前言
这篇文章是接着上篇文章写的,如果没有看过上篇文章容器的基础 XmlBeanFactory(上篇)建议先去看一下,上篇文章讲述了加载bean之前的,Spring所要做的准备工作,这篇文章就直接讲述Spring加载bean的过程,话不多说,开始。
加载Bean
之前在上一篇文章中讲述到了在XmlBeanFactory构造函数中调用了XMLBeanDefinitionReader类型的reader属性提供的方法:this.reader.loadBeanDefinitions(resource),而这句代码则是整个资源加载的切入点,先来看看这个方法的时序图:
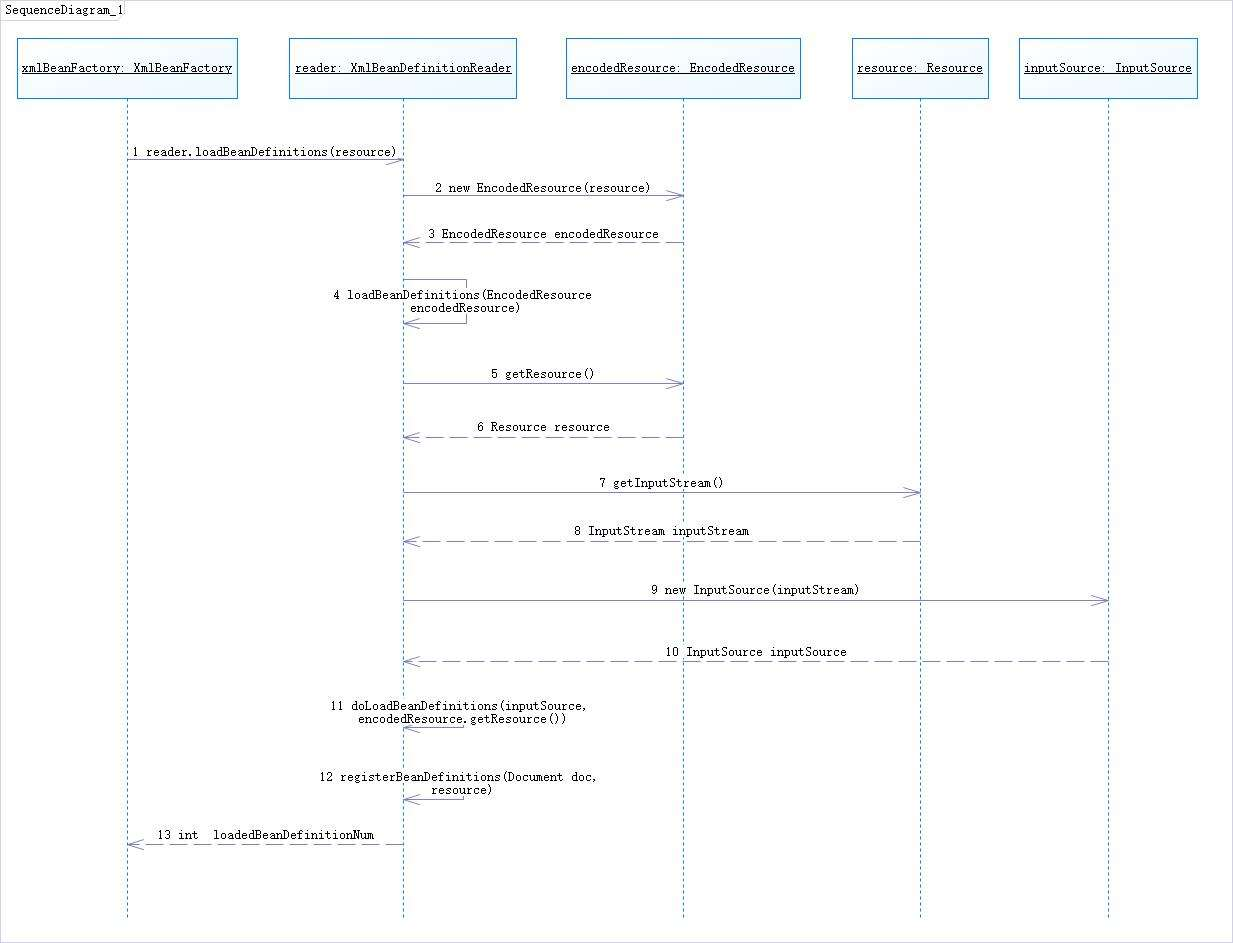
从上面时序图中可以看出,加载XML文档和解析注册Bean,一直都是在做准备工作。根据上面的时序图我们来分析一下这里究竟在准备上面?
(1)封装资源文件。当进入XMLBeanDefinitionReader后,首先对参数Resource使用EncodeResource类进行封装。
(2)获取输入流。从Resource中获取对应的InputStream并构造InputSource。
(3)通过构造的InputSource实例和Resource实例继续调用函数doLoadBeanDefinitions。我们来看一下loadBeanDefinitions函数的具体实现过程:
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException { return loadBeanDefinitions(new EncodedResource(resource)); }
那么EncodedResource的作用是什么呢?通过名称,大致上可以推断出这个类的主要用于对资源文件的编码进行处理的。其中最主要的逻辑体现在getReader()方法中,当设置了编码属性的时候Spring会使用相应的编码作为输入流的编码。来看一下getReader()方法的源码:
public Reader getReader() throws IOException { if (this.charset != null) { return new InputStreamReader(this.resource.getInputStream(), this.charset); } else if (this.encoding != null) { return new InputStreamReader(this.resource.getInputStream(), this.encoding); } else { return new InputStreamReader(this.resource.getInputStream()); } }
上面的代码构造了一个有编码(encoding)的InputStreamReader。当构造好的encodeResource对象后,再次转入了可复用方法loadBeanDefinitions(new EncodedResource(resource))。这个方法内部才是真正的数据准备阶段,也就是时序图描述的逻辑,一起来看一下:
1 public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException { 2 Assert.notNull(encodedResource, "EncodedResource must not be null"); 3 if (logger.isTraceEnabled()) { 4 logger.trace("Loading XML bean definitions from " + encodedResource); 5 } 6 //通过属性来记录已经加载的资源 7 Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get(); 8 if (currentResources == null) { 9 currentResources = new HashSet<>(4); 10 this.resourcesCurrentlyBeingLoaded.set(currentResources); 11 } 12 if (!currentResources.add(encodedResource)) { 13 throw new BeanDefinitionStoreException( 14 "Detected cyclic loading of " + encodedResource + " - check your import definitions!"); 15 } 16 try { 17 //从encodeResource中获取已经封装的Resource资源,并从该资源中获取其中的InputStream 18 InputStream inputStream = encodedResource.getResource().getInputStream(); 19 try { 20 InputSource inputSource = new InputSource(inputStream); 21 if (encodedResource.getEncoding() != null) { 22 inputSource.setEncoding(encodedResource.getEncoding()); 23 } 24 return doLoadBeanDefinitions(inputSource, encodedResource.getResource()); 25 } 26 finally { 27 //关闭输入流 28 inputStream.close(); 29 } 30 } 31 catch (IOException ex) { 32 throw new BeanDefinitionStoreException( 33 "IOException parsing XML document from " + encodedResource.getResource(), ex); 34 } 35 finally { 36 currentResources.remove(encodedResource); 37 if (currentResources.isEmpty()) { 38 this.resourcesCurrentlyBeingLoaded.remove(); 39 } 40 } 41 }
SAX:SAX基于事件的解析,解析器在一次读取XML文件中根据读取的数据产生相应的事件,由应用程序实现相应的事件处理逻辑,即它是一种“推”的解析方式;这种解析方法速度快、占用内存少,但是它需要应用程序自己处理解析器的状态,实现起来会比较麻烦。
再一次来梳理一下数据准备阶段的逻辑,首先对传入的Resource参数进行封装,目的是考虑到Resource可能存在编码要求的情况,其次,通过SAX读取XML文件的方式来准备InputSource对象,最后将准备的数据通过参数传递给真正处理的核心部分doLoadBeanDefinitions(inputSource,encodedREsource.getResource())。来了解一下这个方法:
1 protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource) 2 throws BeanDefinitionStoreException { 3 4 try { 5 Document doc = doLoadDocument(inputSource, resource); 6 int count = registerBeanDefinitions(doc, resource); 7 if (logger.isDebugEnabled()) { 8 logger.debug("Loaded " + count + " bean definitions from " + resource); 9 } 10 return count; 11 } 12 catch (BeanDefinitionStoreException ex) { 13 throw ex; 14 } 15 catch (SAXParseException ex) { 16 throw new XmlBeanDefinitionStoreException(resource.getDescription(), 17 "Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex); 18 } 19 catch (SAXException ex) { 20 throw new XmlBeanDefinitionStoreException(resource.getDescription(), 21 "XML document from " + resource + " is invalid", ex); 22 } 23 catch (ParserConfigurationException ex) { 24 throw new BeanDefinitionStoreException(resource.getDescription(), 25 "Parser configuration exception parsing XML from " + resource, ex); 26 } 27 catch (IOException ex) { 28 throw new BeanDefinitionStoreException(resource.getDescription(), 29 "IOException parsing XML document from " + resource, ex); 30 } 31 catch (Throwable ex) { 32 throw new BeanDefinitionStoreException(resource.getDescription(), 33 "Unexpected exception parsing XML document from " + resource, ex); 34 } 35 }
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception { return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler, getValidationModeForResource(resource), isNamespaceAware()); }
在上面的代码中,假如不考虑异常类的代码,其实只是做了三件事,这三件事的每一件都必不可少:
(1)获取对XML文件的验证模式(在doLoadDocument方法里调用getValidationModeForResource(resource)方法)。
(2)加载XML文件,并得到对应的Document。
(3)根据返回的Document注册Bean信息。
这三个步骤支撑着整个Spring容器部分的实现基础,尤其是第三步对配置文件的解析,逻辑非常复杂。
至此,整个Spring的容器基础,已经讲述完毕。
参考:《Spring源码深度解析》 郝佳 编著: