以下内容为听了达叔课程的笔记与疑惑之处,暂且都记下。如有不妥之处,尽情指出。
(1)二分类问题
目标:习得一个分类器,它以图片的特征向量作为输入,然后预测出结果 y 为 1 还是 0 。比如,我们需要预测一张图片是不是猫,输出 1 即预测是,0 则不是。
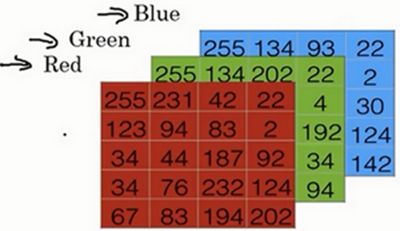
图片的特征向量:首先,计算机保存一张图片需要保存 3 个矩阵,分别对应 RGB 三个颜色通道。比如图片为 64 * 64 像素(下图故意为 5 * 4 规模),那就需要存储各个颜色通道上的像素强度。通过将 255,231...255,134...93,22... 等数字提取出来放到一个特征向量 x 中(即 (nx ,1 )nx = 64 * 64 * 3 = 12288,常用 n 表示特征向量维度 )。
相关符号:会在余下课程中涉及。
- x 表示一个 nx 维数据,为输入数据,(nx , 1)
- y 表示输出结果,取值为 1 or 0
- (x(i) , y(i)) 表示第 i 组训练数据 or 测试数据,默认是前者
- X = [ x(1) , x(2) , x(3) , x(4) ... x(m) ] 表示所有训练集的输入值,放在 nx * m 的矩阵中(在 Python 中常用 X.shape 这条命令表示规模)
- Y = [ y(1) , y(2) , y(3) , y(4) ... y(m)] 表示输出值
(2)逻辑回归
逻辑回归是应用于二分类问题的算法。
(1)逻辑回归的 Hypothesis Function (假设函数)
对于二分类问题,当输入 X (即图片特征向量) ,我们想要一个算法预测是不是输入了一只猫,即期望输出一个预测结果 y hat ,换句话说我们想要 y hat 表示 y = 1 的可能性。
已知 logistic 回归的参数有 w (nx 维向量,w 实际上是特征权重,维度与特征向量相同),b (实数,表偏差) 。所以给出输入 x,参数 w,b 之后,我们尝试通过 y hat = w^T * x + b,一个关于 x 的线性函数(适合用于做线性回归问题,不适合做二分类。因为 y hat 需要表示预测 y=1 的概率,所以取值属于 0~1 ,而线性回归函数取值不一定在此之内。),我们将线性回归式子作为 sigmoid 函数的自变量,将线性函数转化为非线性函数。

sigmoid 函数图像(为什么么选 sigmoid 函数作为逻辑回归函数,插眼)
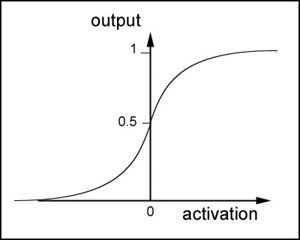
我们可以看到,当 z->∞,б->1,当 z->-∞,б->0。所以 z (即 y hat) 用来预测等于 1 的概率,怎么预测呢,就是不断调整训练 w,b 两个参数,控制 z ,再控制 б 的输出。
(2)逻辑回归的代价函数(logistic regression cost function)
为了训练 w,b 我们需要代价函数,通过代价函数来得到参数 w,b 。先看下逻辑回归函数:
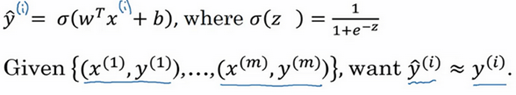
(1)损失函数(误差函数): Loss function : L(y hat, y)
根据此函数来衡量测试输出值 y hat 和 y 的差距大小。一般我们用两者平方差,但是在逻辑回归中我们不这样做,因为会发现优化目标不是凸忧化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值(插眼)。
所以定义了另一个损失函数:(为什么是这个函数呢,插眼---解释一:下文会提到 J(w,b) ,为保证 J(w, b) 函数是凸函数,即只有一个最小值)。
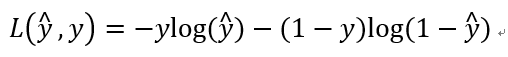
我们在来看看这个 Loss function 是否能满足基本取值要求:

在这门课中很多的函数效果和以上这个类似,如果 y = 1, 我们就尽可能让 y hat 变大,如果 y = 0, 我们就尽可能让 y hat 变小。(牢记 y hat 表示的是 y = 1 的概率)
(2)代价函数
损失函数是描述单个训练样本的,代价函数描述整个数据集的表现如何。代价函数是将所有数据集的损失函数求和再除 m (数据集大小)。
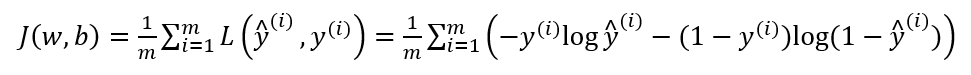
所以,在实际中,其实我们需要关注整个训练集,而不单单关注其中一次训练。即我们最终目标是找到变量 w,b 使得整个 J(w, b) 变成最小。
结果表明:逻辑回归函数可以看成一个非常小的神经网络。
(3)梯度下降法
我们已经有了上文提到的代价函数,那么怎么使得代价函数 J(w, b) 值最小呢?我们就通过梯度下降法实现。J(w, b) 函数可以表示成如下:其中红点处为最小值,此时的 w, b 就是我们所期盼的参数

(1)怎么找到最小值

可以用图中小红点初始化,对于逻辑回归函数所有的初始化几乎都有效,因为是凸函数,无论在哪里初始化,最终最小值应该找到大致相同的点。
所以可以从小红点开始,不断找该点梯度最大的,然后下降,不断迭代。最后找到全局或者部分最优解。
(2)进一步理解
其实将 J(w, b) 进行切面处理,在 w , b 轴都做切面,将三维转化成二维(投影),二维取到的最小值的点中必定包含着我们需要找的三位的最小值。

即 J(w) ,J(b) 只有一个参数,不断迭代:
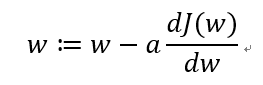
其中 “:=” 表示不断更新。a 表示学习率(后文会提及如何控制 a ),用来控制步长。a*d(J(w))/dw 用来表示具体 w 的每一次减少量,直至到 J(w) 的底部。最终回到 J(w,b) 改成求偏导:
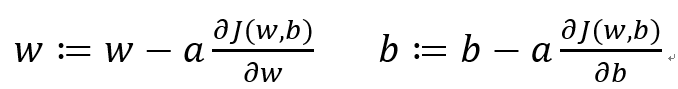
(4)计算图与其求导
在神经网络的计算中,都是按照向前或反向传播过程中组织的,紧接着进行一个反向传输操作,用来计算对应的梯度与倒数。
那这个和计算图有什么关系呢?我们举一个比逻辑回归更简单的神经网络:(蓝色为前向传播,红色为后向传播---求导)
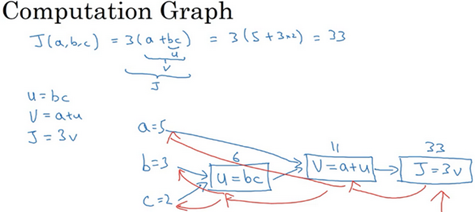
个人觉得,计算图最大的好处就是链式求导法则会更加清晰,

(5)逻辑回归中的梯度下降
本节讨论通过计算偏导数实现逻辑回归的梯度算法。
假设样本只有 x1,x2 ,为了计算 z ,我们需要输入 w1,w2,b 参数,即 z = w1*x1 + w2*x2 + b。
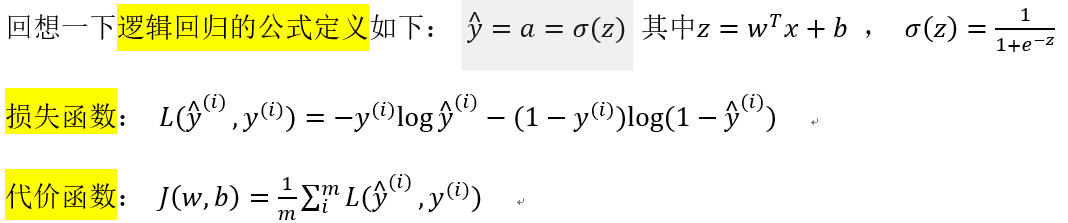
(1)假设现在只考虑单个样本情况
单个样本呢代价函数为:
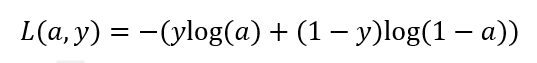
其中 a 是逻辑回归的输出(y hat),y 是样本标签值。那么我们可以得到表示这个计算的计算图:

上图写的是前向传播计算 L(a,y) 。我们现在通过反向计算出导数(这样就能知道 L 关于 w1,w2, b 的变化率)
编程中我们用 da 表示 d(a, y)/da (习惯写法记牢,>﹏<)。开始一步一步反向积分:

a = σ(z),所以我们可以求 dz :

再求 da/dz = a * (1 - a),过程:
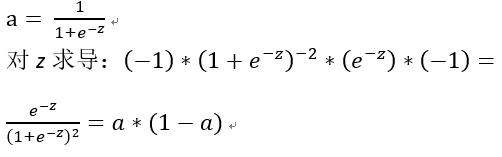
再回到 dz = dL / dz :
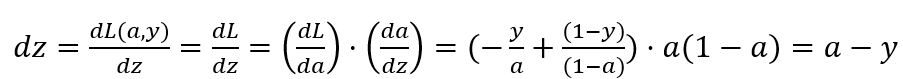
好了,想想我们最终的目的是谁,是参数 w1,w2,b 关于 L(w,b) 的变化率,所以别忘了找最终单个样本的代价函数 L -- w,b 之间的关系:
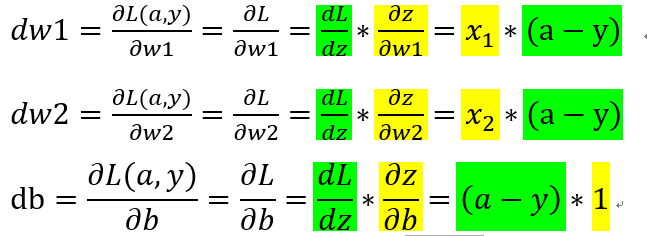
注意:L(a,y) 中 a 是复合函数,最终是关于 w1,w2,b 的函数,所以分清谁是自变量(不是 x1,x2哦),如上图,我详细写了的求导过程,但是上述都是对单个测试样本的后向传播。
那么我们就可以根据公式调整 w1,w2,b 了:
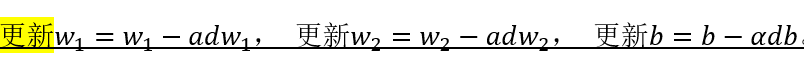
其中的a就是学习率(步长),后文会讲解,暂按下不表。
(2)考虑 m 个样本的梯度下降
上文已经提到了单个样本怎么训练(即调整参数 w1,w2,b ),那多个样本呢?我们先回顾多个样本的代价函数 J(w, b) 的定义:
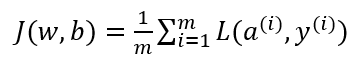
我们已经求得了单个样本的损失函数,代价函数无非是求和取平均值:
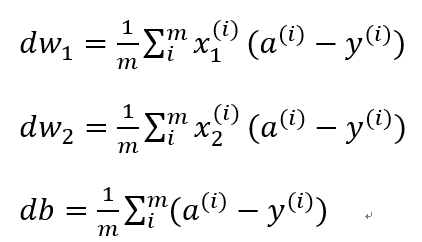
(3)m 个样本的梯度下降算法实现
算法大致流程:
1 J=0,dw_1=0,dw_2=0,db=0 # 我们初始化 2 3 J=0;dw1=0;dw2=0;db=0; # 代码流程 4 for i = 1 to m 5 z(i) = wx(i)+b; 6 a(i) = sigmoid(z(i)); 7 J += -[y(i)log(a(i))+(1-y(i))log(1-a(i)); 8 dz(i) = a(i)-y(i); 9 dw1 += x1(i)dz(i); 10 dw2 += x2(i)dz(i); 11 db += dz(i); 12 J/= m; 13 dw1/= m; 14 dw2/= m; 15 db/= m; 16 w=w-alpha*dw # alpha 就是步长 17 b=b-alpha*db
算法缺点:主要是 for 效率不高。代码有两处 for : ① 就是第一行,此处因为我们只有3个变量 w1,w2,b,如果有多个呢 ② 就是第四行,需要求和 dw1,dw2,db。后续会讲解改进方法。
(6)向量化
向量化的目的就是处理 for 循环,当数据量较大的时候,通过 for 来处理会十分低效。那么肿么向量化呢?
在逻辑回归中计算 z = w^T * x + b ,w/b 都是列向量,所以我们不妨将 x1,x2,x3...也当成一个向量。
非向量化处理 w^T * x VS 向量化处理:
1 z=0 2 for i in range(n_x) 3 z+=w[i]*x[i] 4 z+=b
1 z=np.dot(w,x)+b # 通过numpy函数向量化,插眼numpy函数需要继续学习,先有个向量化概念
达叔说我们应该尽量避免 for ,除非迫不得已,能用向量化解决(内置函数)是最好的。
我们现在来处理梯度下降算法,也就是通过向量化来处理:

w1,w2...变成一个 w 向量,x1,x2...变成一个 x 向量,z1,z2....变成 z 向量。这些向量都是 n 维向量。
(7)向量化逻辑回归
本节实现通过向量化显著加快你的代码。其实我感觉就是将 for 循环的重复 x1,x2..z1z2..等等放到一个向量里取处理,理解上没啥。
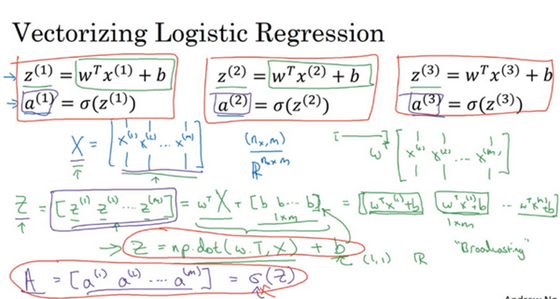
(8)向量化 logistic 回归的梯度输出
我们只需要比较原先写法和改用向量方式写法,就能更好理解了:(当然numpy 函数我还不怎么会搞)

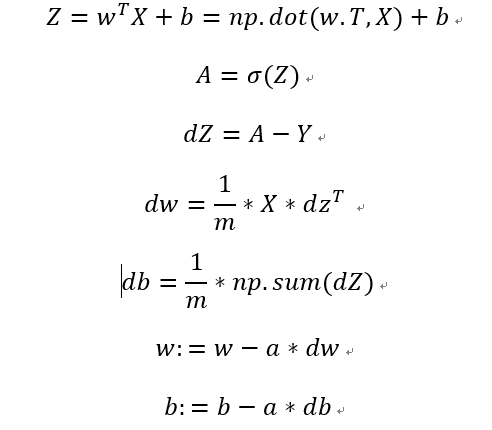
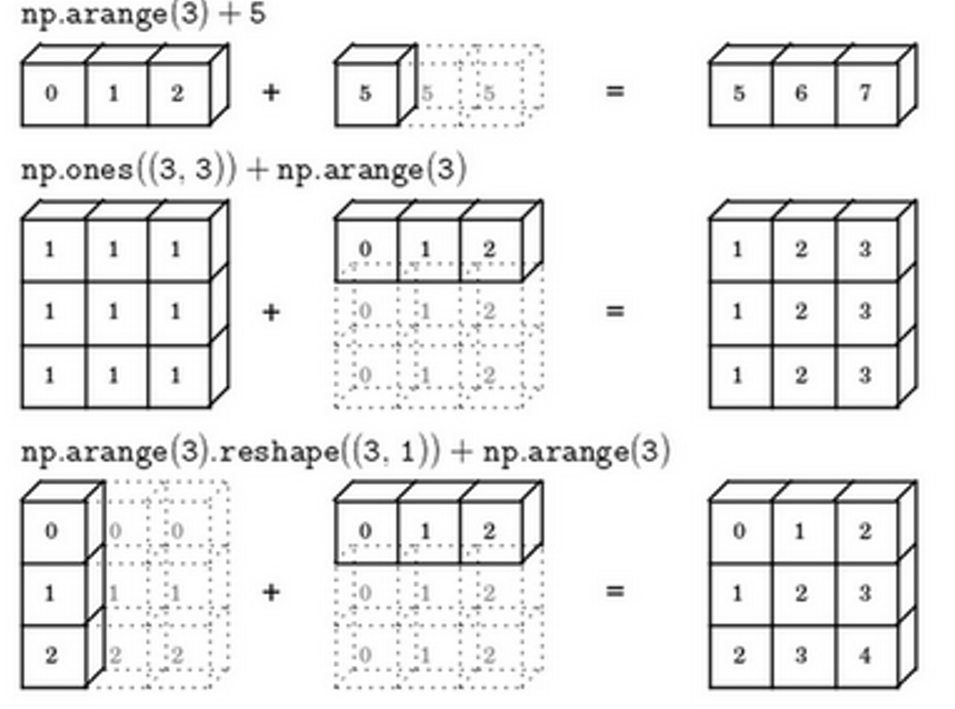
(9)Python中的广播
我们知道矩阵的加减乘法,那么如果两个举证格式按照线性代数来看不符合运算规则,那再Python中呢?Python会通过广播来实显示,也就是通过扩展矩阵使得可以运算: