一、MapReduce 原理
这个链接总结较好 : https://www.jianshu.com/p/ca165beb305b
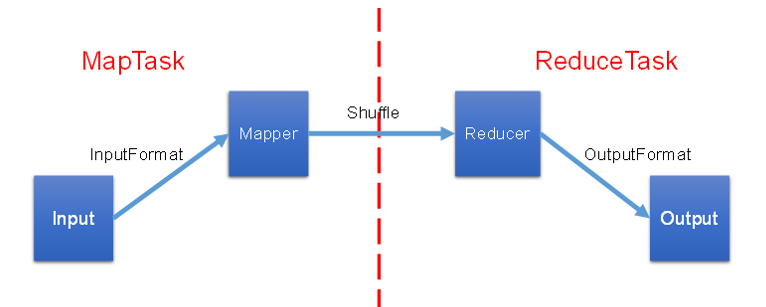
MapReduce 过程分为Map 和 Reduce
在Map阶段,将输入的数据按照规则映射为单个对象,之后通过Shuffle,作为Reduce的输入数据。
在Reduce阶段, 将Map输入的相同的对象进行归约处理后,得到以数据为key,以数量为value的结果。
二、MapReduce工作原理过程
2.1、 旧版
旧版的mapReduce 分布 JobTracker和TaskTracker
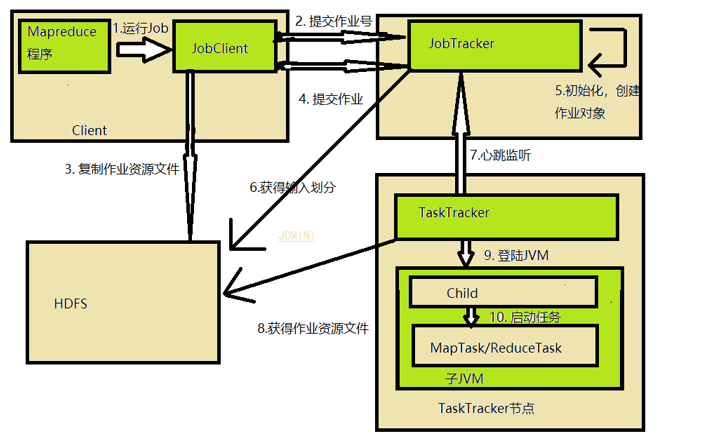
JobTracker 负责接受客户端提交的任务请求,分配系统资源,分配任务给TaskTracker, 管理任务的失败重启操作;
TaskTracker负责接受并执行JobTracker分配的任务,并与JobTracker保持心跳机制
1、 客户端启动一个作业;
2、 通过JobTracker 获取一个Job ID
3、 将作业需要的资源文件(jar,配置文件和客户端计算所得输入划分信息)复制到HDFS, 存在JobTracker创建的文件中,文件名为Job ID, Jar文件由副本,副本数量由mapred.submit.replication属性控制;划分信息告诉JobTrancker为这个作业启动多少个Mapr任务信息
4、 JobTracker接受到作业后,放入作业列队,等待作业调度器进行调度;
当作业调度器调度到该做业务时,根据划分信息为每个划分创建一个map任务,并将map 任务分配给TaskTracker执行。 对于map和reduce任务, TaskTracker根据主机核的数量和内存大小由分配map和reduce
5、TaskTrackor给JobTracker发送定时发送监听当前map的任务完成进度等信息信息,保证JobTracker在运行。当JobTracker收到一个任务完成是,改作业甚至为完成,并发送消息给用户。
2.2、新版
新版 MapReduce也叫作Yarn框架, 其最重要的重构在于将资源分配与任务调度/监控进行了分离.
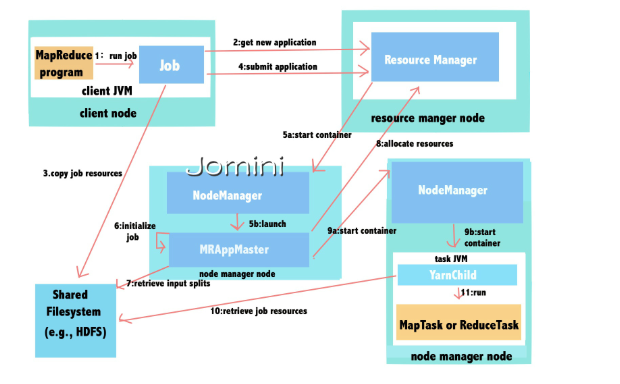
1、ResourceManager: 资源调度器
首先保持和NodeManager的心跳机制, 接受客户端的任务请求, 根据NodeManager报告的资源情况, 启动调度任务, 分配Container给ApplicationMaster, 监控,AppMaster的存在情况, 负责作业和资源分配调度, 资源包括CPU, 内存, 磁盘, 网络等, 它不参与具体任务的分配和监控, 也不能管理具体任务的失败和重启等.
2、 ApplicationMaster: 任务管理器
在其中一台Node机器上, 负责一个Job的整个生命周期. 包括任务的分配调度, 任务的失败和重启管理, 具体任务的所有工作全部由ApplicationMaster全权管理, 就像一个大管家一样, 只向ResourceManager申请资源, 向NodeManager分配任务, 监控任务的运行, 管理任务的失败和重启.
3、NodeManager: 任务处理器
负责处理ApplicationMaster分配的任务, 并保持与ResourceManager的心跳机制, 监控资源的使用情况并向RM报告进行报告, 支持RM的资源分配工作
MapReduce机制
1、MapTask 收集map() 方法输出的键值对,放到内存缓冲区;
MapTask 机制
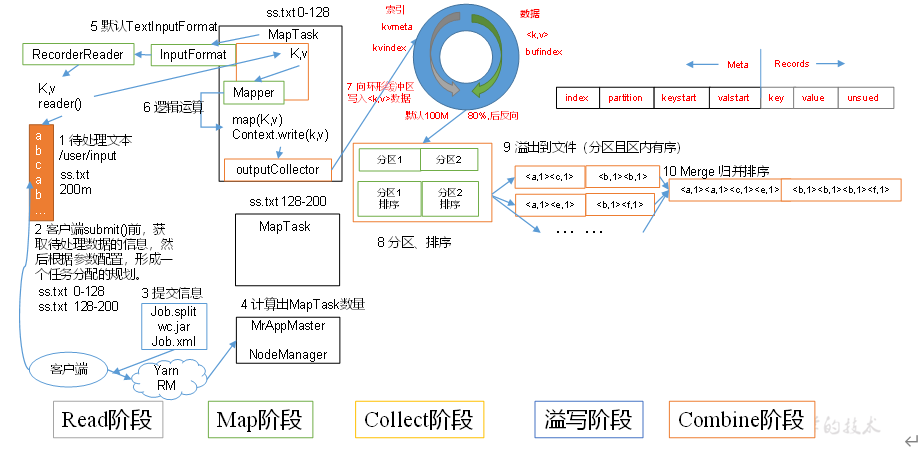
1)Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value
切片机制:
FileInputFormat: 按照文件内容长度切片;切片大小默认为Block大小,切片不考虑数据整体,只是逐个对文件切片; 框架默认切片机制,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量 小文件,就会产生大量的MapTask,处理效率极其低下
CombileTextInputFormat : 用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件 就 可以交给一个MapTask处理
FileInputFormat:
TextInputFormat :
KeyVaueTextInputFormat : 每一行为一条记录,并每一行都有一个key, 行为vaue
NlineINputFormat : 不在block划分, 根据输入的行数决定多少个切片,比如三行一个切片;
自定义InputFormat
2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
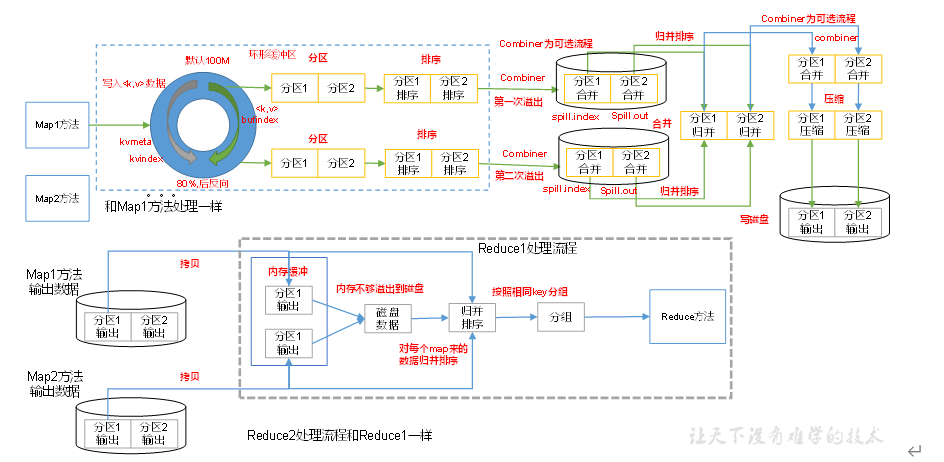
3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。 这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
5)Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销
2、从内存缓冲区不断溢出本地的磁盘文件;
3、多个文件合并成大的文件;
4、多个溢出过程以及合并的过程,需要Paritioner进行分区和针对key进行排序;
5、ReduceTask 根据分区号、在MapTask机器上取得相应结果的分区数据;
6、ReduceTask 取到同一个来自不同MapTask分区文件,ReduceTask会将这些文件再合并;
7、合并成大文件,shuffe过程结束,再进入ReduceTask逻辑运算;
ReduceTask机制
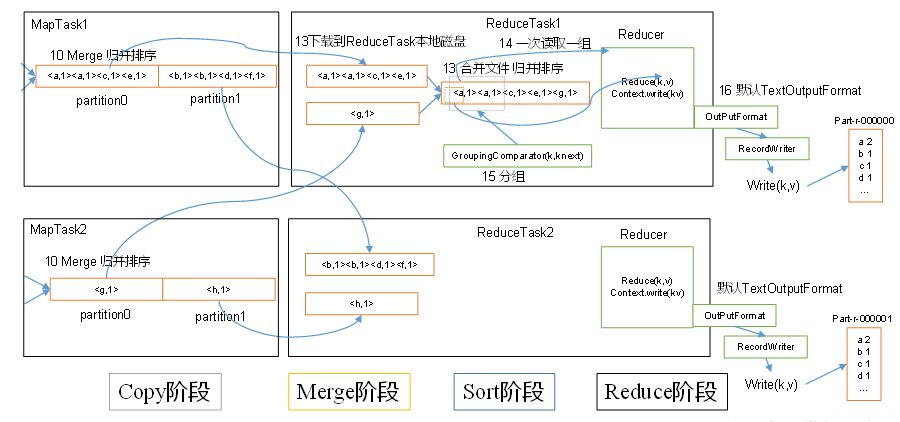
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
shuffle 机制
partition 分区
将结果输出到不同的分区中
writableComparable 排序:
MapTask 和 ReduceTask 都会对数据按照key 排序
MapTask 将结果放在环形缓冲区,当达到一定的阈值,将数据写在磁盘上,当数据处理完毕,ui磁盘上所有文件进行归 并排序;
ReduceTask 从MapTask 获取相应数据文件,如果文件较大,则写在磁盘,否则写在内存中;如果内存中文件大小或者数目超过一定阈值,则合并后将数据写在磁盘上。当所有数据拷贝完,ReduecTask对内存和磁盘的数据进行归并排序;
通过重写compare to方法实现排序
combiner 合并
groupingComparator 分组(辅助排序)
对reduce阶段的数据根据某几个字段分组
MapReduce的工作机制
《hadoop权威指南第四版》第七章 Mapreduce的工作机制
==================================================================================
参考和部分转载自:https://blog.csdn.net/weixin_42582592/article/details/83080900
https://www.cnblogs.com/laowangc/p/8961946.html