前言
前段时间,校招投了golang岗位,但是没什么好的项目往简历上写,于是参考了许多网上资料,做了一个简单的分布式缓存项目。
现在闲下来了,打算整理下。
github项目地址:https://github.com/Jun10ng/Gache
里面还有我整理的一些面试问题,给颗星吧。
typora-root-url: ./
Golang校招面试项目-类redis分布式缓存
实现一个分布式缓存,功能有:LRU淘汰策略,http调用,并发缓存,一致性哈希,分布式节点,防止缓存击穿
实现LRU淘汰策略
LRU的数据结构大致如下,上层是一个map,key是数据对象的key值,而value值则是指向 下层双向链表的节点,在双向链表中,每个节点存储的元素是完整的数据对象,包含key值和value。
- get:存在->将元素所在节点提到最前面,不存在->返回失败
- add:存在->更新,不存在->增加;将元素所在节点提到最前面,判断是否大于
maxSize - removeOldest:删除链表最后方的节点

代码实现
具体代码实现看:https://github.com/Jun10ng/Gache/tree/master/lru
定义了三个数据结构
Value是golang中的接口类型,可以理解为java中的Object类,是一个能“兜底”所有数据结构的数据类型。
entry是一个双向链表存储的数据结构
Cache则是lru核心数据结构,包含一个哈希表和一个双向链表
type Value interface {
//返回占用的内存大小
Len() int
}
type entry struct {
key string
value Value
}
type Cache struct {
//允许使用的最大内存
maxBytes int64
//当前已使用的内存
nbytes int64
ll *list.List
cache map[string] *list.Element
//某条记录被移除时的回调函数,可以是nil
OnEvicted func(key string, value Value)
}
这里说一下OnEvicted成员,这是一个函数对象,他的作用是,在缓存中没有需要的数据对象时,我们需要去原始数据源获取,(redis中没有,就需要去数据库中获取),但是数据源不唯一,有时候是数据库,有时候是磁盘,有时候是表格,他们的获取方式都不相同,所以OnEvicted成员传入的函数,就是自定义的获取方法。
实现单机并发
具体代码实现:https://github.com/Jun10ng/Gache/blob/master/cache.go
上文实现的LRU数据结构并不支持并发,需要加锁来实现并发,所以使用sync.Mutex,在LRU数据结构上封装,使之实现并发功能。
type cache struct {
mu sync.Mutex
lru *lru.Cache
cacheBytes int64
}
cache并没有new方法,因为采用的是延迟初始化 在add方法中,判断c.lru是否为nil,如果等于nil再创建 这种方法称为延迟初始化,一个对象的延迟初始化意味着该对象的 创建将会延迟至第一次使用该对象时。 这个方法在redis中很常见,因为能一定程度上提高性能
func (c *cache) add(key string, value ByteView){
c.mu.Lock()
defer c.mu.Unlock()
if c.lru == nil{
c.lru = lru.New(c.cacheBytes,nil)
}
c.lru.Add(key,value)
}
主体结构
具体代码实现:https://github.com/Jun10ng/Gache/blob/master/gache.go
本质上是再进行一次封装
难道一台机器就只有一个缓存表吗?你打开redis的可视化工具,能看到redis还有16个池呢,所以我们要实现多个缓存表。怎么做?再加一层。试想一下:
//groups 实例集合表
groups = make(map[string]*Group)
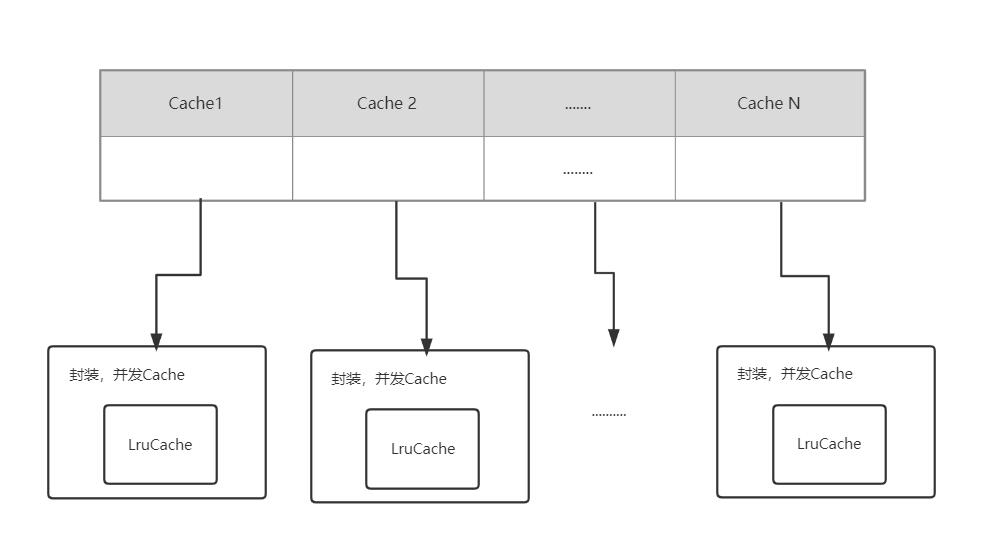
我们要实现的数据结构大致是这样的,是一个存储并发cache的表,这是本项目的核心结构
//这里的group是实例
type Group struct {
name string
getter Getter
mainCache cache
}
http服务调用
具体代码实现:https://github.com/Jun10ng/Gache/blob/master/http.go
当请求URL具有前缀/_Gache/时,则认为该请求为缓存调用。
约定的请求URL为:http://XXX.com/_Gache/<groupname>/<key>
groupname字段为主体结构中groups中的某个元素的name值,由此调用。key字段为元素中的元素的key值,所以最后逻辑为
groups[groupname][key]
一致性哈希
一致性哈希抽象的解释就是一个很大的环,但是在实现的时候,我们总不可能声明一个有个成千链表节点的环吧,何况其中大多节点还是闲置节点,没有实际的作用,所以我们需要在逻辑上去声明哈希环。
代码实现:https://github.com/Jun10ng/Gache/blob/master/consistent/consistentHash.go
数据结构
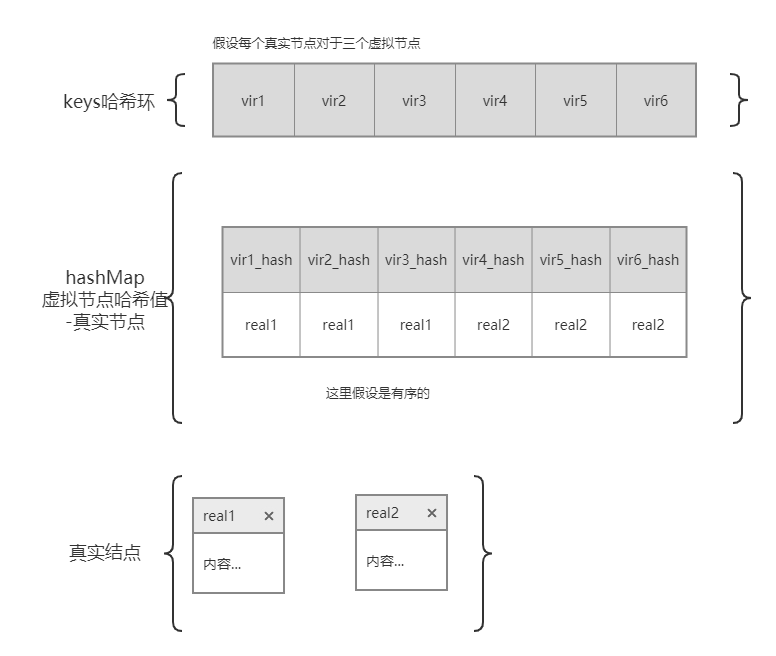
(真实节点就是指机器,虚拟节点相反)
type Map struct {
hash Hash
virMpl int
keys []int
hashMap map[int]string
}
hash是函数变量virMpl是虚拟节点的倍数keys是存放节点哈希值的有序数组- hashMap中存放的是虚拟节点和真实节点的对映,之所以是
[int]string类型,是因为key是虚拟节点的哈希值,value是真实节点
添加真实节点
代码注释写的很详细了,就不多说了。
缺点是,当有一个真实节点添加进来的时候,所有值都要重新计算一遍。这在并发情况下,会造成一定拥塞。因为在重新计算期间,不能进行正确的访问操作。
欢迎提供解决思路。
func (m* Map) Add(keys ...string){
for _,realNodeKey:=range keys{
for i:=0;i<m.virMpl;i++{
/*
keys中的每个真实节点都对映着virMpl个虚拟节点
每个虚拟节点的key(即virNodeKey)为 i+realNodekey
(即一个“不定数”,这里用i值,加上真实节点key
*/
virNodeKey := []byte(strconv.Itoa(i)+realNodeKey)
/*
对虚拟节点做哈希
*/
virNodeHash:= int(m.hash(virNodeKey))
/*
添加进哈希环,所以虚拟节点也存在于哈希环中
*/
m.keys = append(m.keys,virNodeHash)
/*
虚拟节点的hash对映某个真实节点的key
*/
m.hashMap[virNodeHash] = realNodeKey
}
}
sort.Ints(m.keys)
}
访问真实节点
也就是get函数
分为三个步骤
- 计算出虚拟节点的哈希值
virNodeHash - 在
keys数组中找到大于等于virNodeHash的值,返回其下标index,则对应的节点为keys[index] - 通过下标在
hashMap中找到keys[index]的真实节点
自己试着写下get函数,会对整个逻辑更清晰。
分布式节点设计
这一章涉及的东西有点多,在代码中给出了详细的注释,
主要是下面几个文件:
https://github.com/Jun10ng/Gache/blob/master/peer.go
定义了两个抽象接口,用于远程节点的获取
https://github.com/Jun10ng/Gache/blob/master/http.go
实现了peer.go中的两个接口,并定义了新的结构体httpGetter用于获取远程节点缓存数据
https://github.com/Jun10ng/Gache/blob/master/gache.go
集成了一致性哈希表,使用http访问各个节点