本次作业涉及到了检索这一功能,以下是我对本次作业做出的尝试与解析:
如图,文件中Exercises.txt文件是题目生成处,而Answers.txt则为答案生成处。Grade.txt为最终检索后答案生成处:

其中生成题目的代码部分为下图:
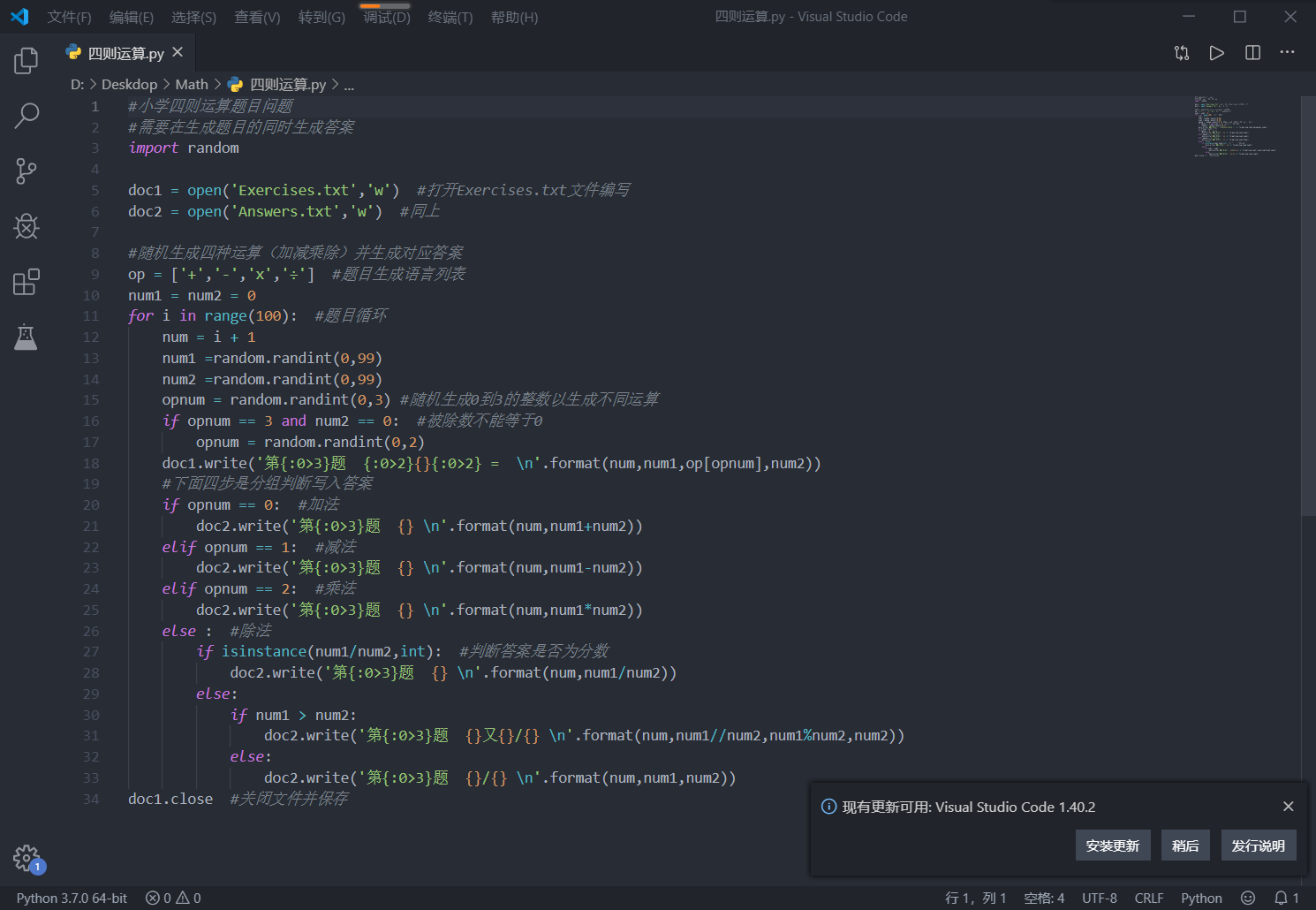
其代码为:
#小学四则运算题目问题
#需要在生成题目的同时生成答案
import random
doc1 = open('Exercises.txt','w') #打开Exercises.txt文件编写
doc2 = open('Answers.txt','w') #同上
#随机生成四种运算(加减乘除)并生成对应答案
op = ['+','-','x','÷'] #题目生成语言列表
num1 = num2 = 0
for i in range(100): #题目循环
num = i + 1
num1 =random.randint(0,99)
num2 =random.randint(0,99)
opnum = random.randint(0,3) #随机生成0到3的整数以生成不同运算
if opnum == 3 and num2 == 0: #被除数不能等于0
opnum = random.randint(0,2)
doc1.write('第{:0>3}题 {:0>2}{}{:0>2} =
'.format(num,num1,op[opnum],num2))
#下面四步是分组判断写入答案
if opnum == 0: #加法
doc2.write('第{:0>3}题 {}
'.format(num,num1+num2))
elif opnum == 1: #减法
doc2.write('第{:0>3}题 {}
'.format(num,num1-num2))
elif opnum == 2: #乘法
doc2.write('第{:0>3}题 {}
'.format(num,num1*num2))
else : #除法
if isinstance(num1/num2,int): #判断答案是否为分数
doc2.write('第{:0>3}题 {}
'.format(num,num1/num2))
else:
if num1 > num2:
doc2.write('第{:0>3}题 {}又{}/{}
'.format(num,num1//num2,num1%num2,num2))
else:
doc2.write('第{:0>3}题 {}/{}
'.format(num,num1,num2))
doc1.close #关闭文件并保存
改代码可正常工作,输出结果会在对应txt文件中展现,如下:
Exercises.txt文件中在运行一次后:

Answers.txt文件中在运行一次后:

以上就是出题部分代码.
在检索部分,我遇到了困难,做出了如下的第一次尝试:
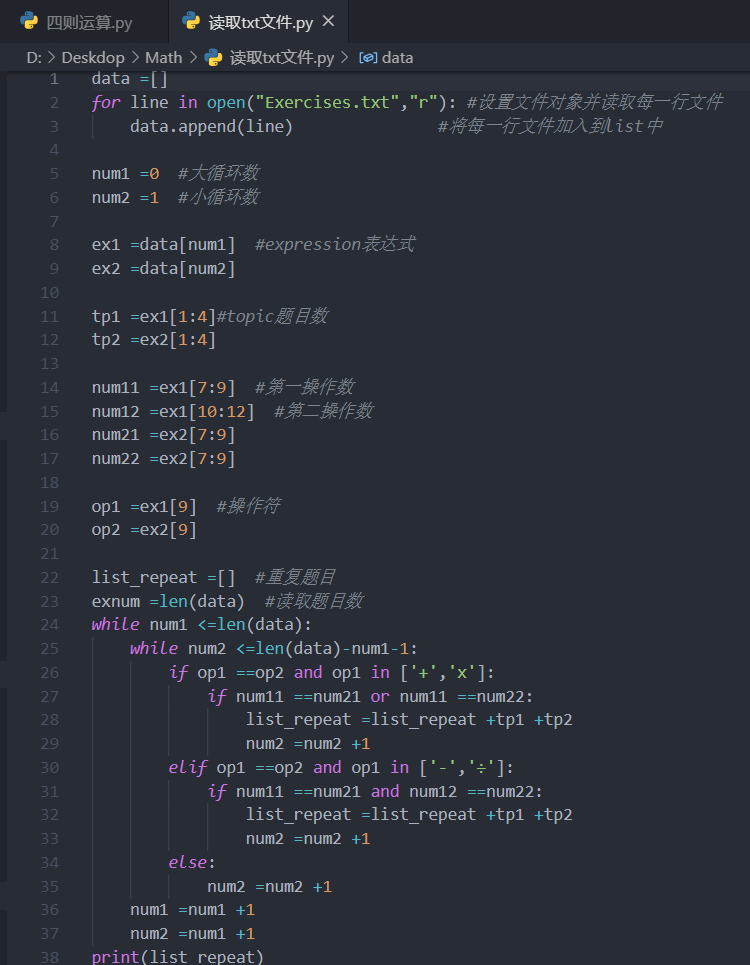
其代码为:
data =[]
for line in open("Exercises.txt","r"): #设置文件对象并读取每一行文件
data.append(line) #将每一行文件加入到list中
num1 =0 #大循环数
num2 =1 #小循环数
ex1 =data[num1] #expression表达式
ex2 =data[num2]
tp1 =ex1[1:4]#topic题目数
tp2 =ex2[1:4]
num11 =ex1[7:9] #第一操作数
num12 =ex1[10:12] #第二操作数
num21 =ex2[7:9]
num22 =ex2[7:9]
op1 =ex1[9] #操作符
op2 =ex2[9]
list_repeat =[] #重复题目
exnum =len(data) #读取题目数
while num1 <=len(data):
while num2 <=len(data)-num1-1:
if op1 ==op2 and op1 in ['+','x']:
if num11 ==num21 or num11 ==num22:
list_repeat =list_repeat +tp1 +tp2
num2 =num2 +1
elif op1 ==op2 and op1 in ['-','÷']:
if num11 ==num21 and num12 ==num22:
list_repeat =list_repeat +tp1 +tp2
num2 =num2 +1
else:
num2 =num2 +1
num1 =num1 +1
num2 =num1 +1
print(list_repeat)
可见代码中计算量极其庞大,如果题目数为10000时需要计算最低100000000次,可见这种方式是极度不科学的(在测试时我的电脑都一直在哀嚎),由此我继续进行了第二次尝试.
不同于第一次的是,第二次我先缩小了范围,在答案中先进行第一次缩小,找到答案相同的题目时再进行检索,这种情况下在题目很多的时候就可以减小电脑的工作量从而减少计算时间.
第二次尝试的代码如下:
#读取txt文件2
data_answer =[] #Answers.txt文件语句
data_Exercises =[] #Exercises.txt文件语句
for line in open("Answers.txt","r"): #设置文件对象并读取每一行文件
data_answer.append(line) #将每一行文件加入到list中
for line in open("Exercises.txt","r"): #同上
data_Exercises.append(line)
#生成一个只存有答案的列表
loopnum1 =0 #循环数
answers ="" #答案字符串
while loopnum1 <= len(data_answer) -1:
answer =data_answer[loopnum1] #答案语句
awnum =answer[7:-2] #答案数据
answers = answers +awnum +" "
loopnum1 =loopnum1 +1
awlist =answers.split(sep=" ") #答案列表
del awlist[-1] #删除最后一个空字符串
#索引相同答案的列表
loopnum2 =0 #循环数
repeat =""
while loopnum2 <= len(data_answer) -1:
item =awlist[loopnum2] #每个元素
itnum =str(awlist.count(item)) #每个元素重复个数
repeat =repeat +itnum +" "
loopnum2 =loopnum2 +1
rep =repeat.split(sep=" ") #所有元素出现次数的字符串
del rep[-1] #删除最后一个空字符串
#生成重复题目的题号
repnum =rep.count('2') #重复题目总数
loopnum3 =0
aimnum =""
repaimnum = 0
while loopnum3 <=repnum -1:
repaimnum =rep.index('2') +1 +loopnum3 #题号
aimnum =aimnum +str(repaimnum) +" "
rep.remove('2')
loopnum3 =loopnum3 +1
print("一共有{}道题目错误,他们的题号是{}".format(repnum,aimnum))
# 文本进度条,纯属好玩才加的
import time
scale = 50
print("检查重复题目开始".center(scale//2,"_"))
start = time.perf_counter()
for i in range(scale + 1):
a = "■" * i
b = "□" * (scale - i)
c = (i / scale) * 100
dur = time.perf_counter() - start
print("
{:3^.0f}%[{}{}]{:.1f}秒".format(c,a,b,dur),end="")
# └百分数 └进度条 └秒数
time.sleep(0.1)
print("
"+"检查结束".center((scale +8)//2,"_"))
除去纯属为了好玩的进度条,代码一共有42行,且尚未完成,以下是目前运行时的结果:

2019.11.28
经过一天的编辑和测试,我完成了检索这一章节,具体情况如下:
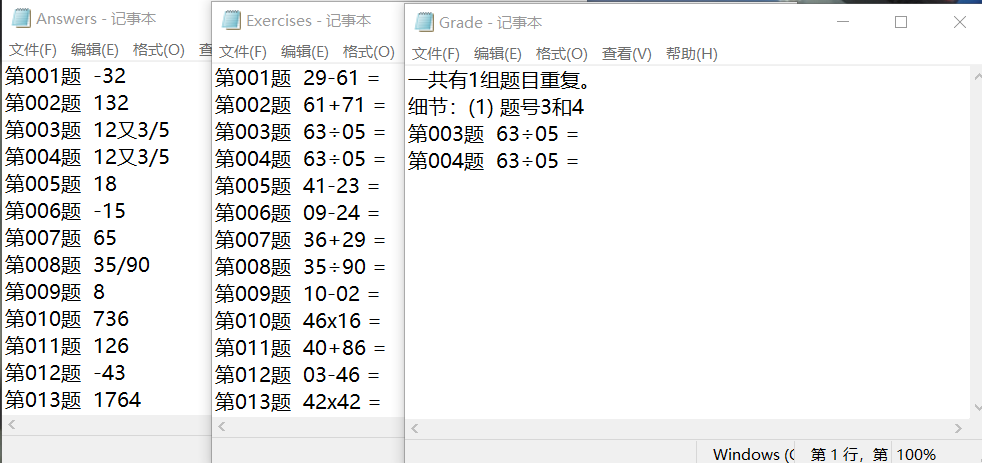
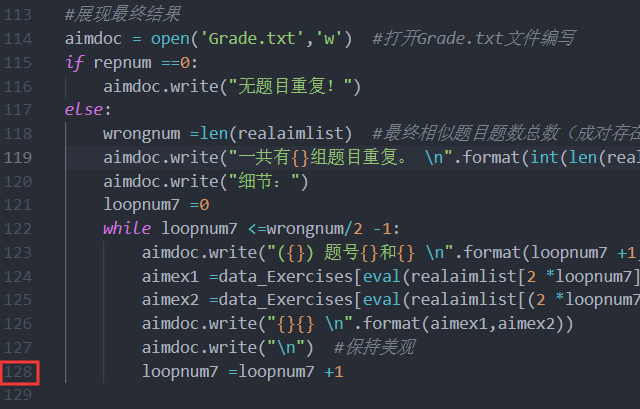
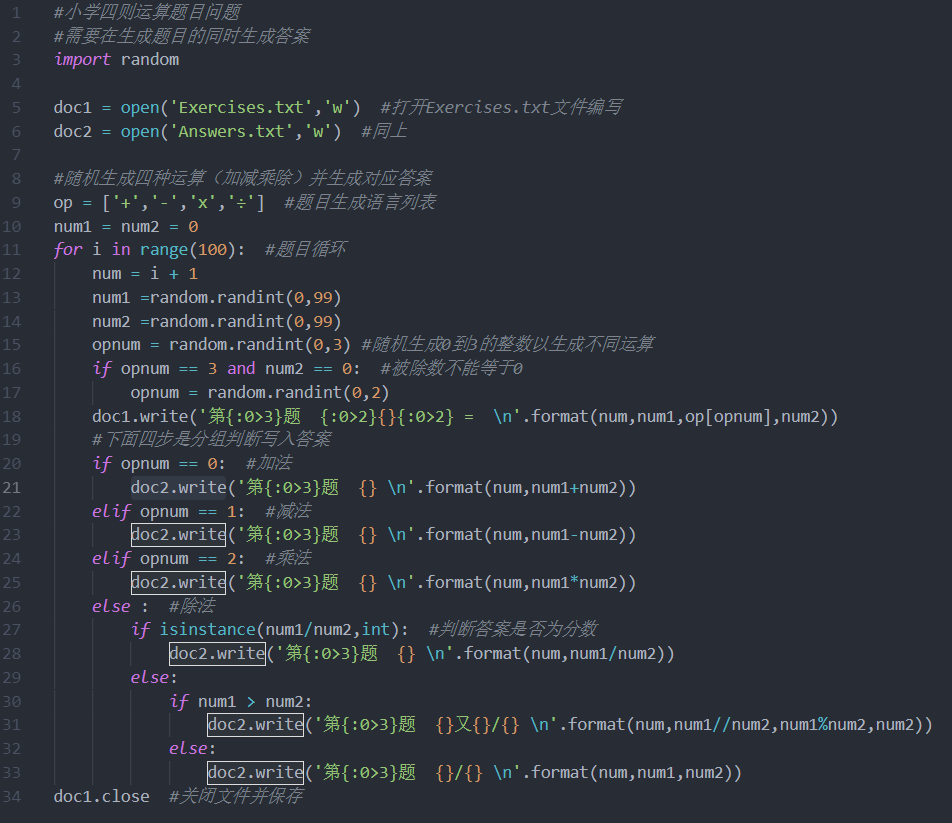
至此这个162行代码横空出世!
其中第一部分代码如下:
#小学四则运算题目问题
#需要在生成题目的同时生成答案
#20192428魏来,可以参考禁止抄袭i
import random
doc1 = open('Exercises.txt','w') #打开Exercises.txt文件编写
doc2 = open('Answers.txt','w') #同上
#随机生成四种运算(加减乘除)并生成对应答案
op = ['+','-','x','÷'] #题目生成语言列表
num1 = num2 = 0
for i in range(100): #题目循环
num = i + 1
num1 =random.randint(0,99)
num2 =random.randint(0,99)
opnum = random.randint(0,3) #随机生成0到3的整数以生成不同运算
if opnum == 3 and num2 == 0: #被除数不能等于0
opnum = random.randint(0,2)
doc1.write('第{:0>3}题 {:0>2}{}{:0>2} =
'.format(num,num1,op[opnum],num2))
#下面四步是分组判断写入答案
if opnum == 0: #加法
doc2.write('第{:0>3}题 {}
'.format(num,num1+num2))
elif opnum == 1: #减法
doc2.write('第{:0>3}题 {}
'.format(num,num1-num2))
elif opnum == 2: #乘法
doc2.write('第{:0>3}题 {}
'.format(num,num1*num2))
else : #除法
if isinstance(num1/num2,int): #判断答案是否为分数
doc2.write('第{:0>3}题 {}
'.format(num,num1/num2))
else:
if num1 > num2:
doc2.write('第{:0>3}题 {}又{}/{}
'.format(num,num1//num2,num1%num2,num2))
else:
doc2.write('第{:0>3}题 {}/{}
'.format(num,num1,num2))
doc1.close #关闭文件并保存
第二部分代码如下:
#读取txt文件2
#20192428魏来,可以参考禁止抄袭
data_answer =[] #Answers.txt文件语句
data_Exercises =[] #Exercises.txt文件语句
for line in open("Answers.txt","r"): #设置文件对象并读取每一行文件
data_answer.append(line) #将每一行文件加入到list中
for line in open("Exercises.txt","r"): #同上
data_Exercises.append(line)
#生成一个只存有答案的列表
loopnum1 =0 #循环数
answers ="" #答案字符串
while loopnum1 <= len(data_answer) -1:
answer =data_answer[loopnum1] #答案语句
awnum =answer[7:-2] #答案数据
answers = answers +awnum +" "
loopnum1 =loopnum1 +1
awlist =answers.split(sep=" ") #答案列表
del awlist[-1] #删除最后一个空字符串
#索引相同答案的列表
loopnum2 =0 #循环数
repeat =""
while loopnum2 <= len(data_answer) -1:
item =awlist[loopnum2] #每个元素
itnum =str(awlist.count(item)) #每个元素重复个数
repeat =repeat +itnum +" "
loopnum2 =loopnum2 +1
rep =repeat.split(sep=" ") #所有元素出现次数的字符串
del rep[-1] #删除最后一个空字符串
#生成重复题目的题号
repnum =rep.count('2') #重复题目总数
loopnum3 =0
aimnum =""
repaimnum = 0
while loopnum3 <=repnum -1:
repaimnum =rep.index('2') +1 +loopnum3 #题号
aimnum =aimnum +str(repaimnum) +" "
rep.remove('2')
loopnum3 =loopnum3 +1
#进行判断:题目是否有可以重复题目
if repnum ==0:
print("无题目重复")
else:
print("一共有{}道题目重复,他们的题号是{}".format(repnum,aimnum))
# 文本进度条,纯属好玩才加的
import time
scale = 50
print("检查重复题目开始".center(scale//2,"_"))
start = time.perf_counter()
for i in range(scale + 1):
a = "■" * i
b = "□" * (scale - i)
c = (i / scale) * 100
dur = time.perf_counter() - start
print("
{:3^.0f}%[{}{}]{:.1f}秒".format(c,a,b,dur),end="")
# └百分数 └进度条 └秒数
time.sleep(0.1)
print("
"+"检查结束".center((scale +8)//2,"_"))
#展示可疑题目
aimlist =aimnum.split(sep=" ") #可疑题目题号列表
loopnum4 =0 #循环数
while loopnum4 <=len(aimlist) -2:
aim =eval(aimlist[loopnum4]) -1
print('可疑题目为{}'.format(data_Exercises[aim]))
loopnum4 =loopnum4 +1
#进行准备:获取题目第一个操作数、操作符、第二个操作数并加以判断
loopnum5 =0 #检索循环数————第一操作数
loopnum6 =1 #检索循环数————第二操作数
exnum =len(aimlist) #读取可疑题目数数量
realaim =''
#进行判断
while loopnum5 <=exnum -1:
while loopnum6 <=exnum -2:
num1 =eval(aimlist[loopnum5]) -1 #第一表达式对应题号
num2 =eval(aimlist[loopnum6]) -1 #第二表达式对应题号
ex1 =data_Exercises[num1] #expression表达式 1
ex2 =data_Exercises[num2] #expression表达式 2
num11 =ex1[7:9] #第一表达式第一操作数
num12 =ex1[10:12] #第二表达式第二操作数
num21 =ex2[7:9] #第二表达式第一操作数
num22 =ex2[10:12] #第二表达式第二操作数
op1 =ex1[9] #第一表达式操作符
op2 =ex2[9] #第二表达式操作符
if op1 != op2 :
print('第{}题和第{}题不重复'.format(aimlist[loopnum5],aimlist[loopnum6]))
elif op1 == op2 and op1 in ['-','÷']:
if num11 ==num21 and num12 ==num22:
realaim =realaim +aimlist[loopnum5] +' ' +aimlist[loopnum6] +' '
print('第{}题和第{}题重复'.format(aimlist[loopnum5],aimlist[loopnum6]))
elif op1 == op2 and op1 in ['+','x']:
if num11 ==num22 and num12 ==num21:
realaim =realaim +aimlist[loopnum5] +' ' +aimlist[loopnum6] +' '
print('第{}题和第{}题重复'.format(aimlist[loopnum5],aimlist[loopnum6]))
elif num11 ==num21 and num12 ==num22:
realaim =realaim +aimlist[loopnum5] +' ' +aimlist[loopnum6] +' '
print('第{}题和第{}题重复'.format(aimlist[loopnum5],aimlist[loopnum6]))
else:
print('第{}题和第{}题不重复'.format(aimlist[loopnum5],aimlist[loopnum6]))
else:
print('程序错误。')
loopnum6 =loopnum6 +1
loopnum5 = loopnum5 +1
loopnum6 = loopnum5 +1
realaimlist =realaim.split(sep=" ")
del realaimlist[-1] #删除最后一个空字符串
print(aimlist)
#展现最终结果
aimdoc = open('Grade.txt','w') #打开Grade.txt文件编写
if repnum ==0:
aimdoc.write("无题目重复!")
else:
wrongnum =len(realaimlist) #最终相似题目题数总数(成对存在)
aimdoc.write("一共有{}组题目重复。
".format(int(len(realaimlist)/2)))
aimdoc.write("细节:")
loopnum7 =0
while loopnum7 <=wrongnum/2 -1:
aimdoc.write("({}) 题号{}和{}
".format(loopnum7 +1,realaimlist[2 *loopnum7],realaimlist[(2 *loopnum7) +1]))
aimex1 =data_Exercises[eval(realaimlist[2 *loopnum7]) -1]
aimex2 =data_Exercises[eval(realaimlist[(2 *loopnum7) +1]) -1]
aimdoc.write("{}{}
".format(aimex1,aimex2))
aimdoc.write("
") #保持美观
loopnum7 =loopnum7 +1
下面讲讲我的方法:
- 首先,缩小范围:使用倒推,答案相同才有可能重复,故第二块代码的第一步是通过答案缩小范围,找到所有答案相同的题目,放入一个列表中再进行下一步判断。
- 其次,判断所有相同答案的式子,符号为 + 和 x 的归为一组, - 和 ÷ 放在一组。
- 第三,加乘组判断两个式子操作数相同需要进行两次比较,即12+31和31+12是相同的式子,而12+31和12+31也是相同的式子。而剪除组就不一样了,12-6和6-12不是一组,所以只需要比较一个操作数即可。
- 最终,整理,得到答案。