1. 集合是什么?
当我们需要保持一组一样(类型相同)的元素的时候,我们应该使用一个容器来保存,数组就是这样一个容器。那么,数组的缺点是什么呢?
数组一旦定义,长度将不能再变化。
然而在我们的开发实践中,经常需要保存一些变长的数据集合,于是,我们需要一些能够动态增长长度的容器来保存我们的数据。而我们需要对数据的保存的逻辑可能各种各样,于是就有了各种各样的数据结构。
我们将数据结构在Java中实现,于是就有了我们的集合框架。
2. 为什么用集合?
高效、方便地管理对象
3. 集合与数组有什么不同?
1). 数组是定长的,而集合长度是可以变换的
2). 数组中存储的都是相同的数据类型,而集合存储的可以是不同的数据类型
4. 集合的骨架是什么样的?
骨架图(非直接继承关系)

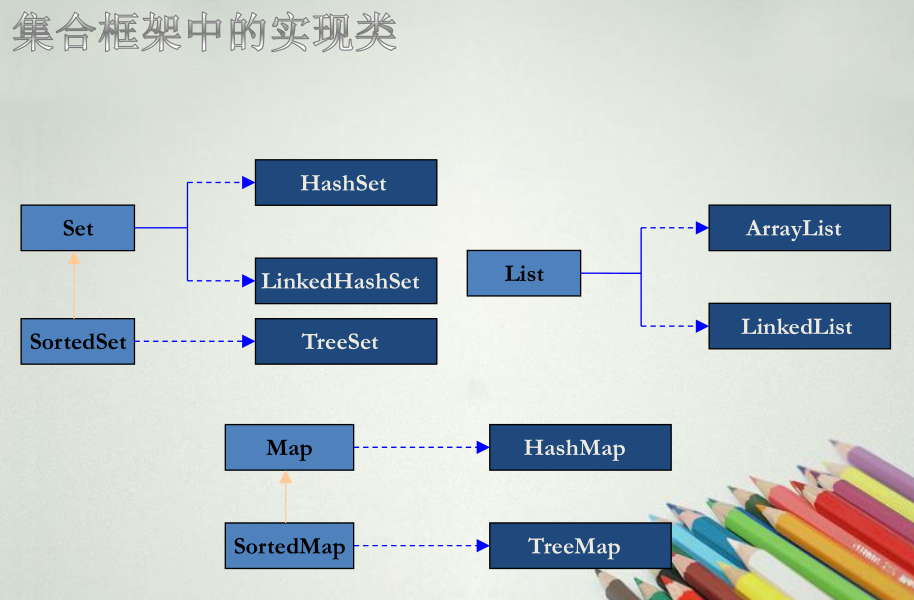
集合框架中的接口:
1). Collection:集合层次中的根接口,JDK没有提供这个接口直接的实现类。
2). Set:不能包含重复的元素。SortedSet是一个按照升序排列元素的Set。
3). List:是一个有序的集合,可以包含重复的元素。提供了按索引访问的方式。
4). Map:包含了key-value对,Map不能包含重复的key。SortedMap是一个按照升序排列key的Map。
5. 怎么使用集合?
参见:http://www.cnblogs.com/Jtianlin/p/4175710.html
6. 使用注意事项
List:
1). 底层机制:ArrayList与Vector都是基于数组实现的,这就说明ArrayList与Vector适合做遍历而不适合做频繁的插入和删除。LinkedList是基于链表实现的,所以它生来就是为了频繁插入与删除对象。
数组是一块连续的内存空间。ArrayList 的每一次有效的元素删除操作后都要进行数组的重组,并且删除的元素位置越靠前,数组重组时的开销越大,要删除的元素位置越靠后,开销越小。LinkedList 要
移除中间的数据需要遍历完半个List。
LinkedList 由于使用了链表的结构,因此不需要维护容量的大小,然而每次的元素增加都需要新建一个 Entry 对象,并进行更多的赋值操作,在频繁的系统调用下,对性能会产生一定的影响。
2). 内存占用:基于数组实现的List,在动态扩展时会产生新的数组,然后把旧数组里的内容复制到新数组里,这会产生大量的不再被使用的对象引用变量等待系统回收。而基于链表实现的List就不会有这种问题。
3). 同步问题:Vector与Stack生来就是同步的,而ArrayList与LinkedList需要使用Collections.synchronizedList(List list)方法来转换成同步List.从它们的对象上返回的迭代器是快速失败的,也就是说在使用
迭代器进行迭代的时候,必须使用迭代器本身的remove、add、set方法来添加或更改List元素,如果在迭代的同时,在其他线程中从结构上修改了List(结构上的修改是指任何添加或删除一个或多个
素的操作,或者显式调整底层数组的大小;仅仅设置元素的值不是结构上的修改),快速失败迭代器会尽最大努力抛出ConcurrentModificationException.
4). 不可修改:通过使用Collections.unmodifiableList(List list)来生成一个不可修改的List,试图修改返回的列表,不管是直接修改还是通过其迭代器进行修改,都将导致抛出UnsupportedOperationException.
5). 遍历器:请尽量使用Iterator,Enumeration已不被鼓励使用。
6). 使用策略:如果数据被从数据源提取,数据量不确定,该数据一经被提取后就几乎不会再添加或删除,那么应该建立一个LinkedList来保存从数据源中取出的数据,然后将该LinkedList转换成ArrayList
来优化遍历操作。反过来,数据量确定的数据从数据源取出可以先建立一个ArrayList来保存,根据需要如需频繁增删,就转换为LinkedList,如频繁遍历就不需转换。
转换的方法就是使用对应的List类来封装目标List对象。如:
ArrayList al = new ArrayList();
LinkedList ll = new LinkedList(al);
同理反过来也可以
LinkedList ll = new LinkedList();
ArrayList al = new ArrayList(ll);
7). 所有实现 Collection 接口的类都必须提供两个标准的构造函数,无参数的构造函数用于创建一个空的 Collection,有一个 Collection 参数的构造函数用于创建一个新的 Collection,这个新的 Collection 与
传入的 Collection 有相同的元素,后一个构造函数允许用户复制一个 Collection。
8). 大部分集合都可以包含null元素,但是有些集合不可以,例如:TreeSet
Map:
1). 底层机制:HashMap与Hashtable基于数组实现,TreeMap基于树型结构,底层存储结构是典型的链表结构。LinkedHashMap继承自HashMap,所以也是基于数组实现的。
2). 继承关系:HashMap与TreeMap继承自AbstractMap,Hashtable继承自Dictionary,LinkedHashMap继承自HashMap.
3). 同步关系:Hashtable是同步的,而HashMap与TreeMap以及LinkedHashMap不是同步的,可以使用Collections中提供的方法转换为同步的。
4). 迭代器:迭代器都是快速失败的(注:参考本系列第一篇List篇)
5). 不可修改:通过使用Collections.unmodifiableMap(Map map)来转换。
参见:http://blog.csdn.net/guoquanyou/article/details/3409202
7. 优化
1). 当需要插入大量元素时,在插入前可以调用 ensureCapacity 方法来增加 ArrayList 的容量以提高插入效率。
2). ArrayList和LinkedList的选择
3). LinkedHashMap 是根据元素增加或者访问的先后顺序进行排序,而 TreeMap 则根据元素的 Key 进行排序。
4). 通过toArray()和Arrays.asList(T...)来进行集合和数组之间的互相转换,方便使用响应的方法
8. 监控