Part Ⅰ 问题总结
Part Ⅱ 生成式对抗网络
2.1 用途
- 旧图像修复
- 图像超像素
- 人脸生成
- 人脸定制
- 文本生成图片
- 字体变换
- 风格变换
- 帧预测
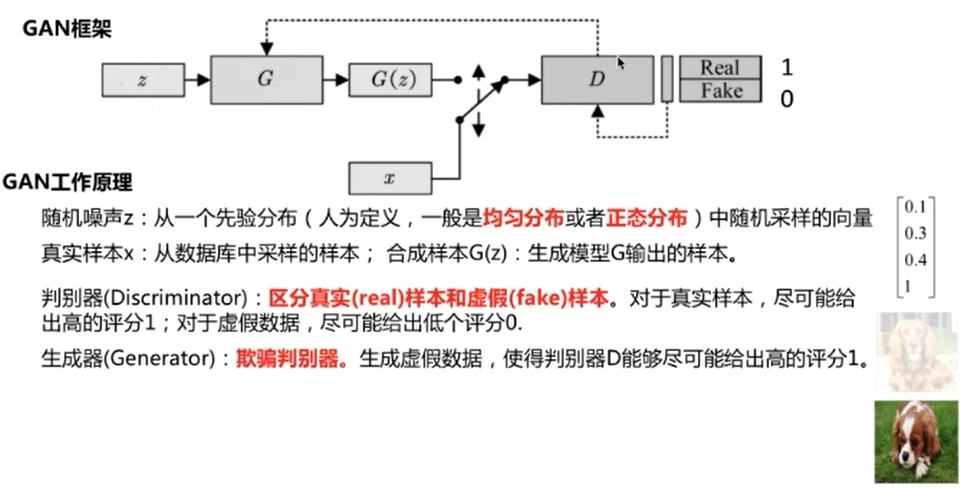
2.2 GAN
生成式对抗网络的目的是训练一个生成模型,生成我们想要的数据。(低维向量-》生成模型-》高维数据(图片、文本、语音))
Part Ⅲ 代码练习
3.1 生成式对抗网络
定义生成器和判别器
z_dim = 32
hidden_dim = 128
# 定义生成器
net_G = nn.Sequential(
nn.Linear(z_dim,hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 2))
# 定义判别器
net_D = nn.Sequential(
nn.Linear(2,hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim,1),
nn.Sigmoid())
# 网络放到 GPU 上
net_G = net_G.to(device)
net_D = net_D.to(device)
# 定义网络的优化器
optimizer_G = torch.optim.Adam(net_G.parameters(),lr=0.0001)
optimizer_D = torch.optim.Adam(net_D.parameters(),lr=0.0001)
开始训练
batch_size = 50
nb_epochs = 1000
loss_D_epoch = []
loss_G_epoch = []
for e in range(nb_epochs):
np.random.shuffle(X)
real_samples = torch.from_numpy(X).type(torch.FloatTensor)
loss_G = 0
loss_D = 0
for t, real_batch in enumerate(real_samples.split(batch_size)):
# 固定生成器G,改进判别器D
# 使用normal_()函数生成一组随机噪声,输入G得到一组样本
z = torch.empty(batch_size,z_dim).normal_().to(device)
fake_batch = net_G(z)
# 将真、假样本分别输入判别器,得到结果
D_scores_on_real = net_D(real_batch.to(device))
D_scores_on_fake = net_D(fake_batch)
# 优化过程中,假样本的score会越来越小,真样本的score会越来越大,下面 loss 的定义刚好符合这一规律,
# 要保证loss越来越小,真样本的score前面要加负号
# 要保证loss越来越小,假样本的score前面是正号(负负得正)
loss = -torch.mean(torch.log(1-D_scores_on_fake) + torch.log(D_scores_on_real))
# 梯度清零
optimizer_D.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer_D.step()
loss_D += loss
# 固定判别器,改进生成器
# 生成一组随机噪声,输入生成器得到一组假样本
z = torch.empty(batch_size,z_dim).normal_().to(device)
fake_batch = net_G(z)
# 假样本输入判别器得到 score
D_scores_on_fake = net_D(fake_batch)
# 我们希望假样本能够骗过生成器,得到较高的分数,下面的 loss 定义也符合这一规律
# 要保证 loss 越来越小,假样本的前面要加负号
loss = -torch.mean(torch.log(D_scores_on_fake))
optimizer_G.zero_grad()
loss.backward()
optimizer_G.step()
loss_G += loss
if e % 50 ==0:
print(f'
Epoch {e} , D loss: {loss_D}, G loss: {loss_G}')
loss_D_epoch.append(loss_D)
loss_G_epoch.append(loss_G)
展示loss的变化情况:
plt.plot(loss_D_epoch)
plt.plot(loss_G_epoch)

可以发现直到训练结束,模型都没有收敛。
利用生成器生成一组假样本,观察是否符合两个半月形状的数据分布:
z = torch.empty(n_samples,z_dim).normal_().to(device)
fake_samples = net_G(z)
fake_data = fake_samples.cpu().data.numpy()
fig, ax = plt.subplots(1, 1, facecolor='#4B6EA9')
all_data = np.concatenate((X,fake_data),axis=0)
Y2 = np.concatenate((np.ones(n_samples),np.zeros(n_samples)))
plot_data(ax, all_data, Y2)
plt.show()

其中,白色的是原来的真实样本,黑色的点是生成器生成的样本。效果并不好!
进行改进:把学习率修改为 0.001,batch_size改大到250,在运行一次
# 定义网络的优化器
optimizer_G = torch.optim.Adam(net_G.parameters(),lr=0.001)
optimizer_D = torch.optim.Adam(net_D.parameters(),lr=0.001)
batch_size = 250
loss_D_epoch = []
loss_G_epoch = []
for e in range(nb_epochs):
np.random.shuffle(X)
real_samples = torch.from_numpy(X).type(torch.FloatTensor)
loss_G = 0
loss_D = 0
for t, real_batch in enumerate(real_samples.split(batch_size)):
# 固定生成器G,改进判别器D
# 使用normal_()函数生成一组随机噪声,输入G得到一组样本
z = torch.empty(batch_size,z_dim).normal_().to(device)
fake_batch = net_G(z)
# 将真、假样本分别输入判别器,得到结果
D_scores_on_real = net_D(real_batch.to(device))
D_scores_on_fake = net_D(fake_batch)
# 优化过程中,假样本的score会越来越小,真样本的score会越来越大,下面 loss 的定义刚好符合这一规律,
# 要保证loss越来越小,真样本的score前面要加负号
# 要保证loss越来越小,假样本的score前面是正号(负负得正)
loss = -torch.mean(torch.log(1-D_scores_on_fake) + torch.log(D_scores_on_real))
# 梯度清零
optimizer_D.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer_D.step()
loss_D += loss
# 固定判别器,改进生成器
# 生成一组随机噪声,输入生成器得到一组假样本
z = torch.empty(batch_size,z_dim).normal_().to(device)
fake_batch = net_G(z)
# 假样本输入判别器得到 score
D_scores_on_fake = net_D(fake_batch)
# 我们希望假样本能够骗过生成器,得到较高的分数,下面的 loss 定义也符合这一规律
# 要保证 loss 越来越小,假样本的前面要加负号
loss = -torch.mean(torch.log(D_scores_on_fake))
optimizer_G.zero_grad()
loss.backward()
optimizer_G.step()
loss_G += loss
if e % 50 ==0:
print(f'
Epoch {e} , D loss: {loss_D}, G loss: {loss_G}')
loss_D_epoch.append(loss_D)
loss_G_epoch.append(loss_G)
展示结果
z = torch.empty(n_samples,z_dim).normal_().to(device)
fake_samples = net_G(z)
fake_data = fake_samples.cpu().data.numpy()
fig, ax = plt.subplots(1, 1, facecolor='#4B6EA9')
all_data = np.concatenate((X,fake_data),axis=0)
Y2 = np.concatenate((np.ones(n_samples),np.zeros(n_samples)))
plot_data(ax, all_data, Y2)
plt.show()

随着batch size的增大,loss的降低,效果明显改善
下面生成更多的样本观察一下
z = torch.empty(10*n_samples,z_dim).normal_().to(device)
fake_samples = net_G(z)
fake_data = fake_samples.cpu().data.numpy()
fig, ax = plt.subplots(1, 1, facecolor='#4B6EA9')
all_data = np.concatenate((X,fake_data),axis=0)
Y2 = np.concatenate((np.ones(n_samples),np.zeros(10*n_samples)))
plot_data(ax, all_data, Y2)
plt.show();

3.2 CGAN
首先下载数据集
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
# 基本参数
z_dim = 100
batch_size = 128
learning_rate = 0.0002
total_epochs = 30
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载MNIST数据集
dataloader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])
), batch_size, shuffle=False, drop_last=True)
实现CGAN,分别是生成器和判别器的网络结构。
class Discriminator(nn.Module):
'''全连接判别器,用于1x28x28的MNIST数据,输出是数据和类别'''
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(28*28+10, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x, c):
x = x.view(x.size(0), -1)
validity = self.model(torch.cat([x, c], -1))
return validity
class Generator(nn.Module):
'''全连接生成器,用于1x28x28的MNIST数据,输入是噪声和类别'''
def __init__(self, z_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(z_dim+10, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(in_features=512, out_features=28*28),
nn.Tanh()
)
def forward(self, z, c):
x = self.model(torch.cat([z, c], dim=1))
x = x.view(-1, 1, 28, 28)
return x
定义相关的模型
# 初始化构建判别器和生成器
discriminator = Discriminator().to(device)
generator = Generator(z_dim=z_dim).to(device)
# 初始化二值交叉熵损失
bce = torch.nn.BCELoss().to(device)
ones = torch.ones(batch_size).to(device)
zeros = torch.zeros(batch_size).to(device)
# 初始化优化器,使用Adam优化器
g_optimizer = optim.Adam(generator.parameters(), lr=learning_rate)
d_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate)
开始训练
# 开始训练,一共训练total_epochs
for epoch in range(total_epochs):
# torch.nn.Module.train() 指的是模型启用 BatchNormalization 和 Dropout
# torch.nn.Module.eval() 指的是模型不启用 BatchNormalization 和 Dropout
# 因此,train()一般在训练时用到, eval() 一般在测试时用到
generator = generator.train()
# 训练一个epoch
for i, data in enumerate(dataloader):
# 加载真实数据
real_images, real_labels = data
real_images = real_images.to(device)
# 把对应的标签转化成 one-hot 类型
tmp = torch.FloatTensor(real_labels.size(0), 10).zero_()
real_labels = tmp.scatter_(dim=1, index=torch.LongTensor(real_labels.view(-1, 1)), value=1)
real_labels = real_labels.to(device)
# 生成数据
# 用正态分布中采样batch_size个随机噪声
z = torch.randn([batch_size, z_dim]).to(device)
# 生成 batch_size 个 ont-hot 标签
c = torch.FloatTensor(batch_size, 10).zero_()
c = c.scatter_(dim=1, index=torch.LongTensor(np.random.choice(10, batch_size).reshape([batch_size, 1])), value=1)
c = c.to(device)
# 生成数据
fake_images = generator(z,c)
# 计算判别器损失,并优化判别器
real_loss = bce(discriminator(real_images, real_labels), ones)
fake_loss = bce(discriminator(fake_images.detach(), c), zeros)
d_loss = real_loss + fake_loss
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# 计算生成器损失,并优化生成器
g_loss = bce(discriminator(fake_images, c), ones)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
# 输出损失
print("[Epoch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, total_epochs, d_loss.item(), g_loss.item()))
下面我们用随机噪声生成一组图像,看看CGAN的效果
#用于生成效果图
# 生成100个随机噪声向量
fixed_z = torch.randn([100, z_dim]).to(device)
# 生成100个one_hot向量,每类10个
fixed_c = torch.FloatTensor(100, 10).zero_()
fixed_c = fixed_c.scatter_(dim=1, index=torch.LongTensor(np.array(np.arange(0, 10).tolist()*10).reshape([100, 1])), value=1)
fixed_c = fixed_c.to(device)
generator = generator.eval()
fixed_fake_images = generator(fixed_z, fixed_c)
plt.figure(figsize=(8, 8))
for j in range(10):
for i in range(10):
img = fixed_fake_images[j*10+i, 0, :, :].detach().cpu().numpy()
img = img.reshape([28, 28])
plt.subplot(10, 10, j*10+i+1)
plt.imshow(img, 'gray')

3.3 DCGAN
判别器 和 生成器 的网络结构
class D_dcgan(nn.Module):
'''滑动卷积判别器'''
def __init__(self):
super(D_dcgan, self).__init__()
self.conv = nn.Sequential(
# 第一个滑动卷积层,不使用BN,LRelu激活函数
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
# 第二个滑动卷积层,包含BN,LRelu激活函数
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2, inplace=True),
# 第三个滑动卷积层,包含BN,LRelu激活函数
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
# 第四个滑动卷积层,包含BN,LRelu激活函数
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=4, stride=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True)
)
# 全连接层+Sigmoid激活函数
self.linear = nn.Sequential(nn.Linear(in_features=128, out_features=1), nn.Sigmoid())
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
validity = self.linear(x)
return validity
class G_dcgan(nn.Module):
'''反滑动卷积生成器'''
def __init__(self, z_dim):
super(G_dcgan, self).__init__()
self.z_dim = z_dim
# 第一层:把输入线性变换成256x4x4的矩阵,并在这个基础上做反卷机操作
self.linear = nn.Linear(self.z_dim, 4*4*256)
self.model = nn.Sequential(
# 第二层:bn+relu
nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=3, stride=2, padding=0),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# 第三层:bn+relu
nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# 第四层:不使用BN,使用tanh激活函数
nn.ConvTranspose2d(in_channels=64, out_channels=1, kernel_size=4, stride=2, padding=2),
nn.Tanh()
)
def forward(self, z):
# 把随机噪声经过线性变换,resize成256x4x4的大小
x = self.linear(z)
x = x.view([x.size(0), 256, 4, 4])
# 生成图片
x = self.model(x)
return x
定义相关的模型
# 构建判别器和生成器
d_dcgan = D_dcgan().to(device)
g_dcgan = G_dcgan(z_dim=z_dim).to(device)
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm2d') != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
# 使用均值为0,方差为0.02的正态分布初始化神经网络
d_dcgan.apply(weights_init_normal)
g_dcgan.apply(weights_init_normal)
# 初始化优化器,使用Adam优化器
g_dcgan_optim = optim.Adam(g_dcgan.parameters(), lr=learning_rate)
d_dcgan_optim = optim.Adam(d_dcgan.parameters(), lr=learning_rate)
# 加载MNIST数据集,和之前不同的是,DCGAN输入的图像被 resize 成 32*32 像素
dcgan_dataloader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([transforms.Resize(32), transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))])
), batch_size, shuffle=True, drop_last=True)
开始训练模型
# 开始训练,一共训练 total_epochs
for e in range(total_epochs):
# 给generator启用 BatchNormalization
g_dcgan = g_dcgan.train()
# 训练一个epoch
for i, data in enumerate(dcgan_dataloader):
# 加载真实数据,不加载标签
real_images, _ = data
real_images = real_images.to(device)
# 用正态分布中采样batch_size个噪声,然后生成对应的图片
z = torch.randn([batch_size, z_dim]).to(device)
fake_images = g_dcgan(z)
# 计算判别器损失,并优化判别器
real_loss = bce(d_dcgan(real_images), ones)
fake_loss = bce(d_dcgan(fake_images.detach()), zeros)
d_loss = real_loss + fake_loss
d_dcgan_optim.zero_grad()
d_loss.backward()
d_dcgan_optim.step()
# 计算生成器损失,并优化生成器
g_loss = bce(d_dcgan(fake_images), ones)
g_dcgan_optim.zero_grad()
g_loss.backward()
g_dcgan_optim.step()
# 输出损失
print ("[Epoch %d/%d] [D loss: %f] [G loss: %f]" % (e, total_epochs, d_loss.item(), g_loss.item()))
用一组随机噪声输出图像,看看DCGAN的效果
#用于生成效果图
# 生成100个随机噪声向量
fixed_z = torch.randn([100, z_dim]).to(device)
g_dcgan = g_dcgan.eval()
fixed_fake_images = g_dcgan(fixed_z)
plt.figure(figsize=(8, 8))
for j in range(10):
for i in range(10):
img = fixed_fake_images[j*10+i, 0, :, :].detach().cpu().numpy()
img = img.reshape([32, 32])
plt.subplot(10, 10, j*10+i+1)
plt.imshow(img, 'gray')
