一、设备与模块
1.设备类型
- 块设备:随机访问设备中的内容,通过块设备结点访问,通常被挂载为文件系统
- 字符设备:不可寻址,仅提供数据的流式访问,通过字符设备结点访问,应用程序通过直接访问设备节点与字符设备交互
- 网络设备:通过套接字API来访问
除了物理设备外还有些驱动设备是虚拟的(伪设备),仅提供访问内核功能。如内核随机数发生器、空设备、零设备、满设备、内存设备。
2.模块
(1)Linux内核是模块化的,允许内核在运行时动态地向其中插入或从中删除代码。这些代码被组合在一个单独的二进制镜像中,即可装载内核模块。模块是具有独立功能的程序,它可以被单独编译,但不能独立运行。它在运行时被链接到内核作为内核的一部分在内核空间运行。利用内核模块的动态装载性可以将内核映象的尺寸保持在最小,并具有最大的灵活性,同时便于检验新的内核代码,而不需重新编译内核并重新引导。
#include<linux/module.h>
#include<linux/init.h>
#include<linux/kernel.h>
static int hello_init(void)
{
printk(KERN_ALERT"Hi module!
");
return 0;
}
static void hello_exit(void)
{
printk(KERN_ALERT"Bye module!
");
}
module_init(hello_init);//hello_init模块入口函数,通过module_init例程注册到系统中,在模块加载时被调用
module_exit(hello_exit);//hello_exit模块入口函数,通过module_exit例程注册到系统中,在模块从内存卸载时被调用
MODULE_LICENSE()宏用于指定模块的版本,MODULE_AUTHOR()宏指定代码作者,MODULE_DESCRIPTION()是模块的简要说明。
(2)模块可以放在内核源码树中。设备驱动程序放在/drivers的子目录下,如字符设备放在/drivers/char/下,设备块放在/drivers/block/下 。在相应目录下的Makefile添加obj-m += ···.o;模块还可以放在内核源代码树之外,在自身源代码目录中建立Makefile,通过make命令找到源代码和Makefile。如果有多个源文件,用两行足够:
obj-m := fishing.o
fishing-objs :=fishing-main.o fishing-line.o
(3)编译后的模块被装入到/lib/modules/version/kernel/下,make modules_install安装编译的模块到合适的目录下。
- name :既是用户可见的参数名,也是模块中存放模块参数的变量名
- type :参数的类型(byte, short, int, uint, long, ulong, charp, bool...) byte型存放在char变量中,bool型存放在int变量中
- perm :指定模块在 sysfs 文件系统中对应的文件权限
insmod module.ko //载入模块
rmmod module.ko //卸载模块
modprobe module [参数] //加载依赖模块
modprobe -r modules //卸载依赖模块
module_param(name, type, perm)定义一个模块参数,用户可以在系统启动或者模块装载时再指定参数。
(4)模块被载入后,就会被动态地连接到内核。导出的内核函数可以被模块调用,未导出的则不可以。导出内核函数需要使用特殊的指令:EXPORT_ SYMBOL() (接在导出的函数后)EXPORT_SYMBOL_GPL()(和EXPORT_SYMBOL一样,区别在于只对标记为GPL协议的模块可见)
导出的内核符号表被看做导出的内核接口,称为内核API。
3.设备模型
(1)kobject是设备模型的核心部分,用struct kobject结构体表示,一般都是嵌在其他数据结构中来发挥作用。如:
struct cdev {
struct kobject kobj; //嵌在 cdev 中的kobject
struct module *owner;
const struct file_operations *ops;
struct list_head list;
dev_t dev;
unsigned int count;
};
cdev中嵌入了kobject之后,就可以通过 cdev->kboj.parent 建立cdev之间的层次关系,通过 cdev->kobj.entry 获取关联的所有cdev设备等。
总之,嵌入了kobject之后,cdev设备之间就有了树结构关系,cdev设备和其他设备之间也有可层次关系。
(2)kobject被关联到ktype,用kobj_type结构体表示,就是将某一族的kobject的属性统一定义一下,避免每个kobject分别定义。
(3)kset是kobject对象的集合体,可以所有相关的kobject置于一个kset之中。kset让其中嵌入的kobj创作为kobject组的基类,将相关的kobject集合在一起。
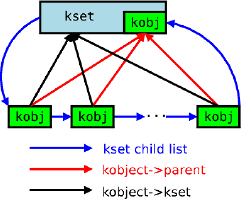
(4)kobject提供了一个统一的引用计数系统,通过kref结构体实现。初始化后,kobject的引用计数设置为1。引用计数不为零,该对象就会继续保留在内存中。引用计数跌到零时,对象可被撤销,相关内存也被释放。
4.sysfs
(1)sysfs是一个处于内存中的虚拟文件系统,它提供了kobject对象层次结构的视图。kobject是映射成sysfs中的目录,sysfs中的文件就是kobject的属性。
int sysfs_create_file(struct kobject *kobj, const struct attribute *attr);//添加新属性
void sysfs_remove_file (struct kobject *kobj, const struct attribute *attr);//删除属性
int sysfs_create_link(struct kobject *kobj, struct kobject *target, char *name);//在sysfs中创建一个符号连接
void sysfsremovelink(struct kobject *kobj , *char name);//删除由sysfs_ creat_ link()创建的符号连接可通过:
(2)为了保持sysfs的干净和直观,sysfs约定:
- 保证每个文件只导出一个值,该值为文本形式并且可以映射为简单的C类型
- 以一个清晰的层次组织数据
- 提供内核到用户空间的服务
5.思考
kset,ktype都和kobject有关,一个是集合,一个统一定义kobject属性,二者好像都是分类方法,那么有何区别?
参照《Linux内核设计与实现》读书笔记(十七)- 设备与模块
kset和ktype是为了将kobject进行分类,以便将共通的处理集中处理,从而减少代码量,也增加维护性。从整个内核的代码来看,kset的数量多于ktype的数量的,同一种ktype的kobject可以位于不同的kset中。
博主做了个比喻:如果把kobject比作一个人的话,kset相当于一个一个国家,ktype则相当于人种(比如黄种人,白种人等等)。人种的类型只有少数几个,但是国家确有很多,人种的目的是描述一群人的共通属性,而国家的目地则是为了管理一群人。即ktype侧重于描述,kset侧重于管理。
二、可移植性
1.内核编码中涉及到字长的部分时, 牢记以下准则:
- ANSI C标准规定, 一个char的长度一定是一个字节(8位)
- linux当前所支持的体系结构中, int型都是32位的
- linux当前所支持的体系结构中, short型都是16位的
- linux当前所支持的体系结构中, 指针和long型的长度不定, 在32位和64位中变化不能假设 sizeof(int) == sizeof(long),类似的不能假定指针的长度和int型相同
2.不透明数据类型隐藏了它们的内部格式或结构。利用typedef声明一个类型,把它叫做不透明类型,它们是在C语言标准类型上的一个封装。
使用这些不透明类型时, 以下原则需要注意:
- 不要假设该类型的长度(那怕通过源码看到了它的C语言类型), 这些类型在不同体系结构中可能长度会变
- 不要将这些不透明类型转换为C标准类型来使用
- 编程时保证不透明类型实际存储空间或者格式发生变化时代码不受影响
3.长度明确的类型只能在内核空间使用, 用户空间无法使用. 用户空间有对应的变量类型, 名称前多了2个下划线。在内核中可以任意使用这两个名字,但是用户可见的类型必须使用下划线前缀的版本。
4.char类型在不同的体系结构中, 有时默认是带符号的, 有时是不带符号的。所以给char类型赋值时, 明确是否带符号。
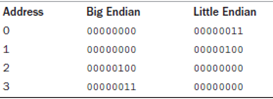
5.1027对应的二进制为00000000 00000000 00000100 00000011,高位优先字节顺序和地位优先字节顺序如图:
6.数据对齐:
- 通过指针转换类型时, 不要转换长度不一样的类型
- 对于数组, 安装基本数据类型进行对齐就行.(数组元素的存放在内存中是连续的, 第一个对齐了, 后面的都自动对齐了)
- 对于联合体, 长度最大的数据对齐即可
- 对于结构体, 保证结构体中每个元素能够正确对齐即可
7.应该使用 PAGE_SIZE 以字节数来表示页长度, 使用 PAGE_SHIFT 表示从最右端屏蔽了多少位能够得到该地址对应的页的页号。
三、补丁、开发和社区
- 缩进风格是用制表符(Tab)每次缩进8个字符长度(不是8个空格),每次缩进通过制表符进行,每个制表位8个字符长度。
- switch语句下属的case标记应该缩进到和switch声明对齐,这样将有助于减少8个字符的tab键带来的排版缩进。
- 左括号紧跟在语句的最后,与语句在相同的一行。而右括号要新起一行,作为该行的第一个字符。注意,在接下来的标识符是相同语句块的一部分,那么花括号就不单独占一行,而是与那个标识符在同一行。
- 名称中不允许使用骆驼拼写法、Studly Caps或者其他混合的大小写字符。而全局变量和函数应该选择包含描述性内容的名称,并且使用小写字母,必要时加上下划线区分单词。
- 在源码中少用typedef、ifdef。
diff -urN linux-old/ linux-new/ > my-patch //通过源码和加进了所修改部分的源代码两份代码创建补丁
diff -u linux-old/some/file linux-new/some/file > my-patch //对单独的文件进行diff
diffstat -p1 my-patch //列出补丁所引起的变更的统计(加入或移去的代码行)
git commit -a //提交所有修改的代码
git commit linux-src/some/file.c //提交某个修改的代码
git add linux-src/some/new-file.c // 把新增的文件加入版本库
git commit -a //Git并不立即提交新文件,直到把它们添加到版本库中才提交
git format-patch -N //生成最后N次提交产生的补丁