第一讲
1、通过nutch,诞生了hadoop、tika、gora。
2、nutch通过ivy来进行依赖管理(1.2之后)。
3、nutch是使用svn进行源代码管理的。
4、lucene、nutch、hadoop,在搜索界相当有名。
5、ant构建之后,生成runtime文件夹,该文件夹下面有deploy和local文件夹,分别代表了nutch的两种运行方式(分布式和本地模式)。
6、nutch和hadoop是通过什么连接起来的?通过nutch脚本。通过hadoop命令把apache-nutch-1.6.job提交给hadoop的JobTracker。
7、nutch入门重点在于分析nutch脚本文件。
第二讲
1、git来作为分布式版本控制工具,github作为server。bitbucket.org提供免费的私有库。
2、nutch的提高在于研读nutch-default.xml文件中的每一个配置项的实际含义(需要结合源代码理解)。
3、定制开发nutch的入门方法是研读build.xml文件。
4、命令:
1、有的系统因为刚安装没有svn, 可以先用apt-get update对其本地库进行更新
2、apt-get install subversion 安装svn
3、svn co https://svn.apache.org/repos/asf/nutch/tags/release-1.6/
因为nutch的源码是通过svn进行管理的,所以这里可以直接使用svn客户端工具对其进行下载
4、cd release-1.6
apt-get install ant 安装ant,ant是以一个build.xml为配置
ant (ant使用时候,必须切换到release1.6目录下,即有build.xml的目录下)
第一次ant会很慢,因为要下在很多需要的包,执行过ant以后,会出现一个runtime的包
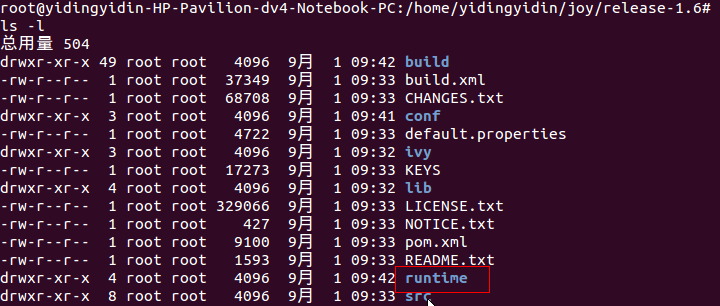
5、cd runtime/local
mkdir urls
vi urls/url.txt 并输入http://blog.tianya.cn (首次注入的url)
6、nohup bin/nutch crawl urls -dir data -depth 3 -threads 100 &
上条语句是视频中所有的语句,为了能够看到运行的情况,使用一下语句即可(nohup表示将输出信息输入到nohup文件下,&表示使用后台运行模式)
为了能够看到抓去的信息,我采用了以下语句:
bin/nutch crawl urls -dir data -depth 2 -threads 20 | tee logx
crawl为抓去命令
urls为注入的url地址的保存文件
-dir data 表示把数据保存到data文件夹下
-depth 表示抓去深度
-threads 表示线程数
| 表示管道
tee 表示在终端输出的同时将其保存到tee文件夹下
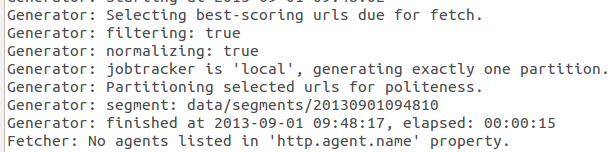
运行结果:
logx中:
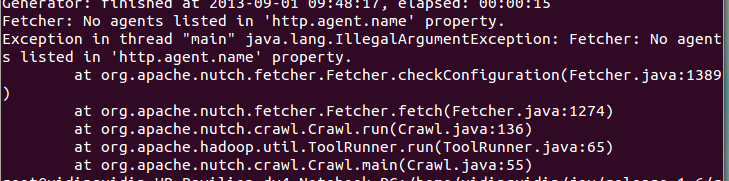
终端:
log/hadoop.log

通常查看日志可以从这三个角度去看,而因为java编译产生的问题只能从终端看到,这个问题则是agents没有设置的问题,agent在conf下的nutch-site.xml
7、设置agent
在local下的conf,有nutch-default.xml和nutch-site.xml,其中后者将直接被nutch读取。前者可以看作是默认的模版

vi release-1.6/conf/nutch-site.xml 增加http.agent.name配置
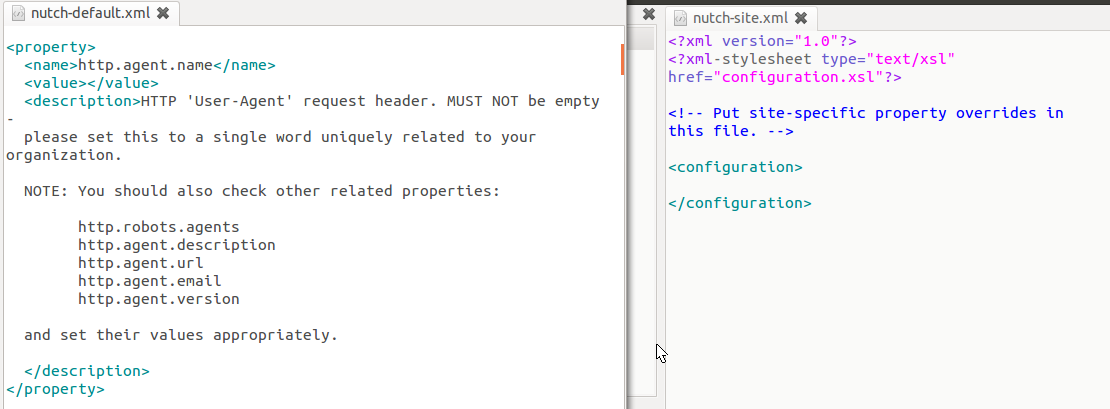
修改后的nutch-site.xml 如下:
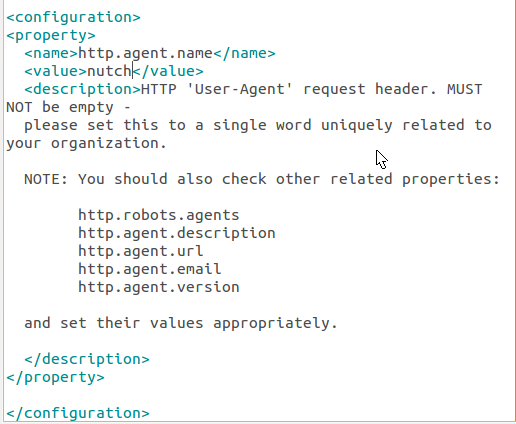
修改好以后需要重新用ant编译
cd ../../release-1.6
ant
cd runtime/local
bin/nutch crawl urls -dir data -depth 2 -threads 20 | tee logx
生成一个错误,因为之前的一个错误的执行,导致了一个文件路径找不到,只要删除data即可

删除报错的文件夹
bin/nutch crawl urls -dir data -depth 2 -threads 20 | tee logx
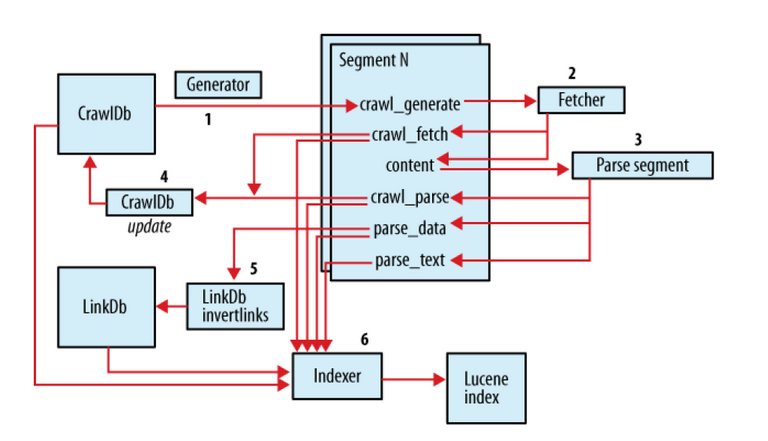
日志简读


Injector:注入url
Generator:生成抓取列表
Fetcher:抓取网页
PareseSegment:解析网页
CrawlDb:更新抓去列表
以上便是Nutch的一个执行周期,需要注意的似乎Injector只有在第一次执行的时候需要从urls注入,其他步骤后来成为一个循环