MySQL 之 Explain 输出分析
背景
前面的文章写过 MySQL 的事务和锁,这篇文章我们来聊聊 MySQL 的 Explain,估计大家在工作或者面试中多多少少都会接触过这个。可能工作中实际使用的不多,但是不论的自己学习还是面试,都需要掌握的。
Explain 可以使用在SELECT, DELETE, INSERT, REPLACE, and UPDATE 语句中,执行的结果会在每一行显示用到的每一个表的详细信息。简单语句可能结果就只有一行,但是复杂的查询语句会有很多行数据。
Explain 的使用
在 SQL 语句前面加上 explain,如:EXPLAIN SELECT * FROM a;
举个例子
CREATE TABLE `a` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `uid` int(10) unsigned DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_uid` (`uid`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
采用上面的语句EXPLAIN SELECT * FROM a;,效果如下通过图片我们可以看到执行过后会输出 12 个字段,那么每个字段是什么意思呢?
Explain 输出的字段内容
id, select_type, table, partitions, type, possible_keys, key, key_len, ref, rows,filtered,extra
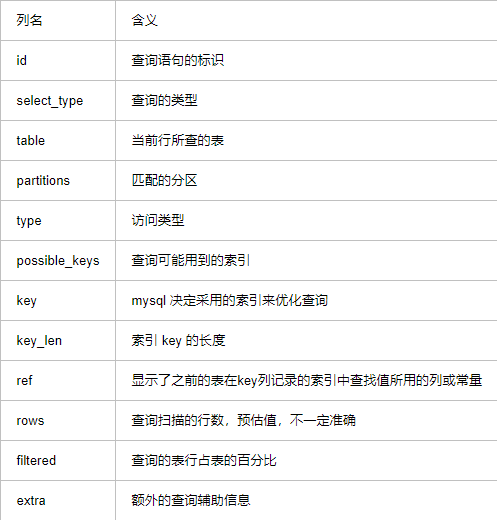
常用字段详细介绍
1.id: 是用来顺序标识整个查询中 select 语句的,在嵌套查询中id越大的语句越先执行
2.select_type:•simple: 简单的SELECT(不使用UNION或子查询)•primary: 最外面的SELECT•union: UNION中的第二个或更高的SELECT语句•dependent union: UNION中的第二个或更高的SELECT语句,取决于外部查询•union result: UNION的结果•subquery: 在子查询中首先选择SELECT•dependent subquery: 子查询中的第一个SELECT,取决于外部查询•derived: 派生表——该临时表是从子查询派生出来的,位于from中的子查询•uncacheable subquery: 无法缓存结果的子查询,必须为外部查询的每一行重新计算•uncacheable union: 在UNION中的第二个或更晚的选择属于不可缓存的子查询。
3.table: 每一行引用的表名。
4.type: 从上到下效果依次降低•system: const 的一种特例,表中只有一行数据•const: 当确定最多只会有一行匹配的时候,MySQL优化器会在查询前读取它而且只读取一次,因此非常快。使用主键查询往往就是 const 级别的,非常高效•eq_ref: 最多只返回一条符合条件的记录,通过使用在两个表有关联字段的时候•ref: 通过普通索引查询匹配的很多行时的类型•fulltext: 全文索引•ref_or_null: 跟 ref 类似的效果,不过多一个列不能 null 的条件•index_merge: 此连接类型表示使用了索引合并优化。在这种情况下,输出行中的 key 列包含使用的索引列表,key_len包含所用索引的最长 key 部分列表•unique_subquery: 在使用 in 查询的情况下会取代 eq_ref•range: 范围扫描,一个有限制的索引扫描。key 列显示使用了哪个索引。当使用=、 <>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比较关键字列时,可以使用 range•index: 类似全表扫描,只是扫描表的时候按照索引次序进行而不是行。主要优点就是避免了排序, 但是开销仍然非常大。如在Extra列看到Using index,说明正在使用覆盖索引,只扫描索引的数据,它比按索引次序全表扫描的开销要小很多•ALL: 全表扫描。
5.possible_key: MySQL 可能采用的索引,但是并不一定使用6.key: MySQL 正真使用的索引名称7.rows: 预估的扫描行数,只能参考不准确8.extra: 该列包含了很多额外的信息,包括是否文件排序,是否有临时表等,很多时候这个字段很有用能提供很多信息。