一、学习任务的分类
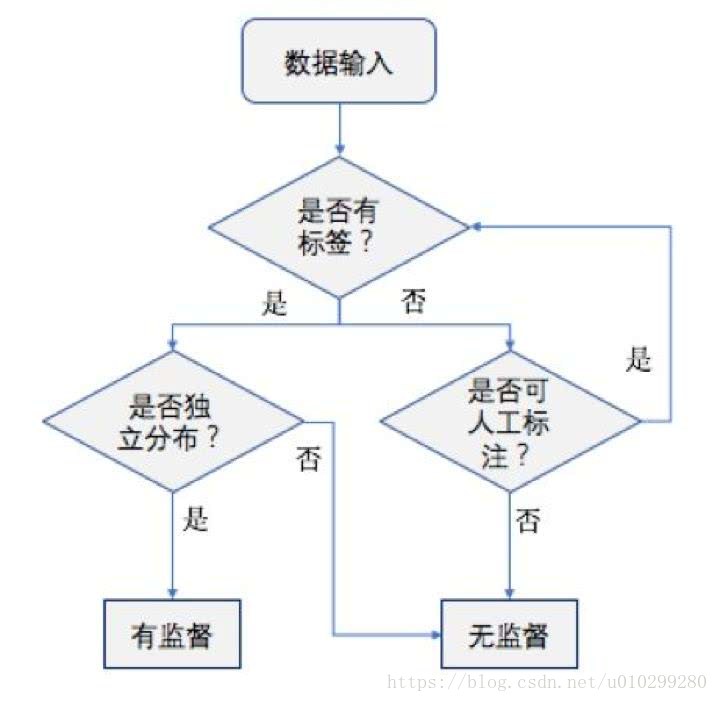
1。监督学习(supervised learning):分类、回归等。监督指标签,监督学习通过已知训练样本得到最优训练模型,适用于新数据上。反复这样的过程,模型就有了预测能力。
2.无监督学习(unsupervised learning):聚类等,不通过训练直接对数据进行建模分析,通过机器学习自行探索。
预测离散值的学习任务:分类学习(classification)
预测连续值得学习任务:回归学习(regression)
聚类(clustering):对训练集做簇划分,每个簇可能对应一些潜在得概念划分
二、其他概念
1.泛化(generalization):模型适应新样本的能力
2.归纳偏好:任何一个有效的机器学习算法必有其归纳偏好,否则在假设空间中会被与训练集看似等效的假设所迷惑,无法产生确定的学习结果。(尽管模型有可能任然产生与现实不符的结果,这不是一个好模型)
归纳偏好=学习算法的价值观,最基本的原则(非唯一),
“奥卡姆剃刀”:若有多个假设和观察一致,选最简单的那个。
3.NFL定理(No Free Lunch Theorem):假设学习的真实目标函数f均匀分布,无论学习算法优劣,他们的期望值都相同。
所以算法的归纳偏好与实际问题是否匹配是学习算法好坏的决定性因素。
4.发展历程
基于神经网络的“连接主义”学习--->基于逻辑表示的“符号主义”、以决策理论为基础的学习技术以及强化技术--->统计学习理论
《人工智能手册》中,将机器学习划分为“机械学习” “示教学习” “类比学习”和“归纳学习”。
示教学习、类比学习:从指令中学习,通过观察和发现学习。
归纳学习:从样例中学习。也是研究最多,应用最广。涵盖了监督学习和无监督学习等方面。其发展历程主要包括
(1) 符号主义学习:决策树、基于逻辑的学习(归纳逻辑程序设计ILP)。
(2) 基于神经网络的连接主义学习
(3) 统计学习:支持向量机(Support Vector Machine)
(4)深度学习:狭义上即多层神经网络