一、 消息队列
1. 分布式应用与集群的区别:
如果是一个业务被拆分成多个子业务部署在不同的服务器上,那就是分布式应用;如果是同一个业务部署在多台服务器上,那就是集群。
2. 系统间通信方式:
一种是基于远程过程调用的方式(如RPC调用);另一种是基于消息队列的方式。
二、RabbitMQ
1.RabbitMQ特点:
RabbitMQ是一个由Erlang语言开发的基于AMQP标准的开源框架。RabbitMQ最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。其具体特点包括:
可靠性 灵活的路由 支持消息集群 高可用性
支持多种协议 (除支持AMQP协议之外,还通过插件的方式支持其他消息队列协议,如STOMP、MQTT)
支持多语言客户端 提供跟踪机制 提供管理界面
提供插件机制 (RabbitMQ提供了许多插件,也可以编写自己的插件)
2. 总结:
RabbitMQ最大的优势在于提供了比较灵活的消息路由策略、高可用性、可靠性以及丰富的插件、多种平台支持和完善的文档。不过,由于AMQP协议本身导致它的实现比较重量,从而使得与其他MQ (比如Kafka) 对比其吞吐量处于下风。
三、ActiveMQ
1.ActiveMQ 特点:
ActiveMQ是由Apache出品的一款开源消息中间件,旨在为应用程序提供高效、可扩展、稳定、安全的企业级消息通信。ActiveMQ实现了JMS 1.1 并提供了很多附加的特性,比如JMX管理、主从管理、消息组通信、消息优先级、延迟接收消息、虚拟接收者、消息持久化、消息队列监控等。主要特性如下:
支持Java、C、C++、C#、Ruby、Perl、Python、PHP等多种语言的客户端和协议,如OpenWire、STOMP、AMQP、MQTT协议。
提供了像消息组通信、消息优先级、延迟接收消息、虚拟接收者、消息持久化之类的高级特性。
完全支持JMS 1.1 和 J2EE 1.4 规范 (包括持久化、分布式事务消息、事务)
支持Spring框架,ActiveMQ 可以通过Spring 的配置文件方式很容易嵌入Spring应用中。
通过了常见的J2EE服务器测试,比如TomEE、Geronimo、JBoss、GlassFish、WebLogic。
连接方式多样化,ActiveMQ 提供了多种连接方式,例如 in-VM、TCP、SSL、NIO、UDP、多播、JGroups、JXTA。
支持通过使用JDBC 和 Journal 实现消息的快速持久化。
为高性能集群、客户端-服务器、点对点通信等场景而设计。
提供了技术和语言中立的REST API 接口。
支持以AJAX 方式调用 ActiveMQ。
可以作为内存中的JMS 提供者,非常适合 JMS 单元测试。
四、Kafka
1.Kafka 特点:
Kafka 最早是由LinkedIn 公司开发的一种分布式的基于 发布/订阅 的消息系统,后来成为 Apache 的顶级项目。其主要特点如下:
同时为发布和订阅提供高吞吐量。 (Kafka 的设计目标是以时间复杂度为 O(1) 的方式提供消息持久化能力的,即使对TB级别以上数据也能保证常数时间的访问性能,即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条消息的传输)
消息持久化。 (将消息持久化到磁盘,因此可用于批量消费,例如 ETL 以及实时应用程序。通过将数据持久化到硬盘以及复制可以防止数据丢失。)
分布式。 (支持服务器间的消息分区及分布式消费,同时保证每个Partition 内的消息顺序传输。其内部的Producer、Broker 和 Consumer 都是分布式架构,这更易于向外扩展。)
消费消息采用 Pull 模式。(消息被处理的状态是在 Consumer 端维护的,而不是由服务器端维护,Broker 无状态,Consumer 自己保存offet。)
支持Online 和 Offline 场景,同时支持离线数据处理和实时数据处理。
五、RocketMQ
1.RocketMQ 特点:
RocketMQ是阿里巴巴于2012年开源的分布式消息中间件,后来捐赠给 Apache软件基金会,并于2017年9月25日成为Apache的顶级项目。作为经历过多次阿里巴巴“双11” 这种“超级工程”的洗礼并有稳定出色表现的国产中间件,以其高性能、低延迟和高可靠等特性近年来被越来越多的国内企业所使用。其主要特点如下:
具有灵活的可扩展性。 (RocketMQ 天然支持集群,其核心四大组件(NameServer、Broker、Producer、Consumer)的每一个都可以在没有单点故障的情况下进行水平扩展。)
具有海量消息堆积能力。 (RocketMQ 采用零拷贝原理实现了超大量消息的堆积能力,据说单机已经可以支持亿级消息堆积,而且在堆积了这么多消息后依然保持写入低延迟)
支持顺序消息。 (RocketMQ 可以保证消息消费者按照消息发送的顺序对消息进行消费。顺序消息分为全局有序消息和局部有序消息,一般推荐使用局部有序消息,即生产者通过将某一类消息按顺序发送至同一个队列中来实现。)
支持多种消息过滤方式。 (消息过滤分为在服务器端过滤和在消费端过滤。在服务器端过滤时可以按照消息消费者的要求进行过滤,优点是减少了不必要的消息传输,缺点是增加了消息服务器的负担,实现相对复杂。消费端过滤则完全由具体应用自定义实现,这种方式更加灵活,缺点是很多无用的消息会被传输给消息消费者。)
支持事务消息。 (RocketMQ 除支持普通消息、顺序消息之外,还支持事务消息,这个特性对于分布式事务来说提供了另一种解决思路。)
支持回溯消费。 (回溯消费是指对于消费者已经消费成功的消息,由于业务需求需要重新消费。RocketMQ 支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯,也可以向后回溯。)
六、怎么保证数据不丢失
queue 点对点模式 不存在数据丢失问题
“负载均衡”模式,如果当前没有消费者,消息也不会丢弃;如果有多个消费者,那么一条消息也只会发送给其中一个消费者,并且要求消费者ack信息ack确认机制。
Topics 发布订阅模式 消息可能会丢失
ActiveMQ——消息持久化
有了持久化机制,消息在发送后会首先持久化到对应的文件或数据表中,在消息被消费后,再从这些文件或表中删除(对于持久化的主体消息不会删除)。
“订阅-发布”模式,如果当前没有订阅者,消息将会被丢弃。如果有多个订阅者,那么这些订阅者都会收到消息
在发布订阅的时候 为每个订阅者设置一个唯一的订阅标识
在消息服务器启动时会先从持久化的媒介中读取之前未消费的消息,并将读取到的消息发送给消息的订阅者或者消费者去消费,这样就不会出现消息的丢失,保证了消息的可靠性。
消息的可靠性通过三个方面保证——持久化、事务和签收。这里说一下ActiveMQ中消息持久化的方式。
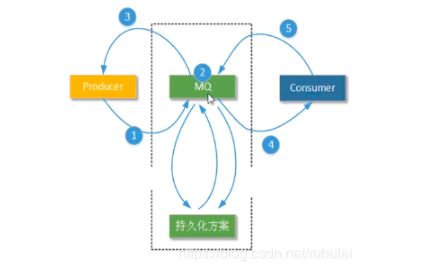
七、消息持久化的方式
ActiveMQ中主要有以下几种持久化的方式:具体可参考官网:消息的持久化方式和方案选择
1️⃣AMQ Message Stroe:基于文件的存储方式,具有写入速度快和容易恢复的特点,消息存储在一个个文件中,文件的默认大小是32M,是之前的默认持久化方式,现在几乎不用了
2️⃣KahaDB:基于日志文件的持久化方式,从Active5.4版本后作为默认的持久化方式,在activemq.xml文件中可以看到如下配置
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"/>
</persistenceAdapter>
即默认情况下会将消息持久化到activemq安装目录下的/data/kahadb目录下,在该目录下有4个或5个文件,用来保存持久化的消息数据(db-n.log)和索引(db.data)等:数据会被追加到db-n.log文件中,当不再需要某一个db-n.log文件中的数据的时候,该log文件会被丢弃
文件的作用介绍:
db-<n>.log:KahaDB存储消息到预定义大小的数据记录文件中,文件命名为db-<n>.log,当数据文件已满时,会创建一个新的数据记录文件,n的值也会随之递增,文件名按照数字进行编号,如db-1.log、db-2.log、db-3.log、…当不再有引用道数据文件中的任何 消息时,文件会被删除或归档
db.data:该文件包含了持久化的BTree索引,索引了消息数据记录中的消息,他是消息的索引文件,本质上是B-Tree,使用B-Tree作为索引到db-n.log中找消息
db.free:当前db.data文件中有哪些页是空闲的,文件的具体内容是所有空闲页的ID
db.redo:用来进行消息恢复
lock:文件锁,表示当前获得KahaDB读写权限的broker
3️⃣JDBC消息存储:基于JDBC的消息存储,可借助于这种方式将消息持久化到Mysql等数据库中
4️⃣LevelDB消息存储:这种文件系统是从ActiveMQ5.8之后引进的,和KahaDB非常相似,也是基于文件的本地数据库存储形式,但是它提供了比KahaDB更快的持久性,它不是使用B-Tree索引日志,而是使用基于LevelDB的索引
5️⃣JDBC + ActiveMQ高速缓存:即JDBC Message store with ActiveMQ Journal,和JDBC的方式很相似,只不过是在持久化到的数据库和ActiveMQ服务器之间加了一层高速缓存
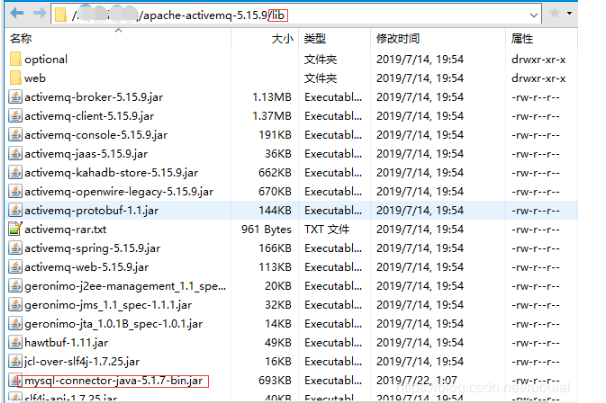
JDBC方式的消息持久化步骤 由于ActiveMQ是基于Java语言开发的,因此我们可以直接在其项目的lib包下加入数据库驱动的jar包或者数据库连接池的jar包等。
1、将Mysql的驱动jar包加入到ActiveMQ的lib目录下
2、在activemq.xml文件中配置数据源:activemq.xml类似于Spring的容器配置文件
<bean id="mysql-ds" class="org.apache.commons.dbcp2.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://192.168.2.143:3306/activemq?relaxAutoCommit=true"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
3、修改消息的持久化方式:由默认的KahaDB改为现在的JDBC的方式
改之前:
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"/>
</persistenceAdapter>
改之后:注意数据源的名称要一致,createTablesOnStartup是说重启MQ服务后是否自动创建ActiveMQ相关的表,一般设置为true
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds" createTablesOnStartup="true"/>
</persistenceAdapter>
4、在连接的数据库服务器上创建使用的库
5、配置好后,重启MQ服务,会看到数据库中多了3张表,这些表是ActiveMQ启动服务时创建的根ActiveMQ相关的表

activemq_acks:该表记录的是主题订阅关系(消息签收者)信息
activemq_msgs:该表记录的是待消费的消息,该表中的消息一旦被消费则会被删除(主题类的消息不会被清除)
activemq_lock:在集群环境中才有用,用于记录哪个Broker是当前的Master Broker
这样配置好后,一旦有消息产生就会在相应的表中看到记录:但队列中的消息一旦被消费就又会被删除

配置JDBC持久化的高速缓存:仅有上面的配置,则消息生产者每次有消息需要持久化都会通过JDBC去调用数据库服务以持久化数据,但像队列中的消息,大部分在消费后又需要清除,进行及其短暂的持久化意义不大,但却依然使JDBC频繁的和数据库进行交互,效率低下。因此可以在ActiveMQ和数据库服务器之间加一层高速缓存,用来暂时缓存消息,若队列中的消息长时间没有被消费时才进行持久化,这样就会大大减少ActiveMQ和数据库服务交互的次数,提高效率。举例来说:生产者生产了1000条消息,这1000条消息会保存到缓存文件journal文件中,如果消费者的消费速度很快,在journal文件还没有同步到数据库之前,消费者已经消费了900条,那么这时就只需要将剩余的100条同步即可,如果消费者消费的很慢,journal文件可以批量的将消息同步到数据库,大大减少了ActiveMQ和数据库服务器的交互次数。将持久化的方式改为如下方式:
<persistenceFactory>
<journalPersistenceAdapterFactory
journalLogFiles="4"
journalLogFileSize="32768"
useJournal="true"
useQuickJournal="true"
dataSource="#mysql-ds"
dataDirectory="activemq-data"
/>
</persistenceFactory>
来源于:传送门