原始的解决方案
go自带的map不是goroutine安全的,为解决这个问题,最简单的方法是在map上挂把锁,每个goroutine操作map前上锁,操作完成解锁。在数据量很低,或并发度很低的情况下,这个把大锁导致的性能问题不足以放在心上,但是当数据量很大,导致map的操作非常耗时,或并发量很大,大量goroutine都争抢那把锁时,性能问题就值得关注了
解决办法
因此,为了提高上述场景的性能,应该减小锁的粒度,降低同一时间访问锁的goroutine的数量。
分片思想刚好就能同时处理好上述两个要求,分片需要:
- 将原来存储在一个数据结构的全部数据,通过一定的方法尽量均匀的分配到多个子数据结构片中
- 将原来控制数据结构的一个锁,增加到子数据结构个数的锁,每个锁只负责控制自己所在片的数据结构
经过分片处理后有以下好处:
- 锁的控制范围就由原来的整个大数据结构,缩小到自己所在的片所在的子数据结构,降低了锁的粒度
- 由于数据被分散到多个片中,每个锁只需管理自己的片,因此和原来相比,锁同时被多个执行流访问到的概率也相应降低
通过对数据进行分片来提高并发访问的性能,是一种思想,运用此思想的其他例子还有数据库的分、分库、负载均衡等
代码
结构的定义
type shard struct{
mapItem map[string]interface{}
rwLock sync.RWMutex
}
type ShardMap []*shard每个分片的底层数据结构是map,每个片有自己的rwmutex保障并行安全
ShardMap结构是切片,底层为内存连续的数组,可更好的利用缓存提高性能
创建
const sliceCount = 256 //必须为2的N次方
func NewShardMap() ShardMap{
shards := make([]*shard, sliceCount, sliceCount)
for i := 0; i < sliceCount; i++{
shards[i] = &shard{
mapItem:make(map[string]interface{}),
}
}
return shards
}创建切片,并初始化每一个分片
Get、Set、Del
func (shardmap *ShardMap)SetVal(key string, val interface{}) {
shard := shardmap.getShard(key)
shard.rwLock.Lock()
defer shard.rwLock.Unlock()
shard.mapItem[key] = val
}
func (shardmap *ShardMap)GetVal(key string) (interface{}, bool){
shard := shardmap.getShard(key)
shard.rwLock.RLock()
defer shard.rwLock.RUnlock()
val, ok := shard.mapItem[key]
return val, ok
}
func (shardmap *ShardMap)Del(key string){
shard := shardmap.getShard(key)
shard.rwLock.RLock()
defer shard.rwLock.RUnlock()
delete(shard.mapItem, key)
}这三个方法的实现都是先根据key选定具体的分片,随后对片加锁后进行操作,随后解锁
计数
func (shardmap *ShardMap)Counts() int{
sum := 0
for _, val := range *shardmap{
val.rwLock.RLock()
sum += len(val.mapItem)
val.rwLock.RUnlock()
}
return sum
}一个goroutine直接遍历所有的分片,累加各片中元素个数
注:
- len(map)本身是O(1), 虽然可以开启多个goroutine分别计数,但那样需要额外的同步操作,增加了代码复杂度与运行时间,不值得
- 与C++的析构函数不同,defer在函数返回时才执行,前期只是入栈,因此在for循环内需要手动解锁,降低锁粒度
获取全部键值对
type ShardMapKVPair struct{
Key string
Value interface{}
}
func (shardmap *ShardMap)KeyValues() <-chan ShardMapKVPair{
count := shardmap.Counts()
ch := make(chan ShardMapKVPair, count)
go func(){
wg := sync.WaitGroup{}
wg.Add(sliceCount)
for _, elem := range *shardmap{
go func(ele *shard){
ele.rwLock.RLock()
for key,val := range ele.mapItem{
ch <- ShardMapKVPair{
Key: key,
Value: val,
}
}
ele.rwLock.RUnlock()
wg.Done()
}(elem)
}
wg.Wait()
close(ch)
}()
return ch
}- 使用了通道工厂,定义了一个用于外界读取的通道,并立即返回给调用者供其遍历,由内部的goroutine等待遍历各片goroutine结束,随后close通道,以向正在遍历通道的goroutine发出写完成消息,来结束通道的遍历
- 各分片内map里数据众多,所以需要多个goroutine分别获取键值对以提高效率
注: - 由于调度的关系,在循环内启动goroutine时,需要通过函数传参的方式将遍历参数绑定到goroutine中(C/C++种循环内创建线程时也需要注意此问题),否则可能预期不同
清空
func (shardmap *ShardMap)Clear(){
cpus := runtime.NumCPU()
var taskLenPerCPU = 0
if sliceCount % cpus == 0{
taskLenPerCPU = sliceCount / cpus //均分
}else{
taskLenPerCPU = sliceCount / cpus + 1 //除最后的g外均分,最后的g少分或没有
}
wg := sync.WaitGroup{}
wg.Add(cpus)
for i := 0; i < cpus; i++{
var tasks []*shard
if i == cpus - 1{
tasks = (*shardmap)[(i) * taskLenPerCPU :]
}else{
tasks = (*shardmap)[i * taskLenPerCPU : (i + 1) * taskLenPerCPU]
}
go func(mapItems []*shard){ //对切片分段处理
for _, val := range mapItems{
val.rwLock.Lock()
val.mapItem = make(map[string]interface{}) //清空map
val.rwLock.Unlock()
}
wg.Done()
}(tasks)
}
wg.Wait()
}清空函数中我采取了和获取键值对时不一样的方法,这种方法我一般在C/C++中用得比较多
通过创建Cpu核心数量的任务goroutine可以获取最好的性能,每个goroutine处理均分或尽量均分后的一段数据
分片选取
func (shardmap *ShardMap)getShard(key string)*shard{
hashVal := bkdrHash(key)
index := hashVal & (sliceCount - 1) //sliceCount为2的N次方成立
return (*shardmap)[index]
}
func bkdrHash(key string) uint32{
seed := uint32(131) // the magic number, 31, 131, 1313, 13131, etc.. orz..
hash := uint32(0)
for i := 0; i < len(key); i++ {
hash = hash * seed + uint32(key[i])
}
return hash & 0x7FFFFFFF
}对key计算hash,并根据子片数取余得到对应子片的下标
注:
- 计算hash时使用的是bkdr,此hash有较好的性能,也简单易实现,参考各种字符串Hash函数比较
- index := hashVal & (sliceCount - 1)使用位操作提高性能,当sliceCount为2的N次方时,等价于取余计算
性能测试
测试环境

9年前的老本了,性能测试只供参考,主要是比较与sync.map的性能
并行情况下getset
先来shardmap
const testCount = 1000000
func GenTestCase(count int) ([]string, []interface{}){
arr1 := make([]string, count)
arr2 := make([]interface{}, count)
for i := 0; i < count; i++{
arr1[i] = strconv.Itoa(i)
arr2[i] = i
}
return arr1, arr2
}
func BenchmarkShardMap_GetSet(b *testing.B) {
arr1, arr2 := GenTestCase(testCount)
shardMap := NewShardMap()
for i := 0; i < testCount; i++{
shardMap.SetVal(arr1[i], arr2[i])
}
b.N = testCount * 10
b.ResetTimer()
for i := 0; i < 10; i++{
rand.Seed(time.Now().UnixNano())
b.Run(fmt.Sprintf("times %d:", i), func(b *testing.B){
wg := sync.WaitGroup{}
wg.Add(2 *b.N)
for j := 0; j < b.N; j++{
go func(){
shardMap.SetVal(arr1[rand.Intn(testCount)], arr2[rand.Intn(testCount)])
wg.Done()
}()
go func(){
shardMap.GetVal(arr1[rand.Intn(testCount)])
wg.Done()
}()
}
wg.Wait()
})
}
}
再来sync.map
func BenchmarkSyncMap_GetSet(b *testing.B) {
arr1, arr2 := GenTestCase(testCount)
syncMap := sync.Map{}
for i := 0; i < testCount; i++{
syncMap.Store(arr1[i], arr2[i])
}
b.N = testCount * 10
b.ResetTimer()
for i := 0; i < 10; i++{
rand.Seed(time.Now().UnixNano())
b.Run(fmt.Sprintf("times %d:", i), func(b *testing.B){
wg := sync.WaitGroup{}
wg.Add(2 *b.N)
for j := 0; j < b.N; j++{
go func(){
syncMap.Store(arr1[rand.Intn(testCount)], arr2[rand.Intn(testCount)])
wg.Done()
}()
go func(){
syncMap.Load(arr1[rand.Intn(testCount)])
wg.Done()
}()
}
wg.Wait()
})
}
}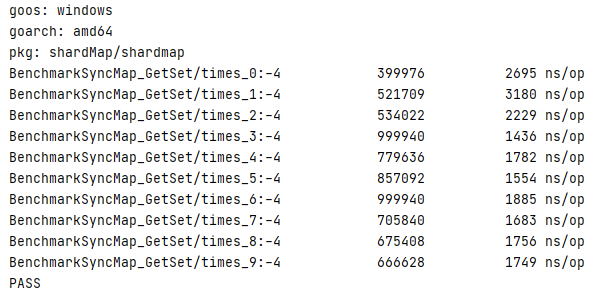
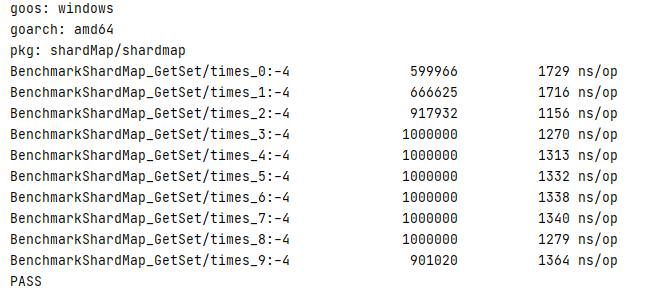
好像shardmap性能比sync.map稍好
非并行获取键值对
func BenchmarkShardMap_KeyValues(b *testing.B) {
arr1, arr2 := GenTestCase(testCount)
shardMap := NewShardMap()
for i := 0; i < testCount; i++{
shardMap.SetVal(arr1[i], arr2[i])
}
b.ResetTimer()
for i := 0; i < 10; i++{
b.Run(fmt.Sprintf("times %d:", i), func(b *testing.B){
keyVals := make([]ShardMapKVPair, 0)
for val := range shardMap.KeyValues(){
keyVals = append(keyVals, val)
}
})
}
}
type SyncMapKVPair struct {
key interface{}
val interface{}
}
func BenchmarkSyncMap_KeyValues(b *testing.B) {
arr1, arr2 := GenTestCase(testCount)
syncMap := sync.Map{}
for i := 0; i < testCount; i++{
syncMap.Store(arr1[i], arr2[i])
}
b.ResetTimer()
for i := 0; i < 10; i++{
b.Run(fmt.Sprintf("times %d:", i), func(b *testing.B){
keyVals := make([]SyncMapKVPair, 0)
syncMap.Range(func(key, value interface{}) bool {
keyVals = append(keyVals, SyncMapKVPair{
key,
value,
})
return true
})
})
}
}
单独测试清空
func BenchmarkShardMap_CLear(b *testing.B){
arr1, arr2 := GenTestCase(testCount)
shardMap := NewShardMap()
for i := 0; i < testCount; i++{
shardMap.SetVal(arr1[i], arr2[i])
}
b.ResetTimer()
for i := 0; i < 10; i++{
b.Run(fmt.Sprintf("times %d:", i), func(b *testing.B){
shardMap.Clear()
if shardMap.Counts() != 0{
b.Fatalf("Clear Fail")
}
})
}
}
不足
根据鸽巢原理,哈希算法必然存在冲突,可能导致随着时间的增长,每个分片间的数据个数不均匀,应该要有相应的扩容操作并将数据rehash来保证分片数据的均衡,为保证吞吐率,可以效仿redis的dict结构,实行渐进式rehash
参考
Shard Your Hash Table To Reduce Write Locks
各种字符串Hash函数比较