前面介绍了Hadoop核心组件HDFS和MapReduce,Hadoop发展之初在架构设计和应用性能方面仍然存在不足,Hadoop的优化与发展一方面体现在两个核心组件的架构设计改进,一方面体现在Hadoop生态系统其他组件的不断丰富。此文介绍Hadoop2.0中添加的新特性。
一、HDFS 2.0新特性
这对HDFS的改进,HDFS 2.0主要增加了HDFS HA 以及HDFS联邦等新特性。
(一)HDFS HA
HA即High Availability,用于解决HDFS 1.0中的单点故障问题。
HDFS 1.0中,存在一个名称节点,一个第二名称节点,第二名称节点不是名称节点的备份,它的主要功能是解决当数据操作记录较多时,EdlirLog文件过大的问题,并不能提供热备份功能,当名称节点故障时无法提供实时切换,第二名称节点不能立即对外提供服务,需要停机恢复。
一旦唯一的名称节点出现故障,就会导致整个集群不可用,这就是“单点故障问题”。为解决这一问题,HDFS 2.0采用HA架构,集群包含两个名称节点,一个活跃(Active)状态,一个待机(Standby)状态:
Active状态的名称节点负责对外处理客户端请求;
Standby状态的节点负责提供热备份,保存足够的元数据信息,Active节点故障时提供快速恢复能力。
Standby名称节点作为备份节点,需要存储与Active节点一致的元数据信息,那么HA又是如何保证Active名称节点的信息实时同步到Standby名称节点的呢?
两个名称节点之间的状态同步借助于共享存储系统实现,如NFS、QJM或Zookeeper。Active名称节点给将数据写入到共享存储系统,Standby节点监听共享存储系统,若有新写入,则从公共存储系统读取数据并加载到自己的内存,以此保证数据同步。
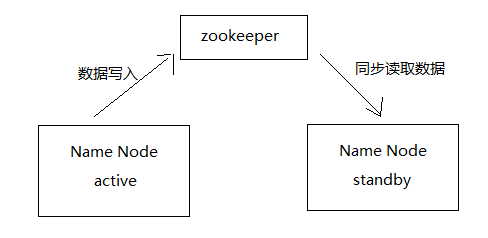
为了能让Standby节点随时接替Active节点对外提供服务,Standby节点也需要保存集群中各个块的位置信息,HA又是如何处理这个问题的呢?
HA架构下给数据节点配置两个名称节点地址,并把块的位置信息和心跳信息同时发送到两个名称节点。
当集群中存在两个名称节点时,需要保证某一时刻仅一个名称节点处于Active状态,这又是如何实现的呢?
HA使用Zookeeper确保任意时刻只有一个名称节点提供对外服务。
(二)HDFS联邦
HDFS HA解决了单点故障问题,但仍只有一个Active节点,仍存在可扩展性、系统性能、隔离性问题。单个工作名称节点,会造成集群横向扩展困难、单个节点吞吐量限制、一个程序消耗过多资源导致其他程序无法顺利运行等问题。
HDFS 联邦机制解决了上述问题,设计多个相互独立的名称节点,分别进行各自命名空间和块的管理,相互之间属于联邦关系,需不要彼此协调。兼容性方面,HDFS
联邦具有良好的向后兼容性,针对单名称节点的部署配置不需要做任何修改就可以继续工作。
1、HDFS 联邦的架构设计
HDFS联邦的名称节点提供命名空间和块管理功能,所有名称节点共享底层的数据节点存储资源。每个数据节点向集群中所有名称节点注册,周期性地向名称节点发送心跳信息报告自身状态,并处理所有名称节点的指令。
不同于HDFS 1.0中的单个命名空间,联邦提供多个独立的命名空间,每个命名空间管理属于自己的一组块,一个命名空间下的一组块成为一个“块池”,每个数据节点为多个块池提供块的存储。一个块池是一组块的逻辑集合,属于逻辑概念,块池中的各个块实际是存储在各个数据节点中的,数据节点是物理概念。HDFS联邦架构如下图:
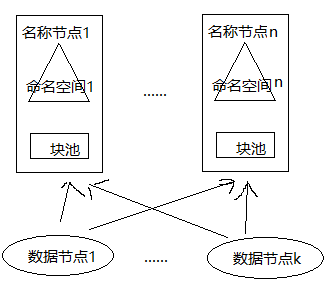
联邦中一个名称节点失效,不会影响与它相关的数据节点为其他名称节点提供服务。
2、HDFS联邦的访问方式
对于联邦中的多个命名空间,可以采用客户端挂载表的方式进行数据共享和访问。把各个命名空间挂载到全局挂载表,实现数据全局共享,客户端通过访问不同的挂载点来访问不同的子命名空间,命名空间挂载到个人的挂载表中就成为应用程序可见的命名空间。
注意,HDFS联邦不能解决单点故障问题,每个联邦内的名称节点都存在单点故障问题,需要为每个名称节点部署备份名称节点。
二、新一代资源管理框架YARN
1、MapReduce1.0的缺陷
在MapReduce1.0采用Master/Slave架构下,包含一个JobTracker负责作业的调度和资源管理,若干个TaskTracker负责执行JobTracker指派的任务。这样的架构存在单点故障问题,JobTracker故障后系统不可用;JobTracker任务过重,既负责作业调度和失败恢复,又负责资源管理分配,当任务过多时增加失败风险;TaskTracker端的资源分配不考虑硬件的实际使用情况,多个大资源任务分配到同一个TaskTracker时容易造成内存溢出;资源等量划分为slot,又分为Map槽、Reduce槽,不可混用,造成资源浪费。
2、YARN架构
为解决上述问题,Hadoop 2.0中将MapReduce重新设计,生成MapReduce2.0和YARN。YARN的基本设计思路是为JobTracker组件“放权”,把原JobTracker的功能(资源管理、任务调度、任务监控)进行拆分。YARN包括ResourceManager、ApplicationMaster和Node Manager。YARN设计思路如下图:

(1)ResourceManager(RM)是全局资源管理器,负责整个系统的资源管理和分配。包括调度器和应用程序管理器两个组件。
- 1)调度器负责资源管理和分配,接收来自Application的应用程序资源请求,根据容量、队列等限制条件,把集群中的资源以容器的形式分配给提出申请的应用程序,容器的选择一般遵循就近选择,实现计算向数据靠拢。容器是动态资源分配单位,封装了一定数量的CPU等资源,为每个应用分配相应资源,而不再是1.0中槽的概念。调度器可插拔,用户可使用YARN提供的调度器,也可以自定义。
- 2)应用程序管理器负责系统中全部应用程序的管理,如程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重启等。
Hadoop平台上,用户应用程序以作业(Job)形式提交,一个Job被分解成若干任务(包括Map任务、Reduce任务)进行分布式执行,ResourceManager接收用户提交的作业,按照作业上下文信息以及从NodeManager收集来的容器状态信息,启动调度过程,为用户作业启动一个ApplicationMaster。
(2)ApplicationMaster负责任务调度和监控,它的功能包括:
- 当用户提交作业时,Application与ResourceManager协商获取资源;
- 把获得的容器资源进一步分配给内部的各个任务(Map或Reduce任务),实现资源二次分配;
- 与NodeManager交互,进行程序的启动、运行、监控、停止,监控资源使用情况,对任务的进度和状态进行监控,在任务失败时重启任务;
- 定时向ResourceManager发送心跳信息,报告监控数据;
- 作业完成时,向ResourceManager注销容器。
(3)NodeManager负责执行原TaskTracker任务。
NodeManager是驻留在一个YARN集群中的每个节点上的代理,负责容器的生命周期管理,监控容器资源使用情况,并通过心跳向ResourceManager汇报这些信息,同时,接收来自ApplicationMaster的启动/停止容器的各种请求。NodeManager主要负责抽象的容器,只处理与容器相关的事情,而不具体负责每个任务自身状态的管理(这些工作由ApplicationMaster完成)
3、YARN工作流程
在YARN框架中执行一个MapReduce程序时,从提交到完成需要经历的步骤:
- 向YARN提交用户编写的客户端程序,提交内容包括:ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
- YARN中ResourceManager负责接收和处理来自客户端的请求。接到请求后,调度器为应用程序分配容器;应用程序管理器与容器所在的NodeManager通信,为该程序在该容器中启动一个Application Master。
- Application Manager创建后向ResourceManager注册,从而使用户可以通过ResourceManager直接查看应用运行状态
接下来是具体的应用程序执行步骤。
- ApplicationManager采用轮询方式通过RPC协议向ResourceManager申请资源。
- ResourceManager以容器形式向提出申请的ApplicationMaster分配资源,ApplicationMaster申请到资源后就与该容器所在NodeManager通信,要求它启动任务。
- ApplicationMaster要求容器启动任务时,为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)然后将任务启动命令写到脚本中,最后通过在容器中运行脚本来启动任务。
- 各个任务通过某RPC协议向ApplicationMaster汇报自己的状态和进度,让ApplicationMaster可以随时掌握各个任务的运行状态,从而可以在任务失败时重启任务。
- 程序运行完成后,ApplicationMaster和ResourceManager的应用程序管理器注销并关闭自己。若ApplicationMaster失败,ResourceManager中的应用程序管理器会监测到失败并重启,直至任务执行完毕。
YARN的发展目标是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度框架YARN,在YARN上可以部署各种计算框架,如MapReduce、HBase、Storm、Spark等,由YARN为这些计算框架提供统一的资源调度管理服务,实现一个集群不同应用负载混搭,并能够根据各种计算框架的负载需求调整各自占用的资源,实现集群资源共享和资源弹性收缩。