |
改进方案 |
|---|---|
|
短期 |
做好宣导和力所能及的管控: 严禁用户使用高版本客户端连接集群;kafka服务端对数组越界的日志进行监控告警 |
|
中期 |
评估是否可以对kafka服务端代码打补丁 |
|
长期 |
升级或迁移到高版本集群 |
4.2 rdkafka解决方案
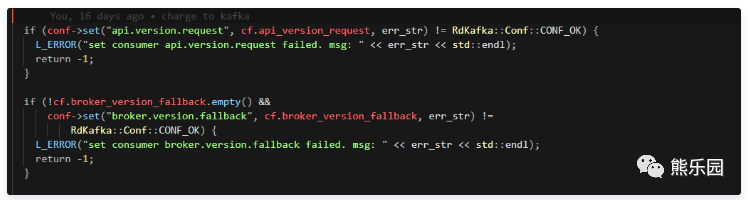
使用c++客户端rdkafka消费我们0.9的kafka。经过沟通后,使用如下方法安全连接到kafka集群,供大家参考:
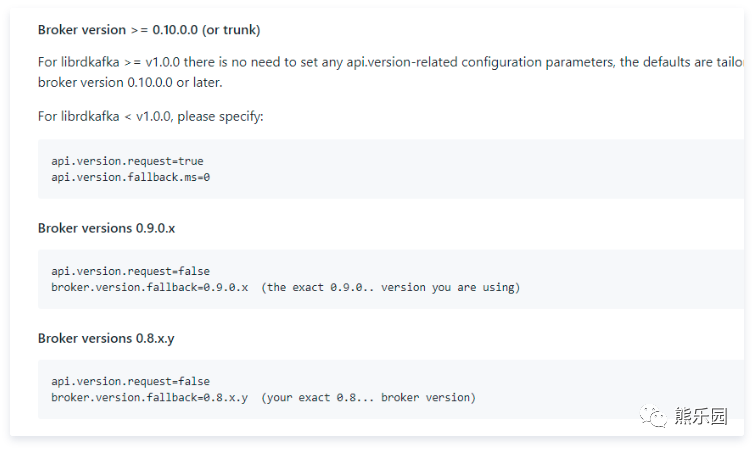
在rdkafka构建配置conf时,把api.version.request=false配置下,就可以了。
0x05 参考
-
https://www.jianshu.com/p/d2cbaae38014
-
https://www.imooc.com/article/36519
-
《kafka.network.Processor throws ArrayIndexOutOfBoundsException》https://issues.apache.org/jira/browse/KAFKA-359