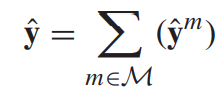1 摘要
为了更好的估计微视频所在的场所,这篇论文提出了一个neural multimodal cooperative learning model。
- 在correlation中区分consistent部分和complementary部分
2 引入
对于微视频来说,识别特定的地理信息是非常难的。但是,识别venue category却是有迹可循。
但是多模态融合目前的方法限于两个问题:
* 只融合不同模态中的consistent部分,忽视其他含有很多信息特征的其他部分。
* 或者是,同时关注了consistent部分和complementary部分,却无法在correlation中区分consistent部分与complementary部分。
To solve problem 1:
关注了the cooperative relation,包括consisten部分和complementary部分。
consistent components--->the same information appearing in more than one modality in different forms
complementary components--->the exclusive information appearing only in one modality
To solve problem 2:
提出了deep multimodal cooperative learning approach,能够清晰地区分不同模态之间的correlation。
3 数据收集与处理
3.1 数据收集
利用API从Vine平台收集了24000个包含Foursquare信息的微视频。
删除重复的场所ID之后,我们通过API抓取每个场所ID中的所有视频,进一步扩展了视频集,得到了276264个视频,分布于442个Foursquare场所ID。
几个类别包含有限数量的微型视频来训练鲁棒的分类器。因此,把少于50个微视频删除。
最终,我们在188个Foursquare场地类别中获得了270,145个微视频。
3.2 数据处理
- 视觉特征
* 利用OpenCV,从每个微视频中提取关键帧
* 利用ResNet从每个关键帧中提取特征(We applied the ResNet model to extract the visual features through the publicly available Caffe)
* 每个微视频得到一个2048维向量 - 音频特征
* FFmpeg将音轨与每个微型视频分开
* 将磁道转换为统一格式:22,050Hz,16位,带脉冲编码调制信号的单通道,并通过librosa执行了具有46ms窗口和50%重叠的频谱图。
* 采用theano通过DAE提取音频特征(DAE在外部120,000个微视频集上进行了预训练,包含三个隐藏层,每个层上有500、400和300个神经元。)
* 最后得到200维的向量 - 文本特征
* 应用了Sentence2Vector工具为每个微视频提取了一个文本集,生成100维向量。
3.3 数据补充
利用了低秩矩阵分解对数据进行补充。
4 neural multimodal cooperative learning model网络结构
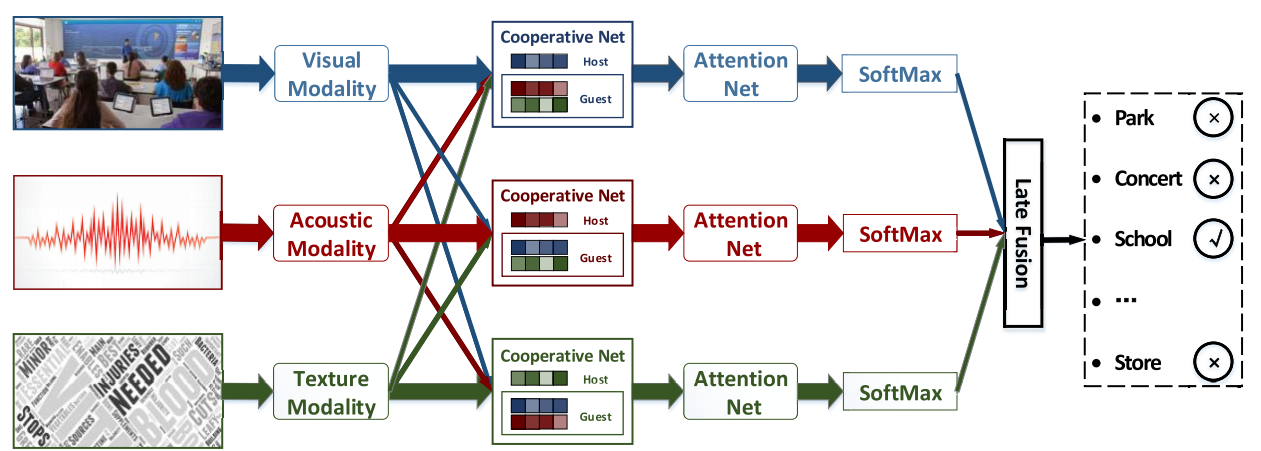
4.1 Cooperative netwworks(以视觉作为host为例解释)
- assign each dimension of features with a relation score
- divide the features into the consistent part and the complementary part
4.1.1 assign relation score
- 将音频特征向量和文本特征向量融合起来
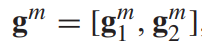
- 计算relation score
higher score--->consistent
lower score--->complementary
计算host score vector,利用一个单隐层和一个softmax层,其中权重参数W是可学习的,之后会进行训练。
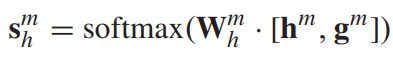
类似的,计算guest score vector。
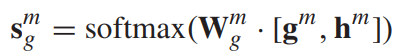
4.1.2 divide consistent and complementary
- 设定一个可训练的阈值,利用这个阈值进行区分consistent和complementary
由上一个步骤得到的两个score(host score vector、guest score vector),分别进行判断:
大于阈值,计入consistent vector

小于阈值,计入complementary vector
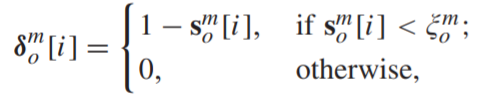
- 由于原始函数不是连续的,因此我们引入了sigmoid函数以使其具有可区分性
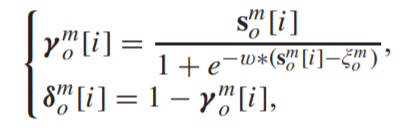
- 利用得到的四个correlation weight vector,与最初得到的host vector和guest vector进行张量积

最后得到两个complementary vector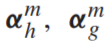
和两个consistent vector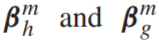
- 学习一个增强的consistent vector
为了充分利用consistent vectors对之间的相关性,将这些向量连接起来,并将其馈入神经网络以学习增强的consistent vector
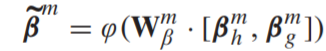
- 最后得到一个已经将consistent和complementary分开的向量,其中α代表complementary,β代表consistent
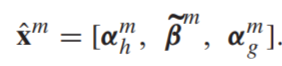
4.2 attention net
4.2.1 attention score
利用了自注意力机制,对产生的feature分配权重
- 构造了一个可训练的memory matrix来存储它们的attention score。
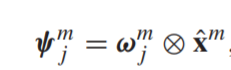
这个memory matrix的第i行,第j列代表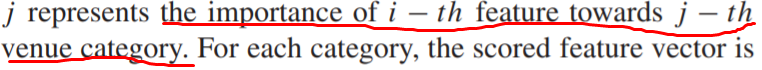
得到的结果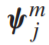 为对应第j个场景,该特征向量所得到的分数。
为对应第j个场景,该特征向量所得到的分数。 - 使用一个全连接层来产生区分性表示(discrimination representation)
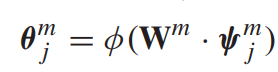
4.2.2 multimodal estimation
- 利用一个softmax层,估计每一个discrimination representation的概率分布
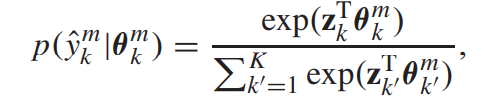
- 然后,会得到一个probabilistic label vector
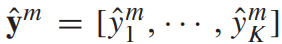
- 将每个模态下得到的probabilistic label vector进行相加,得到最后的结果