一 数学定义的函数与python中的函数
初中数学函数定义:一般的,在一个变化过程中,如果有两个变量x和y,并且对于x的每一个确定的值,y都有唯一确定的值与其对应,那么我们就把x称为自变量,把y称为因变量,y是x的函数。自变量x的取值范围叫做这个函数的定义域
例如y=2*x
python中函数定义:函数是逻辑结构化和过程化的一种编程方法。

1 python中函数定义方法: 2 3 def test(x): 4 "The function definitions" 5 x+=1 6 return x 7 8 def:定义函数的关键字 9 test:函数名 10 ():内可定义形参 11 "":文档描述(非必要,但是强烈建议为你的函数添加描述信息) 12 x+=1:泛指代码块或程序处理逻辑 13 return:定义返回值,函数一旦遇到return就立即结束
调用运行:可以带参数也可以不带
函数名()
补充:
1.编程语言中的函数与数学意义的函数是截然不同的俩个概念,编程语言中的函数是通过一个函数名封装好一串用来完成某一特定功能的逻辑,数学定义的函数就是一个等式,等式在传入因变量值x不同会得到一个结果y,这一点与编程语言中类似(也是传入一个参数,得到一个返回值),不同的是数学意义的函数,传入值相同,得到的结果必然相同且没有任何变量的修改(不修改状态),而编程语言中的函数传入的参数相同返回值可不一定相同且可以修改其他的全局变量值(因为一个函数a的执行可能依赖于另外一个函数b的结果,b可能得到不同结果,那即便是你给a传入相同的参数,那么a得到的结果也肯定不同)
2.函数式编程就是:先定义一个数学函数(数学建模),然后按照这个数学模型用编程语言去实现它。至于具体如何实现和这么做的好处,且看后续的函数式编程。
def test(x): #写了参数就要传参数进来 ''' 2*x+1 :param x:整形数字 :return: 返回计算结果 ''' y=2*x+1 return y print(test) #将会打印出函数的内存地址 def test(): #没有定义参数,可以不写 ''' 2*x+1 :param x:整形数字 :return: 返回计算结果 ''' x=3 y=2*x+1 return y a=test() #函数结果需要有一个变量a来接收它 print(a)
# 虽然两个函数一个有参数一个没有参数,但后一个test会将前一个直接覆盖。
# 此时如果输入b = test(3333),会直接报错,新的test不允许传参数
二 为何使用函数
背景提要
现在老板让你写一个监控程序,监控服务器的系统状况,当cpu\memory\disk等指标的使用量超过阀值时,发邮件报警,你掏空了所有的知识量,写出了以下代码
1 while True: 2 if cpu利用率 > 90%: 3 #发送邮件提醒 4 连接邮箱服务器 5 发送邮件 6 关闭连接 7 8 if 硬盘使用空间 > 90%: 9 #发送邮件提醒 10 连接邮箱服务器 11 发送邮件 12 关闭连接 13 14 if 内存占用 > 80%: 15 #发送邮件提醒 16 连接邮箱服务器 17 发送邮件 18 关闭连接
上面的代码实现了功能,但即使是邻居老王也看出了端倪,老王亲切的摸了下你家儿子的脸蛋,说,你这个重复代码太多了,每次报警都要重写一段发邮件的代码,太low了,这样存在2个问题:
- 代码重复过多,一个劲的copy and paste不符合高端程序员的气质
- 如果日后需要修改发邮件的这段代码,比如加入群发功能,那你就需要在所有用到这段代码的地方都修改一遍
你觉得老王说的对,你也不想写重复代码,但又不知道怎么搞,老王好像看出了你的心思,此时他抱起你儿子,笑着说,其实很简单,只需要把重复的代码提取出来,放在一个公共的地方,起个名字,以后谁想用这段代码,就通过这个名字调用就行了,如下
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
发送邮件('内存报警')
你看着老王写的代码,气势恢宏、磅礴大气,代码里透露着一股内敛的傲气,心想,老王这个人真是不一般,突然对他的背景更感兴趣了,问老王,这些花式玩法你都是怎么知道的? 老王亲了一口你儿子,捋了捋不存在的胡子,淡淡的讲,“老夫,年少时,师从京西沙河淫魔银角大王 ”, 你一听“银角大王”这几个字,不由的娇躯一震,心想,真nb,怪不得代码写的这么6, 这“银角大王”当年在江湖上可是数得着的响当当的名字,只可惜后期纵欲过度,卒于公元2016年, 真是可惜了,只留下其哥哥孤守当年兄弟俩一起打下来的江山。 此时你看着的老王离开的身影,感觉你儿子跟他越来越像了。。。
总结使用函数的好处:
1.代码重用
2.保持一致性,易维护(群发邮件,一起修改,如添加抄送)
3.可扩展性
三 函数和过程
过程定义:过程就是简单特殊没有返回值的函数
这么看来我们在讨论为何使用函数的的时候引入的函数,都没有返回值,没有返回值就是过程,没错,但是在python中有比较神奇的事情:
def test01(): msg = 'test01' print(msg) def test02(): msg = 'test02' print(msg) return msg def test03(): msg = 'test03' print(msg) return 1,2,3,4,'a',['alex'],{'name':'alex'},None def test04(): msg = 'test03' print(msg) return {'name':'alex'} t1=test01() t2=test02() t3=test03() t4=test04() print(t1) #None print(t2) #test02 返回值只有一个,返回原对象 print(t3) #(1,2,3,4,'a',['alex'],{'name':'alex'},None) 返回值不止一个,结果为所有返回值组成的一个元祖 print(t4) #['name':'alex'] 只有一个字典对象,则类似于test02,返回一个字典对象
总结:当一个函数/过程没有使用return显示的定义返回值时,python解释器会隐式的返回None,
所以在python中即便是过程也可以算作函数。
1 def test01():
2 pass
3
4 def test02():
5 return 0
6
7 def test03():
8 return 0,10,'hello',['alex','lb'],{'WuDaLang':'lb'}
9
10 t1=test01()
11 t2=test02()
12 t3=test03()
13
14
15 print 'from test01 return is [%s]: ' %type(t1),t1
16 print 'from test02 return is [%s]: ' %type(t2),t2
17 print 'from test03 return is [%s]: ' %type(t3),t3
总结:
返回值数=0:返回None
返回值数=1:返回object
返回值数>1:返回tuple
四 函数参数
1.形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
2.实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值

3.位置参数和关键字
位置参数(标准调用):实参与形参位置一一对应;如上例
关键字调用:位置无需固定。c = calc(b = 1, a = 4)
如果上述两种调用方式混合使用,位置参数必须在关键字参数左边(所有传参的大原则)
一个参数绝对不可以传两次值
test(x, y, z) 代码块 test(1,y=2,3) #报错 test(1,3,y=2) #报错: 3先给了y,关键字过来,相当于又将2赋给y,y被传了两次值;同时z没有被赋值 test(1,2,z=3) #报错
test(1,2,z=3,y=4) #报错: 多了一个参数,“有多个值赋给了y”
4.默认参数,在函数参数表中提前就赋了一个值
def handle(x, type='mysql') print(x) print(type) handle('hello') #可以不传值,有默认值 handle('hello','adj') #可以传值,覆盖掉原来的,位置 handle('hello',type='adj') #可以传值,覆盖掉原来的,关键字
5.参数组:**字典,*列
def test(x,*args)
print(x
print(a
test(1,2,3,4,5,6) #1 (2,3,4,5,6)直接当成元祖
#函数后期可以扩展为多个参数值
def test(x,*args)
print(x)
print(args)
# 只要是按照位置参数的形式传值,就会集体当做元祖
test(1,2,3,4,5,6) #1 后面集体当成一个元祖(2,3,4,5,6)
test(1,[2,3,4,5,6]) #1 不加*号,表示传入的一个列表也当成整体,作为元祖的一个元素([2,3,4,5,6])
test(1,*[2,3,4,5,6]) #1 加*号,表示传入的一个列表中元素依次遍历,分别放入元祖(2,3,4,5,6)
# *args接收位置传值
def test(x,*args)
print(args) #([2,3,4,5,6])
print(args[0][0]) # 2 索引出了元祖的第一个元素,为列表,再索引出列表的第一个元素
test(1,**{'name':'alex'}) #传字典
##test(1,y=2,z=3) #报错,关键字传法,用*args没有办法接收,它只能接收可以视为一个元祖的
#**kwargs接收关键字传值def test(x,**kwargs) #kwargs部分将会输出字典
print(x) #1
print(kwargs)
test(1,y=2,z=3) #{'y':2,'z':3}
def test(x,*args,**kwargs) #只能按这个顺序,因为*args只能接收位置参数传的值,而位置参数只能在关键字参数左边 print(x) #1 print(args) #(1,2,1,1,11,1) print(kwargs) #{'y': 2,'z': 3} test(1,1,2,1,1,11,1,y=2,z=3) ##arg也可以通过索引取出部分值,kwargs可以通过key取 print(arg[-1]) #打印出arg中最后一个元素 print(kwargs['y']) #打印出y作为key的字典value值 def test(x,*args,**kwargs) print(x) #1 print(args,args[-1]) #(1,2,33) 33 print(kwargs, kwargs.get('a')) #{'a': 1} 1 test(1,*[1,2,33],**{'a':1}) ### kwargs['a'] 不能用这种方式取关键字,应该用get(),否则报错
五 局部变量和全局变量
1 name='lhf'
2
3 def change_name():
4 print('我的名字',name)
5
6 change_name() #调用函数的时候才会执行函数里面的
7
8 # 情况一:无global关键字,声明局部变量
9 def change_name():
10 name='帅了一笔' # 没有global声明,在函数内部自己创建一个新的局部变量name,无法对全局变量name直接进行赋值
11 print('我的名字',name) # 优先读取局部变量,如果才读取全局变量name
12
13 change_name()
14 print(name)
15
16
17 # 情况二: 有global关键字,无声明局部变量(实际是引用了全局变量),可以直接对全局变量进行所有操作。
18 def change_name():
19 global name # 有global关键字,将全局的name拿过来,不新创造
20 name='帅了一笔' # 修改上一句声明那拿过来的变量
21 print('我的名字',name) # 我的名字帅了一笔
22
23 change_name()
24 print(name) #帅了一笔
# 情况三:无global关键字,无声明局部变量。可以对全局变量内部元素进行操作:append、remove、clear等都能用 def change_name(): name.append('帅了一笔') # 没有global声明,并没有直接对全局变量name进行赋值,但对可变类型,可以对内部元素进行操作 print('我的名字',name) # 优先读取局部变量,如果才读取全局变量name
#错误示例:有global有声明局部变量 def change_name(): name='帅了一笔' #创建一全局变量 global name #把全局变量叫过来 print('我的名字',name) #直接报错,不知道找哪个了 #因此,每次要使用到全局变量时,一定要把全局变量声明到函数一开始的地方。 #规范:全局变量名都定义为全大写,局部变量名小写
##nonlocal name = "刚娘" def weihou(): name = "陈卓" def weiweihou(): nonlocal name # nonlocal,指定上一级变量,如果没有就继续往上直到找到为止 name = "冷静" weiweihou() print(name) print(name) weihou() print(name) # 刚娘 # 冷静 # 刚娘
##global
name = "刚娘" def weihou(): name = "陈卓" def weiweihou(): global name # globall,指定全局变量(最外层的) name = "冷静" weiweihou() #step2此函数将全局的name改为“冷静” print(name) #step3打印weihou函数中的局部变量“陈卓” print(name) #step1 weihou() print(name) #step4,打印被修改后的全局变量name # 刚娘 # 陈卓 # 冷静
六 前向引用之'函数即变量'
#情况一:内部出现没有定义过的函数,报错 def foo(): print('from foo') bar() foo() #报错 # 修正:定义一下bar()函数 #情况二:在fool函数定义前,定义bar(),可以运行 def bar(): print('from bar') def foo(): print('from foo') bar() foo() #正常运行 # 情况三:在fool函数定义完后再定义bar(),可以运行 def foo(): print('from foo') bar() def bar(): print('from bar') foo() # 情况四:在fool函数执行调用完后再定义bar(),报错 def foo(): print('from foo') bar() foo() def bar(): print('from bar')
七 嵌套函数和作用域
看上面的标题的意思是,函数还能套函数?of course
1 name = "Alex"
2
3 def change_name():
4 name = "Alex2"
5
6 def change_name2():
7 name = "Alex3"
8 print("第3层打印",name)
9
10 change_name2() #调用内层函数
11 print("第2层打印",name)
12
13
14 change_name()
15 print("最外层打印",name)
此时,在最外层调用change_name2()会出现什么效果?
没错, 出错了, 为什么呢?
作用域在定义函数时就已经固定住了,不会随着调用位置的改变而改变
1 例一: 2 name='alex' 3 4 def foo(): 5 name='lhf' 6 def bar(): 7 print(name) 8 return bar 9 10 func=foo() 11 func() 12 13 14 例二: 15 name='alex' 16 17 def foo(): 18 name='lhf' 19 def bar(): 20 name='wupeiqi' 21 def tt(): 22 print(name) 23 return tt 24 return bar 25 26 func=foo() 27 func()()
八 递归调用
古之欲明明德于天下者,先治其国;欲治其国者,先齐其家;欲齐其家者,先修其身;欲修其身者,先正其心;欲正其心者,先诚其意;欲诚其意者,先致其知,致知在格物。物格而后知至,知至而后意诚,意诚而后心正,心正而后身修,身修而后家齐,家齐而后国治,国治而后天下平。
在函数内部,可以调用其他函数。如果在调用一个函数的过程中直接或间接调用自身本身
# 递归:直接自己调用自己 def calc(n) print(n) calc(n) #死循环,在内存中以栈的形式保存,会耗尽内存 calc(n) # 递归特性1:一定要有一个结束条件(函数遇到return就终止) def calc(n): print(n) if int(n / 2) == 0: return n res=calc(int(n / 2)) return res res=calc(10) print(res) #运行结果:10 5 2 1
#问路:只有linhaifeng知道
import time person_list=['alex','wupeiqi','yuanhao','linhaifeng','zsc'] def ask_way(person_list): print('-'*60) #判断是否问完了所有人 if len(person_list) == 0: return '根本没人知道' person=person_list.pop(0) #问道linhaifeng,即问到路了 if person == 'linhaifeng': return '%s说:我知道,老男孩就在沙河汇德商厦,下地铁就是' %person print('hi 美男[%s],敢问路在何方' % person) #打印问路语句 print('%s回答道:我不知道,但念你慧眼识猪,你等着,我帮你问问%s...' % (person, person_list)) time.sleep(100) #模拟问路需要时间,一次循环时间延长一段时间 res=ask_way(person_list) #下一个人递归调用本函数。res截取询问结果 print('%s问的结果是: %res' %(person,res)) #应该在此处打印,此处出来了所有结果 return res res=ask_way(person_list) print(res)
运行结果:

递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
尾递归优化:http://egon09.blog.51cto.com/9161406/1842475
#二分查找 data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35] def binary_search(dataset,find_num): print(dataset) if len(dataset) >1: mid = int(len(dataset)/2) if dataset[mid] == find_num: #find it print("找到数字",dataset[mid]) elif dataset[mid] > find_num :# 找的数在mid左面 print("�33[31;1m找的数在mid[%s]左面�33[0m" % dataset[mid]) return binary_search(dataset[0:mid], find_num) else:# 找的数在mid右面 print("�33[32;1m找的数在mid[%s]右面�33[0m" % dataset[mid]) return binary_search(dataset[mid+1:],find_num) else: if dataset[0] == find_num: #find it print("找到数字啦",dataset[0]) else: print("没的分了,要找的数字[%s]不在列表里" % find_num) binary_search(data,66)
###函数作用域 def test(): pass print(test) #将会打印函数test的内存地址 def test1(): print('in the test1') def test(): print('in the test') return test1 #返回test1的函数名 print(test) #将会打印函数test1的内存地址 res=test() #执行test函数,打印出“in the test” 同时返回值给res=test1 print(res()) #将会运行test1(),其内部打印出in the test1。外层print将打印test1()的返回值,缺省为None # 输出结果为:in the test in the test1 None #函数的作用域只跟函数声明时定义的作用域有关,跟函数的调用位置无任何关系 name = 'alex' def foo(): name='linhaifeng' def bar(): # name='wupeiqi' print(name) return bar # a=foo() #a就是bar的内存地址 print(a) a() #相当于运行bar(),打印linhaifeng。如果bar()中还定义了wupeiqi,则打印wupeiqi name='alex' def foo(): name='lhf' def bar(): name='wupeiqi' print(name) def tt(): print(name) return tt return bar bar=foo() #bar内存地址 tt=bar() #tt内存地址 print(tt) tt() # wupeiqi 并打印出内存地址:<function foo.<locals>.bar.<locals>.tt at 0x017041E0> r1 = foo() # 返回bar函数 r2 = r1() # foo()()来运行bar(),返回tt函数 r3 = r2() # foo()()()来运行tt()
九 匿名函数
匿名函数就是不需要显式的指定函数
1 #这段代码 2 def calc(n): 3 return n**n 4 print(calc(10)) 5 6 #换成匿名函数 7 calc = lambda n:n**n 8 print(calc(10))
你也许会说,用上这个东西没感觉有毛方便呀, 。。。。呵呵,如果是这么用,确实没毛线改进,不过匿名函数主要是和其它函数搭配使用的呢,如下
1 l=[3,2,100,999,213,1111,31121,333]
2 print(max(l))
3
4 dic={'k1':10,'k2':100,'k3':30}
5
6
7 print(max(dic))
8 print(dic[max(dic,key=lambda k:dic[k])])
1 res = map(lambda x:x**2,[1,5,7,4,8]) 2 for i in res: 3 print(i) 4 5 输出 6 1 7 25 8 49 9 16 10 64
# 例1: lambda x:x+1 lamda不会独立存在不会独立存在 def calc(x): return x+1 res=calc(10) print(res) print(calc) print(lambda x:x+1) func=lambda x:x+1 print(func(10)) #例2:想要加上—_sb(字符串拼接) name='alex_sb' name='alex' def change_name(x): return name+'_sb' res=change_name(name) print(res) func=lambda x:x+'_sb' res=func(name) print('匿名函数的运行结果',res) # 例3:多个参数 func=lambda x,y,z:x+y+z print(func(1,2,3)) name1='alex' name2='sbalex' name1='supersbalex' # 例4:返回多个值时组合成一个元祖表示 def test(x,y,z): return x+1,y+1 #----->(x+1,y+1) lambda x,y,z:(x+1,y+1,z+1)
十 函数式编程(python中了解)
三大主流编程方法:面向过程、函数式、面向对象
1. 面向过程:找到解决问题的入口,按照一个固定的流程去模拟解决问题的流程
2. 函数式编程:函数式=编程语言定义的函数+数学意义的函数
函数内对象是永恒不变的要么参数是函数,要么返回值是函数,没有for和while循环。所有循环都由递归来实现,没有变量的赋值,即不用变量去保存状态,无赋值即不改变。
特征:1).不可变数据:不用变量去保存状态,无赋值即不改变变量值
2)第一类对象:函数即变量。函数名可以当参数传递;返回值可以是函数名。
3)尾调用优化(尾递归):在函数的最后一步调用另外一个函数(最后一行不一定是函数的最后一步)。递归要保留上一层的运行状态,利用栈实现。
#第一种:无需保存上一次的test函数状态 def test() print('from test') test() test() #第二种:需保存上一次的test函数状态: def test() print('from test') test() #需要等待第二层的运行结束了,才能继续运行第一层没运行完的 print('1111') test() #尾调用:在函数的最后一步调用另外一个函数 #1、函数bar在foo内为尾调用 def bar(n): return n def foo(x): return bar(x) #2、函数bar1和bar2在foo内均为尾调用,二者在if不同的条件下都有可能执行最后一步 def bar1(n): return n def bar2(n): return n+1 def foo(x): if type(x) is str: return bar1(x) elif type(x) is int: return bar2(x) #3、函数bar在foo中非尾调用 def bar(n): return n def foo(x): y=bar(x) return y #这才是最后一步 #4、函数bar在foo中非尾调用 def bar(n): return n def foo(x): return bar(x)+1 ###实际上是两步:第一步:res=bar(x) 第二步:return res+1
峰哥原创面向过程解释:
函数的参数传入,是函数吃进去的食物,而函数return的返回值,是函数拉出来的结果,面向过程的思路就是,把程序的执行当做一串首尾相连的函数,一个函数吃,拉出的东西给另外一个函数吃,另外一个函数吃了再继续拉给下一个函数吃。。。
例如:
用户登录流程:前端接收处理用户请求-》将用户信息传给逻辑层,逻辑词处理用户信息-》将用户信息写入数据库
验证用户登录流程:数据库查询/处理用户信息-》交给逻辑层,逻辑层处理用户信息-》用户信息交给前端,前端显示用户信息
高阶函数
满足俩个特性任意一个即为高阶函数
1.函数的传入参数是一个函数名
2.函数的返回值是一个函数名
# 非高阶函数: def foo(n): #n=bar print(n) def bar(name): print('my name is %s' %name) foo(bar) #把bar函数的内存地址传给foo的形参,即函数名直接当成变量传入了 # foo(bar()) #报错,bar是一个需要传值的函数 foo(bar('alex')) # 运行结果: # my name is alex # None 将bar('alex')函数运行后的返回值传给foo的形参,由于bar没有返回值,foo打印None #高阶函数例子:返回值中包含函数 #例子1: def bar(): print('from bar') def foo(): print('from foo') return bar n=foo() n() #例子2: def handle(): print('from handle') return handle #返回函数名而且是自己 h=handle() h() #直接调用自己 #例子3: def test1(): print('from test1') def test2(): print('from handle') return test1() #直接返回test1的运行后的返回值
 map函数:将原列表中每个元素处理一遍,得到的还是一个列表。该‘列表’元素个数及位置与原来一样。
map函数:将原列表中每个元素处理一遍,得到的还是一个列表。该‘列表’元素个数及位置与原来一样。# 例1:得到一个新列表,每个元素对应原列表中每个元素的平方 num_l=[1,2,10,5,3,7] ret=[] for i in num_l: ret.append(i**2) print(ret) # 运行结果为:[1,4,100,25,9,49] # 例2:现在有一万个这样的列表,就需要构建一个函数了 def map_test(array): ret=[] for i in num_l: ret.append(i**2) return ret ret=map_test(num_l) rett=map_test(num1_l) print(ret) print(rett) # 例3:不仅灵活改变函数,还要改变变量数据 # 让每个函数自增一 num_l=[1,2,10,5,3,7] #lambda x:x+1 def add_one(x): return x+1 # 让每个元素自减一 num1_l=[1,2,10,5,3,7] #lambda x:x-1 def reduce_one(x): return x-1 # 让每个元素平方 #lambda x:x**2 def pf(x): return x**2 # 函数调用部分: def map_test(func,array): #传入函数名(形参)func,形参数组array ret=[] for i in num_l: res=func(i) #add_one(i) ret.append(res) return ret print(map_test(add_one,num_l)) print(map_test(lambda x:x+1,num_l)) print(map_test(reduce_one,num_l)) print(map_test(lambda x:x-1,num_l)) print(map_test(pf,num_l)) print(map_test(lambda x:x**2,num_l)) #终极版本:自增一为例 def map_test(func,array): #func=lambda x:x+1 arrary=[1,2,10,5,3,7] ret=[] for i in array: res=func(i) #add_one(i) ret.append(res) return ret print(map_test(lambda x:x+1,num_l)) #由于本问题函数方法很简单,所以可以直接用匿名函数传入 # [2,3,11,6,4,8] # python中内置函数map:用方法对可迭代对象依次进行for循环,然后得到处理结果为一个可迭代对象(列表) res=map(lambda x:x+1,num_l) #map(处理方法,可迭代对象) print('内置函数map,处理结果',res) # 内置函数map,处理结果<map object at 0x000000000001135DA0> # 打印出来了一个可迭代对象的地址,因此想把此可迭代对象用for打印出来: for i in res: print(i) # 2 3 11 6 4 8 # list也可以传一个可迭代对象。 # 但此代码不能在对res迭代循环处理之后再运行,否则是一个空列表。这是res迭代器的性质 print(list(res)) # [2,3,11,6,4,8] # 方法不一定是lambda:将传入map的方法改写为自己定义的函数,也可以实现 print('传的是有名函数',list(map(reduce_one,num_l))) # 结果:传的是有名函数 [0,1,9,4,2,6] # 例4:传入的对象只要是可迭代对象就可以,不一定是列表,如字符串也可以: msg='chenqiuxi' print(list(map(lambda x:x.upper(),msg))) #全打印成大写,但仍是列表形式 # ['C','H','E','N','Q','I','U','X','I']
reduce函数:对原来完整的序列数据压缩合并操作,得到一个值。类似于大数据里的mapreduce# 在python3中已经封装成一个模块了 导入:from functools import reduce # 例1:将列表中 所有元素求和 num_l=[1,2,3,100] # 方法一: res=0 for num in num_l: res+=num #106 print(res) # 方法二:某固定函数 num_l=[1,2,3,100] def reduce_test(array): res=0 for num in array: res+=num return res print(reduce_test(num_l)) # 方法三:写活逻辑: num_l=[1,2,3,100] def multi(x,y): return x*y lambda x,y:x*y def reduce_test(func,array): res=array.pop(0) # 如果是乘法,res初始化为1,如果是加法应该选0。 # 因此,为了通用性,我们把第一个数弹出来放在res中,array中第一个数也没有了,直接放入res for num in array: res=func(res,num) return res print(reduce_test(lambda x,y:x*y,num_l)) # 方法四:拓展功能:多加入一个初始值 num_l=[1,2,3,100] def reduce_test(func,array,init=None): if init is None: res=array.pop(0) # 用户没有输入初始值,就用自己列表中的 else: res=init for num in array: res=func(res,num) return res print(reduce_test(lambda x,y:x*y,num_l,100)) # reduce函数:把原来完整的数据压缩合并到一块,得到一个值。类似于大数据里的mapreduce from functools import reduce num_l=[1,2,3,100] print(reduce(lambda x,y:x+y,num_l,1)) #107 一次赋两个值x和y print(reduce(lambda x,y:x+y,num_l)) #106
filter函数:遍历序列中的每个元素,判断每个元素得到布尔值,如果是True则留下来# 一、过滤掉不满足条件的元素 # 例1:过滤掉以sb开头的 movie_people=['sb_alex','sb_wupeiqi','linhaifeng','sb_yuanhao'] def filter_test(array): ret=[] for p in array: if not p.startswith('sb'): #想要过滤掉不是以sb开头的 ret.append(p) #不是以sb开头的就追加到列表中 return ret res=filter_test(movie_people) print(res) # PS: 不能这么打印:print(res=filter_test(movie_people))就像在打印一个赋值过程一样,必报错 # 例2:过滤掉sb结尾的 movie_people=['alex_sb','wupeiqi_sb','linhaifeng','yuanhao_sb'] def sb_show(n): return n.endswith('sb') # 因此,为了以后能方便地更换逻辑方法,自己引入func def filter_test(func,array): ret=[] for p in array: if not func(p): ret.append(p) return ret res=filter_test(sb_show,movie_people) print(res) #终极版本 movie_people=['alex_sb','wupeiqi_sb','linhaifeng','yuanhao_sb'] # def sb_show(n): # return n.endswith('sb') #--->lambda n:n.endswith('sb') def filter_test(func,array): ret=[] for p in array: if not func(p): ret.append(p) return ret res=filter_test(lambda n:n.endswith('sb'),movie_people) print(res) # 二、filter函数: movie_people=['alex_sb','wupeiqi_sb','linhaifeng','yuanhao_sb'] print(filter(lambda n:not n.endswith('sb'),movie_people)) # <filter object at 0x000000000001195D68> # 打印出的是一个可迭代对象的地址 # 因此用list把它取出来 res=filter(lambda n:not n.endswith('sb'),movie_people) print(list(res)) # 过滤删去非sb结尾的 # ['alex_sb','wupeiqi_sb','yuanhao_sb'] # filter处理逻辑:把后面的可迭代对象用前面的方法处理得到一个bool,若为true保留对应元素, 也可以直接合并为一步: print(list(filter(lambda n:not n.endswith('sb'),movie_people))) # ['alex_sb','wupeiqi_sb','yuanhao_sb']
总结十一 内置函数


1 # 1、取绝对值: 2 print(abs(-1)) 3 print(abs(1)) 4 5 # 2、all()把序列中每个元素拿出来做bool运算:【0、空、none】才为假 6 # 当所有元素都为True,all的结果返回True。 当all中为空(只能一个可迭代的空),返回ture 7 print(all([1,2,'1'])) #Ture 8 print(all([1,2,'1',''])) #False 有一个空字符串就为假 9 print(all('hello')) #True 这是一个字符串,就判断了一次。不是列表,也不是一个个字符 10 print(all('')) #True 11 print(all([])) #True 12 print(all('','')) #False 13 14 # 3、any()只要有一个为真就True 15 print(any([0,''])) 16 print(any([0,'',1])) 17 18 # 4、bin()转化为二进制 19 print(bin(3)) #0b11 20 21 # 5、bool()求布尔值。空,None,0的布尔值为False,其余都为True 22 print(bool('')) #False 23 print(bool(None)) #False 24 print(bool(0)) #False 25 26 # 6、bytes()把字符串转化为字节形式。一定要写编码方式。为了之后网络传输,转换为二进制 27 # 不能写Unicode,它是内存中 28 # 用什么编码encoding,就一定要用相同的解码decode 29 name='你好' 30 print(bytes(name,encoding='utf-8')) # 打印出的是x形式,即十六进制表示 31 print(bytes(name,encoding='utf-8').decode('utf-8')) 32 33 print(bytes(name,encoding='gbk')) # 打印出的是x形式,即十六进制表示 34 print(bytes(name,encoding='gbk').decode('gbk')) 35 ## print(bytes(name,encoding='gbk').decode()) #如果不写解码用什么,系统默认用utf8来解码。此行报错。 36 37 ##print(bytes(name,encoding='ascii')) #ascii不能编码中文,报错 38 39 #7、chr()将字母的ASCII码值转化为相应字母 40 print(chr(97)) #a 41 42 #8、dir()打印某对象下面的属性、方法名字 43 print(dir(dict)) 44 45 #9、devmod()得到俩数的商和余数: 46 # 用途:做页面分页:将总页数,和每页显示多少输入到divmod中,计算出一共有多少页,最后一页有多少条数据。 47 print(divmod(10,3)) #(3,1) 48 49 #10、eval() 50 # 功能1:用于提取字符串中原有数据 51 dic={'name':'alex'} 52 dic_str=str(dic) ##将字典转化为字符串 '{'name':'alex'}' 53 eval(dic_str) {'name':'alex'} 54 #功能2:计算字符串中的计算值 55 express = '1+2*(3/3-1)-2' #这是一个字符串 56 eval(express) #-1.0 57 58 # 11、hash() 可hash的数据类型即不可变数据类型,不可hash的数据类型即可变数据类型 59 # 用途:无病毒的软件计算一个hash值,用户下载下来后对软件算hash值与原hash对比,相同说明没有没篡改过。从而防止病毒。 60 print(hash('12sdfdsaf3123123sdfasdfasdfasdfasdfasdfasdfasdfasfasfdasdf')) 61 print(hash('12sdfdsaf31231asdfasdfsadfsadfasdfasdf23')) 62 63 name='alex' 64 print(hash(name)) 65 print(hash(name)) 66 67 print('--->before',hash(name)) 68 name='sb' 69 print('=-=>after',hash(name)) 70 71 # 12、help()打印方法具体解释 72 print(help(all)) 73 74 # 13、进制转换 75 print(bin(10))#10进制->2进制 76 print(hex(12))#10进制->16进制 77 print(oct(12))#10进制->8进制 78 79 # 14、isinstance()判断传入数据是不是相应的数据类型 80 print(isinstance(1,int)) #True 判断是不是int类型 81 print(isinstance('abc',str)) #True 82 print(isinstance([],list)) #True 83 print(isinstance({},dict)) #True 84 print(isinstance({1,2},set)) #True 85 86 # 15、global()打印全局变量 87 name='哈哈哈哈哈哈哈哈哈哈哈哈哈哈啊哈粥少陈' 88 print(globals()) 89 print(__file__) #打印文件路径 90 91 # 16、locals()打印局部变量 92 def test(): 93 age='1111111111111111111111111111111111111111111111111111111111111' 94 print(globals()) #name被打印 95 print(locals()) #age被打印 96 test() 97 98 # 17、最大最小值:只要是可迭代对象就可以用 99 l=[1,3,100,-1,2] 100 print(max(l)) 101 print(min(l)) 102 103 # 18、zip()拉链算法:多了的不要,能匹配几个尽可能匹配 104 # 传入的两个参数都是序列类型:元祖、列表、字典 105 print(list(zip(('a','n','c'),(1,2,3)))) #[('a',1),('n',2),('c',3)]一一对应 106 print(list(zip(('a','n','c'),(1,2,3,4)))) #[('a',1),('n',2),('c',3)]右边多 107 print(list(zip(('a','n','c','d'),(1,2,3)))) #[('a',1),('n',2),('c',3)]左边多 108 109 p={'name':'alex','age':18,'gender':'none'} 110 print(list(zip(p.keys(),p.values()))) #[('name','alex'),('age',18),('gender','none')] 111 # print(list(p.keys())) #['name''age','gender'] 112 # print(list(p.values())) #[18,'alex','none'] 113 114 print(list(zip(['a','b'],'12345'))) #[('a','1'),('b','2')] 115 116 # 17、maxmin功能补充 117 # 例1:取出年纪的最大最小值 118 age_dic={'age1fdjgiiose':18,'age2dfv':20,'age3fd':100,'age4fbdsrg':30} 119 print(max(age_dic.values())) #100 把字典遍历for循环一遍,取出最大最小值 120 #默认比较的是字典的key,按照字符ASCII表字符串一位一位地比较比较 121 print(max(age_dic)) #age4fbdsrg 比较到第四位就直接得结果 122 123 # 例2:取出list中的最大值 124 l=[ 125 (5,'e'), 126 (1,'b'), 127 (3,'a'), 128 (4,'d'), 129 ] 130 # l1=['a10','b12','c10',100] #不同类型之间不能进行比较 131 l1=['a10','a2','a10'] #不同类型之间不能进行比较 132 print(list(max(l))) #(5,'e')先从第一个数开始比较,能比较出来就直接得结果 133 print('--->',list(max(l1))) #a2 134 135 # 例3:先要取出最大值及相应对应的人,即要取出一个key和对应的value 136 age_dic={'alex_age':18,'wupei_age':20,'zsc_age':100,'lhf_age':30} 137 for item in zip(age_dic.values(),age_dic.keys()): #利用zip组成新的数据类型[(18,'alex_age') (20,'wupeiqi_age') () () ()] 138 print(item) 139 # (18,'alex_age') 140 # (20,'wupei_age') 141 # (100,'zsc_age') 142 # (30,'lhf_age') 143 144 print('=======>',list(max(zip(age_dic.values(),age_dic.keys())))) 145 # [100,'zsc_age'] 146 147 # 例4:总结 148 l=[1,3,100,-1,2] 149 print(max(l)) 150 151 dic={'age1':18,'age2':10} 152 print(max(dic)) #比较的是key 153 154 print(max(dic.values())) #比较的是key,但是不知道是那个key对应的 155 156 print(max(zip(dic.values(),dic.keys()))) #结合zip使用 157 158 # 终极版本:取出年纪最大的 159 people=[ 160 {'name':'alex','age':1000}, 161 {'name':'wupei','age':10000}, 162 {'name':'yuanhao','age':9000}, 163 {'name':'linhaifeng','age':18}, 164 ] 165 # max(people) #报错:无序的字典不能比较。数字、字符串、集合可以比较。 166 # max(people,key=lambda dic:dic['age']) 167 print('取出来了',max(people,key=lambda dic:dic['age'])) #取出来了['name':'wupei','age':10000] 168 169 # 此句等价于如下循环: 170 ret=[] 171 for item in people: 172 ret.append(item['age']) 173 print(ret) 174 max(ret) 175 176 # 18、字符和ASCII互相转换 177 print(chr(97)) 178 print(ord('a')) 179 180 # 19、pow(a,b,c)乘方、取余 181 print(pow(3,3)) #3**3 182 print(pow(3,3,2)) #3**3%2 183 184 185 # 20、翻转 186 l=[1,2,3,4] 187 print(list(reversed(l))) #[4,3,2,1] 188 print(l) #[1,2,3,4] 处理完后并不修改原list 189 190 # 21、四舍五入 191 print(round(3.5)) #4 192 193 # 22、变成集合的形式 194 print(set('hello')) #{'h','o','l','e'} 195 196 # 23、slice()切片,左闭右开 197 l='hello' 198 s1=slice(3,5) #先切好 199 s2=slice(1,4,2) #14之间步长为2 200 # print(l[3:5]) #lo 取出3,4位,硬编码 201 print(l[s1]) #lo 202 print(l[s2]) #el 203 # 取出查看s2中silice的三个变量值 204 print(s2.start) #1 205 print(s2.stop) #4 206 print(s2.step) #2 207 208 209 # 24、sort()排序 210 l=[3,2,1,5,7] 211 l1=[3,2,'a',1,5,7] 212 print(sorted(l)) #[1,2,3,5,7] 213 # print(sorted(l1)) #排序本质就是在比较大小,不同类型之间不可以比较大小 214 215 # 按照年纪排序 216 people=[ 217 {'name':'alex','age':1000}, 218 {'name':'wupei','age':10000}, 219 {'name':'yuanhao','age':9000}, 220 {'name':'linhaifeng','age':18}, 221 ] 222 print(sorted(people,key=lambda dic:dic['age'])) 223 # [{'name':'linhaifeng','age':18}, {'name':'alex','age':1000},{'name':'yuanhao','age':9000},{'name':'wupei','age':10000},] 224 225 # 按数值排序 226 name_dic={ 227 'yuanhao': 11900, 228 'alex':1200, 229 'wupei':300, 230 } 231 print(sorted(name_dic)) #按key排序并直接只输出key 232 #['alex','wupei','yuanhao'] 233 print(sorted(name_dic.values())) #按values排序并直接只输出values 234 235 print(sorted(name_dic,key=lambda key:name_dic[key])) #按照name_dic[key]取出的value值来排序后输出排序后的name值 236 # 返回key值: ['wupei','alex'.'yuanhao'] 237 238 print(sorted(zip(name_dic.values(),name_dic.keys()))) #按照value排序后,输出key和values 239 # [(300,'wupei'),(1200,'alex'),(11900,'yuanhao')] 240 241 # 25、str()转化为字符串,在cmd中可以直接看,但在pycharm中打印,没有字符串的引号 242 print(str('1')) #‘1’ 243 print(type(str({'a':1}))) #“{'a':1}” 244 dic_str=str({'a':1}) 245 print(type(eval(dic_str))) #<class 'dic'> 利用eval看字符串中数据的类型 246 247 # 26、sum()求和 248 l=[1,2,3,4] 249 print(sum(l)) 250 print(sum(range(5))) #将生成的0,1,2,3,4求和 251 252 # 27、type() 253 # 用途1:看数据类型 254 print(type(1)) 255 256 msg='123' 257 # 用途2:得到一个数据之后需要进一步操作,则需要先知道其数据类型。避免不同数据类型导致的错误操作 258 if type(msg) is str: 259 msg=int(msg) 260 res=msg+1 261 print(res) #124 262 263 # 28、vars() 264 def test(): 265 msg='撒旦法阿萨德防撒旦浪费艾丝凡阿斯蒂芬' 266 print(locals()) #字典形式打印出局部变量:[msg:'撒旦法阿萨德防撒旦浪费艾丝凡阿斯蒂芬'] 267 print(vars()) # vars没有参数和locals相同:[msg:'撒旦法阿萨德防撒旦浪费艾丝凡阿斯蒂芬'] 268 test() 269 print(vars(int)) #有一个参数,与object._dict_相同:将某一功能下的方法名字全放入一个字典当中 270 271 # 29、导入模块(就是一个py文件) 272 import------>sys----->__import__() # 所以import最终导入的在OS底层都是字符串类型 273 import test #文件名test 274 test.say_hi() 275 276 # import 'test' #报错,py文件名中是一个字符串,不能用import,要结合一个变量和__import__来导入字符串类型的文件名 277 module_name='test' 278 m=__import__(module_name) 279 m.say_hi()
十二 本节作业
有以下员工信息表
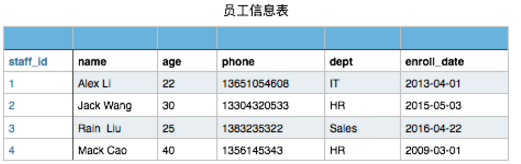
当然此表你在文件存储时可以这样表示
1 1,Alex Li,22,13651054608,IT,2013-04-01
现需要对这个员工信息文件,实现增删改查操作
- 可进行模糊查询,语法至少支持下面3种:
- select name,age from staff_table where age > 22
- select * from staff_table where dept = "IT"
- select * from staff_table where enroll_date like "2013"
- 查到的信息,打印后,最后面还要显示查到的条数
- 可创建新员工纪录,以phone做唯一键,staff_id需自增
- 可删除指定员工信息纪录,输入员工id,即可删除
- 可修改员工信息,语法如下:
- UPDATE staff_table SET dept="Market" WHERE where dept = "IT"
注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!
View Code