
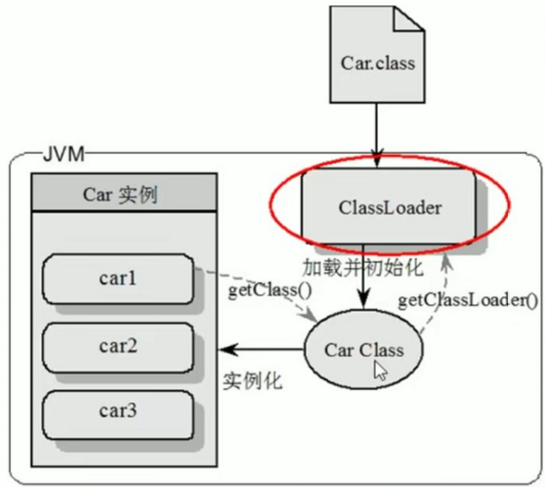
类装载器ClassLoader
- 负责加载class文件,class文件在
文件开头有特定的文件标示,将class文件字节码内容加载到内存中,并将这些内容转换成方法区中的运行时数据结构并且ClassLoader只负责class文件的加载,至于它是否可以运行,则由Execution Engine决定
双亲委派
- 当一个类收到了类加载请求,它首先不会尝试自己去加载这个类,而是把这个请求委派给父类去完成,每一个层次类加载器都是如此,因此所有的加载请求都应该传送到启动类加载其中,只有当父类加载器反馈自己无法完成这个请求的时候(在它的加载路径下没有找到所需加载的Class),子类加载器才会尝试自己去加载。
- 采用双亲委派的一个好处是比如加载位于rt.jar包中的类 java.lang.Object,不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这样就保证了使用不同的类加载器最终得到的都是同样的一个Object对象。
PC寄存器
- 每个线程都有一个程序计数器,是线程私有的,就是一个指针,指向方法区中的方法字节码(用来存储指向吓一跳指令的地址,也即将要执行的指令代码),由执行引擎读取下一条指令,是一个非常小的内存空间,几乎可以可以忽略不记。
- 这块内存区域很小,
它是当前线程所执行的字节码的行号指示器,字节码解释器通过改变这个计数器的值来选取下一条需要执行的字节码指令。 - 如果执行的是一个Native方法,那这个计数器是空的。
- 用以完成分支、循环、跳转、异常处理、线程恢复等基础功能。不会发生内存溢出(OutOfMemoru=OOM)错误
Method Area 方法区
- 供各线程共享的运行时内存区域。
它存储了每一个类的结构信息,例如运行时常量池(Runtime Constant Pool)、字段和方法数据、构造函数和普通方法的字节码内容。上面讲的是规范,在不同虚拟机里面实现是不一样的,最经典的就是永久代(PermGen space)和元空间(Metaspace)。 实例变量存在堆内存中,和方法区无关
Stack栈
- 栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,它的生命期是跟随线程的生命期,线程结束栈内存也就释放,
对于栈来说不存在垃圾回收问题,只要线程一结束该栈就Over,生命周期和线程一致,是线程私有的。8中基本类型的变量+对象的引用变量+实例方法都是在函数的栈内存中分配。
栈存储什么?
栈帧中主要保存3 类数据:
- 本地变量(Local Variables):输入参数和输出参数以及方法内的变量;
- 栈操作(Opearand Stack):记录出栈、入栈的操作;
- 栈帧数据(Frame Data):包括类文件、方法等等;
heap堆

MinorGC的过程(复制->清空->互换)
1、Eden、SurvivorFrom复制到SurvivorTo,年龄+1
- 首先,当Eden去蛮的时候回触发第一次GC,把还活着的对象开呗到SurvivorFrom区,当Eden区再次触发GC的时候会扫描Eden去和From区域,对这两个区域进行垃圾回收,经过这次回收后还存活的对象,则直接赋值到TOo区域(如果有对象的年龄已经达到了老年的标准,则赋值到老年代去),同时把这些对象的年龄+1
2、清空Eden、SurvivorFrom
- 然后,清空Eden和SurvivorFrom中的对象,也即复制之后有交换,谁空谁是to
3、SurvivorTo和SurvivorFrom互换
- 最后,SurvivorTo和SurvivorFrom互换,原SurvivorTo成为下一次GC时的SurvivorFrom区。部分对象会在From和To区域中复制来复制去,如此交换15次(由JVM参数MaxTenuringThreshold决定,这个参数默认是15),最终如果还是存活,就存入到老年代
永久区(java7之前有)
- 永久存储区是一个常驻内存区域,用于存放JDK自身所携带的Class,Interface的元数据,也就是说它存储的是运行环境必须的类信息,被装在进此区域的数据是不会被垃圾回收期回收掉的,关闭JVM才会释放此区域所占用的内存。
元空间(Java 8)
- 在Java8中,永久代已经被溢出,被一个成为
元空间的区域所取代。元空间的本质和永久代类似。 - 元空间与永久代之间臭的区别在于:
- 永久带使用的JVM的堆内存,但是java8以后的
元空间并不在虚拟机中,而是使用本机物理内存。
- 永久带使用的JVM的堆内存,但是java8以后的
- 因此,默认情况下,元空间的大小仅受本地内存限制。类的元数据放入 native memory,字符串池和类的静态变量放入 java 堆中,这样可以加载多少类的元数据就不再由MaxPermSize 控制,而由系统实际可用空间来控制。
堆内存调优简介 01
| -Xms | 设置初始分配大小,默认为物理内存的“1/64” |
|---|---|
| -Xmx | 最大分配内存,默认为物理内存的“1/4” |
| -XX:+PrintGCDetails | 输出详细的GC处理日志 |
package com.kng.test;
public class demo1 {
public static void main(String[] args) {
long maxMemory = Runtime.getRuntime().maxMemory();//返回java虚拟机试图使用的最大内存量
long totalMemory = Runtime.getRuntime().totalMemory();//返回Java虚拟机中的内存总量
System.out.println("MAX_MEMORY=" + maxMemory + "(字节)、"+(maxMemory/(double)1024/1024)+"MB");//MAX_MEMORY=1877475328(字节)、1790.5MB
System.out.println("TOTAL_MEMORY=" +totalMemory + "(字节)、"+(totalMemory/(double)1024/1024) + "MB"); //TOTAL_MEMORY=126877696(字节)、121.0MB
}
}
GC
GC是什么(分代收集算法)
- 次数上频繁收集Young区
- 次数上较少收集Old区
- 基本不动元空间
GC算法
引用计数法
缺点:
- 每次对对象赋值时均要维护引用计数器,且计数器本身也有一定的消耗;
- 较难处理循环引用
JVM的实现一般不采用这种方式
复制算法(Copying)
- Minor GC把Eden中的所有或的对象都移到Survivor区域中,如果Survivor区中放不下,那么剩下的活的对象就被移到Old generation,
也即一旦收集后,Eden是就变成空了。 - 当对象在Eden(包括一个 Survivor区域,这里假设是from区域)出生后,在经过一次 Minor GC后,如果对象还存活,并且能够被另外一块 Survivor 区域所容纳(上面已经假设为from区域,这里应为to区域,即to区域有足够的内存空间来存储Eden和from区域中存活的对象),则使用
复制算法将这些仍然还存活的对象复制到另外一块 Survivor 区域(即to区域)中,然后清理所使用的过的Eden 以及 Survivor 区域(即from区域),并且将这些对象的年龄设置为1.以后对象在 Survivor 区每熬过一次 Minor GC,就将对象的年龄+1,当对象的年龄达到某个值时(默认是15岁,通过-XX:MaxTenuringThreshold 来设定参数),这些对象就会成为老年代。 - -XX:MaxTenuringThreshold 谁知独享在新生代中存活的次数
标记清除(Mark-Sweep)
标记压缩(Mark-Compact)
年轻代中的GC,主要是复制算法(Copying)
HotSpot JVM把年轻代分为了三部分:1个Eden区和2个Survivor区(分别叫from和to)。默认比例为8:1:1,一般情况下,新创建的对象都会被分配到Eden区(一些大对象特殊对象),这些对象经过第一次Minor GC后,如果仍然存活,将会被移到Survivor区。独享在Survivor区中每熬过一次Minor GC,年龄就会增加1岁,当它的年龄增加到一定程度时,就会被移动到老年代中。因为年轻代中的对象基本都是朝生夕死的(90%以上),所以在年轻代的垃圾回收算法使用的是复制算法,复制算法的基本思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还活着的对象赋值到另外一块上面。赋值算法不会产生内存碎片。
GC算法总结
-
内存效率:赋值算法>标记清除算法>标记整理算法(此处的效率只是简单的对比时间复杂对,时间情况不一定如此)。
-
内存整齐度:赋值算法=标记整理算法>标记清除算法。
-
内存利用率:标记整理算法=标记清除算法>赋值算法。
面试题:gc 有没有最优算法?
- 回答:无。没有最好的算法,只有最合适的算法。 ===>分代收集算法
年轻代(Young Gen)
年轻代特点是区域相对老年代较小,独享存活率低- 这种情况复制算法的回收整理,速度是最快的。复制算法的效率只和当前存活对象大小有关,因而很适用与年轻代的回收。而复制算法内存利用率不高的问题,通过hotspot中的两个survivor的设计得到缓解。
老年代(Tenure Gen)
老年代的特点是区域较大,独享存活率高。- 这种情况,存在大量存活率高的对象,赋值算法明显变得不合适。一般是由标记清除或者是标记清除与标记整理的混合实现。