一、ORB-SLAM的主要贡献

二、ORB-SLAM的系统架构
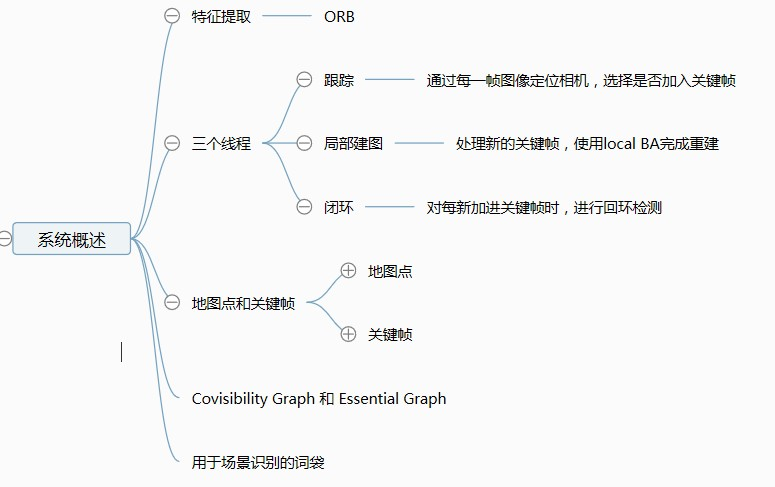
三、ORB-SLAM流程
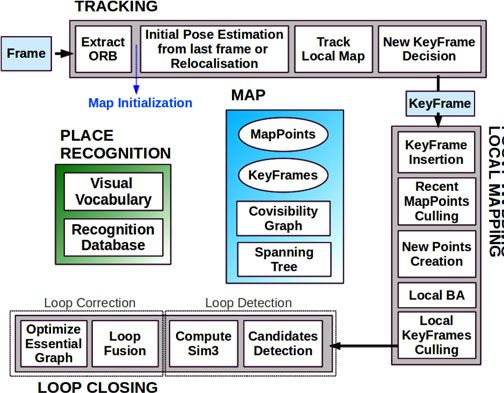
ORB-SLAM 它是由三大块、三个流程同时运行的。第一块是跟踪,第二块是建图,第三块是闭环检测。
Part 0 自动地图初始化
参考自 https://blog.csdn.net/u010128736/article/details/53218140
Part Ⅰ 跟踪
这一部分主要工作是从图像中提取 ORB 特征,根据上一帧进行姿态估计,或者进行通过全局重定位初始化位姿,然后跟踪已经重建的局部地图,优化位姿,再根据一些规则确定新关键帧。
参考自https://blog.csdn.net/u010128736/article/details/53339311
1 Extract ORB
1.1 ORB特征
- 改进的FAST,加入了方向(灰度质心法)和尺度不变性(利用图像金字塔对每一层图像提取FAST角点,这样可以使得相同的物体在不同分辨率(尺度)大小的场景中都能提取到关键点,因此特征点具有尺度不变性)
- BRIEF描述子变得可旋转性
1.2 提取改进点
ORB-SLAM中,对图像进行划分网格,利用四叉树结构保存提取到的特征点,从而使得图像的特征点分布比较均匀。
https://zhuanlan.zhihu.com/p/61738607
2 Map Initialization
分为双目、RGBD,以及单目两种不同的初始化过程。单目的初始化需要注意的较多。这样的处理使得ORB-SLAM的初始化处理具有鲁棒性。
2.1 单目相机初始化
因为单目相机不能获取深度信息,所以单目SLAM得通过初始化确定尺度并且得到一个初始地图。
- 在ORB-SLAM中,初始化提取的特征点设定为一般图像帧的两倍。但是如果提取的特征点不够(<100)或者匹配对不够(<100),都要找新的两帧重新进行初始化。
- 一旦找到了满足要求的前后两帧图像,就利用RANSAC迭代同时计算基础矩阵F(八点法)和单应矩阵H(DLT),并通过计算重投影误差得到两个模型的分数SF和SH。
- 如果分数比例SH/(SH+SF)>0.45(代码中设为0.4),就用单应矩阵恢复相机位姿,否则就认为相机符合对极约束模型,从基础矩阵恢复相机位姿。
- 在对恢复出的位姿进行选择时,会对三角测量的点检查其坐标是否有限、深度是否为正、视差是否够大、重投影误差是否够小。
- 如果选定的H矩阵或者F矩阵最后没能找到一个足够可靠的位姿,或者两帧之间没有足够的视差,抑或在此位姿下好的3D点不够多,那么就判断这两帧的初始化失败。
- 如果初始化成功,便将初始帧(前一帧)设为坐标原点(R为单位阵,t为0向量),这样前一帧到后一帧的旋转矩阵和平移向量就是后一帧的位姿了。
参考自https://zhuanlan.zhihu.com/p/89715373
2.2 RANSAC算法
2.2.1 RANSAC算法作用
ransac算法进行过滤在特征匹配中所遇到的误匹配。RANSAC是“RANdom SAmple Consensus(随机抽样一致)”的缩写。它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。
2.2.2 RANSAC算法基本假设
(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;
(2)“局外点”是不能适应该模型的数据;
(3)除此之外的数据属于噪声。
2.2.3 RANSAC算法步骤
-
RANSAC算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
-
RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
1.首先我们先随机假设一小组局内点为初始值。然后用此局内点拟合一个模型,此模型适应于假设的局内点,所有的未知参数都能从假设的局内点计算得出。
2.用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点,将局内点扩充。
3.如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
4.然后,用所有假设的局内点去重新估计模型,因为此模型仅仅是在初始的假设的局内点估计的,后续有扩充后,需要更新。
5.最后,通过估计局内点与模型的错误率来评估模型。 -
整个这个过程为迭代一次,此过程被重复执行固定的次数,每次产生的模型有两个结局:
1、要么因为局内点太少,还不如上一次的模型,而被舍弃,
2、要么因为比现有的模型更好而被选用。
2.2.4 RANSAC算法优缺点
优点:
- 能鲁棒的估计模型参数
- 能从包含大量局外点的数据集中估计出高精度的参数。
缺点: - 计算参数的迭代次数没有上限;如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果。
- 它要求设置跟问题相关的阀值。
- 只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。
参考自 https://blog.csdn.net/robinhjwy/article/details/79174914
Part Ⅱ 建图
这一部分主要完成局部地图构建。包括对关键帧的插入,验证最近生成的地图点并进行筛选,然后生成新的地图点,使用局部捆集调整(Local BA),最后再对插入的关键帧进行筛选,去除多余的关键帧。
参考自https://blog.csdn.net/u010128736/article/details/53395936
Part Ⅲ 闭环检测
这一部分主要分为两个过程,分别是闭环探测和闭环校正。闭环检测先使用 WOB 进行探测,然后通过 Sim3 算法计算相似变换。闭环校正,主要是闭环融合和 Essential Graph 的图优化。
参考自https://blog.csdn.net/u010128736/article/details/53409199