Hadoop:一个开源的、可运行于大规模集群上的分布式计算平台。实现了MapReduce计算模型和分布式文件系统HDFS等功能,方便用户轻松编写分布式并行程序。
Hadoop生态系统:
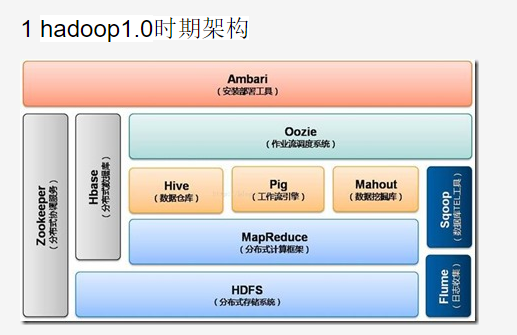
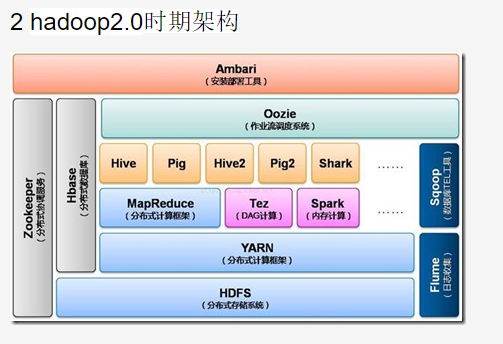
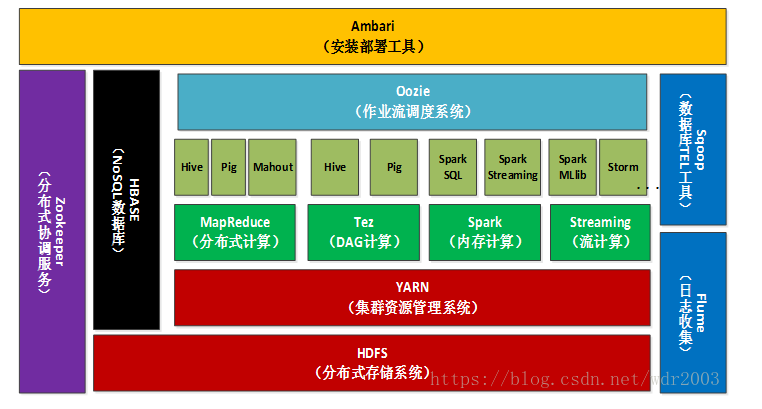
- HDFS:Hadoop 分布式文件系统,是Hadoop项目的两大核心之一。
- HBase:提供高可靠性、高性能、可伸缩、实时读写、分布式的列数据库,一般采用HDFS作为其底层数据存储,用于存储非结构化数据。
- MapReduce:一种并行编程模型,将复杂的、运行于大规模集群上的并行计算过程高度抽象到Map和Reduce上,方便用户进行分布式编程。MapReduce的核心思想是“分而治之”,把输入的数据集切分成若干独立的数据块,分发给集群中各个节点来共同完成。
- Hive:一个基于Hadoop的数据仓库工具,可以对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储,提供类似关系数据库的查询语言。
- Pig:一种数据流语言和运行环境,适用于使用Hadoop和MapReduce平台来查询大型半结构化数据集。为了Hadoop应用程序提供了一种更加接近结构化查询语言(SQL)的接口,适用于从大型数据集中搜索满足某个给定搜索条件的记录。
- Mahout:提供一些可扩展的机器学习领域经典算法的实现,如聚类、分类、推荐过滤等。
- Zookeeper:高效且可靠的系统工作系统,提供分布式锁之类的基本服务(如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等)。用于构建分布式应用,负责任务协调。
- Flume:一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。
- Sqoop:(SQL-to-Hadoop)用于在Hadoop和关系数据之间交换数据,便于传统关系数据库与Hadoop之间的数据迁移。Sqoop可以方便地将数据从MySQL等关系数据库中导入Hadoop(可以导入HDFS、HBase或Hive),或者将数据从Hadoop导出到关系数据。
- Ambari:一种基于Web的工具,支持Hadoop集群的安装、部署、配置和管理。
大数据时代的主要任务就是发现海量数据中的价值,为达到这一目的,首先要做的就是对这些数据进行存储,记录数据本身,接下来就是对手里的海量数据进行处理,发现其中价值。因此,大规模数据集的处理包括分布式存储和分布式计算两个核心环节,用于解决大数据领域中两方面问题,一个是大规模数据的高效存储与管理问题,针对这一问题Hadoop主要采用HDFS、NoSQL等对数据进行存储;另一个是大规模数据的高效处理问题,针对这一问题的主要技术包括MapReduce,
分布式并行编程可以大幅度提高程序性能,实现高效的批量数据处理。MapReduce是一种并行编程模型,、用于大规模数据集的并行运算,它将大规模集群上的并行计算过程高度抽象到Map和Reduce两个函数中,极大地方便了分布式并行编程工作。