一、什么是xml
html:超文本标记语言。它主要是用来封装页面上要显示的数据,最后通过浏览器来解析html文件,然后把数据展示在浏览器上。同样我们可以使用JS和DOM技术对html文件进行解析和操作。
xml:可扩展的标记语言。它早期是为了代替html技术,但是由于html书写的网页在全球占有率太高,最后没有成功。
后期我们开始使用xml文件作为软件的配置文件,或者数据的存储文件,以及传输数据的文件。
二、xml的作用

xml文件主要是用来存储数据和传输数据。
在安卓、IOS等客户端系统和服务器交互过程中,一般会使用xml文件作为数据的传输。
描述省市关系:
<中国>
<省 name=”江苏省” id=”001”>
<市 name=”南京市”>
<区>yyy</区>
</市>
</省>
<省 name=”安徽省” id=”002”>
<市 name=”合肥市”>
<区>xxx</区>
</市>
</省>
</中国>
配置文件存在:
360等客户端程序中就使用xml文件作为配置文件。
三、xml语法
一个XML文件分为如下几部分内容:
文档声明 (重点)
元素(重点)
属性(重点)
注释
CDATA区 、特殊字符
处理指令(processing instruction)
1、文档声明
在定义xml文件的时候,通过声明告诉其他的解析软件,当前的这个文档是一个xml文档。
格式:
<?xml key=value key=value ?>
<?xml key=value key=value ?>
声明中的key和value是固定的:
version=1.0
<?xml version=”1.0” ?>
encoding=编码表
<?xml version=”1.0” encoding=”UTF-8” ?>
standalone="yes"
经常书写的xml的声明:
<?xml version=”1.0” encoding=”UTF-8” ?>

xml文件使用的是普通的记事本保存:
1、xml文件保存是采用GBK编码保存。
2、浏览器加载时会根据文档声明进行解码
3、如果文档声明的编码是UTF-8,那么就会中文乱码异常。
上述的关于声明中的乱码问题,在使用eclipse或MyEclipse无法测试的。
书写xml声明时的错误:
<?xml version="1.0" encoding="utf-8" ?>
在 < ? xml 之间不要有其他的字符 ?>也不要有其他的字符
2.、元素(标签)
xml中的标签 也 分成 单标签和双标签:
单标签: < 标签名 属性=值 属性=值 ...... />
双标签:< 标签名 属性=值 属性=值 ......>文本数据或子标签</标签名>
标签的书写注意事项:
1、xml中的所有标签必须闭合。
2、xml中的标签名称严格区分大小写。<User> <user>
3、在xml标签中间不要书写空格,或者 冒号 逗号 等符号。
4、标签名不要以数字开始。
书写xml标签时 ,标签不能互相嵌套。
<age>23<name>zhangsan></age></name>
在xml中标签的属性可以写成标签的子标签。
<user password=”abc”/>
<user><password>abc</password></user>
在使用程序解析xml中的标签 属性 和文本的时候, 标签中的回车换行都会解析成当前标签的子标签。
所有的xml文件只能有一个根标签。
3.、xml属性
在标签上可以书写属性:
一个标签上可以书写多个属性。每个属性的值可以使用 单引号 或 双引号引用。
的规则和标签的书写规则一致。
4、xml注释:
xml中的注释和html的注释书写一致:
格式:
<!-- 注释内容 -->
如果使用浏览器解析xml文件,那么xml文件中的注释会显示在浏览器中。
5、文本区域(CDATA区)
当我们希望把一本文本原样显示在浏览器中时。
可以使用xml中提供的CDATA区。
格式:
<![CDATA[需要原样显示的数据]]>
需求:
1、在xml文件中原样显示
<h1>在html表示的是标题标签
<br>在html表示换行
注意:书写时 一定要在根标签内。
由于CDATA 区域书写比较麻烦,可以使用特殊字符:
<
$gt;
用转义字符完成需求1;
6.、处理指令
处理指令,简称PI (processing instruction)。处理指令用来指挥解析引擎如何解析XML文档内容。
例如,在XML文档中可以使用xml-stylesheet指令,通知XML解析引擎,应用css文件显示xml文档内容。 <?xml-stylesheet type="text/css" href="1.css"?>
处理指令必须以“<?”作为开头,以“?>”作为结尾,XML声明语句就是最常见的一种处理指令。
xml文件
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/css" href="1.css"?> //处理指令 引用1.css 3 <books> 4 <book> 5 我去 6 </book> 7 <author> 8 HELLO 9 </author> 10 </books>
1.css
1 book { 2 color:red; 3 }
四、xml的约束
由于xml语法中规定标签可以由开发者自己定义。导致解析时无法使用同一的代码来解析。
W3C组织它们早期指定的xml的约束技术为DTD技术,后期升级为Schema约束。
1.DTD约束:
DTD的快速入门:
a、先创建一个xml文件:

b、书写一个DTD文件
dtd文件的扩展名 必须是dtd
在xml中有多少个不同的标签,在dtd中就书写多少个ELEMNT
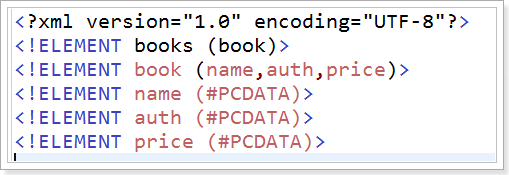
c、在xml文件中导入DTD的约束
格式:
DTD和xml文件的结合方式:
使用内部DTD
可以把dtd和xml书写在同一个文件中:
<!DOCTYPE 根标签名 [
写dtd的约束
] >
使用外部DTD
可以把DTD文件和xml文件分别书写在2个文件中,然后在xml文件中使用:
<!DOCTYPE 根标签名 SYSTEM “dtd文件的路径” >
使用公共DTD
可以引入互联网中存在一个DTD约束。
<!DOCTYPE 文档根结点 PUBLIC "DTD名称" "DTD文件的URL">
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
4.3、DTD的元素(ELEMENT)定义
<!DOCTYPE 根元素 SYSTEM "文件名">

DTD的学习目的:
可以看懂DTD文件,基于这个DTD文件可以写一个符合约束的xml文件即可。
2.、DTD的语法介绍
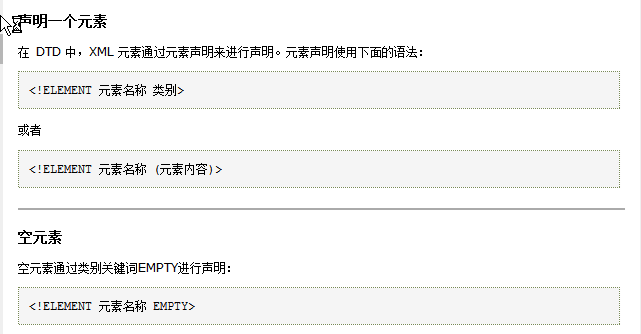
在DTD中使用 ELEMENT 声明当前xml中可以出现的标签名称, () 限制当前这个标签中的文本或者子标签。

告诉我们 当前的xml中可以有一个 books 标签,在这个books标签下可以有一个或多个book子标签。
+ 当前括号中的这个标签可以出现一次或多次
? 当前括号中的这个标签可以出现零次或一次
* 当前括号中的这个标签可以出现零次或多次

括号中的逗号,是在定义出现的子标签的顺序。

当前这个name标签中可以书写文本
4、属性(ATTLIST)定义

<!ATTLIST 标签名
属性名 属性类型 属性约束
属性名 属性类型 属性约束
...
>
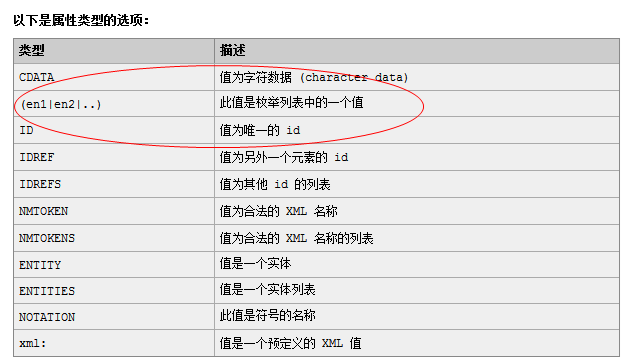

5、实体(ENTITY)定义

1 <?xml version="1.0" encoding="UTF-8"?> 2 3 <!DOCTYPE books [ 4 <!ELEMENT books (book+)> 5 <!ELEMENT book (name,auth,price)> 6 <!ELEMENT name (#PCDATA)> 7 <!ELEMENT author (#PCDATA)> 8 <!ELEMENT price (#PCDATA)> 9 10 <!ENTITY writer "Bill Gates"> 11 ]> 12 <books> 13 <book> 14 <name>九阴真经</name> 15 <auth>&writer;</auth> 16 <price>9.9</price> 17 </book> 18 <book> 19 <name>九阳神功</name> 20 <auth></auth> 21 <price>9.8</price> 22 </book> 23 </books>
五、Schema约束
Schema它也是用来约束xml文件的。
DTD的缺点:
1、DTD约束xml的时候,不能对xml中的数据类型做详细的限定。
2、DTD约束有自己的语法,书写时必须遵守DTD的语法。
3、一个xml文件中只能引入一个DTD约束,而无法通过多个DTD文件来约束同一个xml文件。
Schema约束:
对DTD那些缺点进行补充。Schema文件它本身就是一个xml文件。书写的时候,它遵守xml的语法规则。
在书写Schema的时候,就和书写xml文件一样。
书写Schema文件的时候,它的文件扩展名xsd。
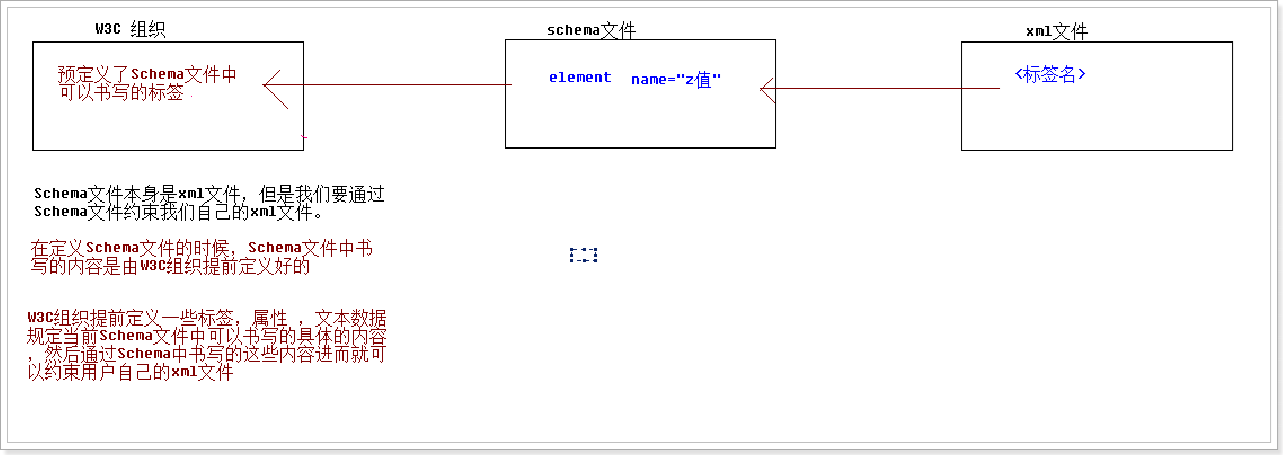
1、Schema快速入门
a、定义一个xml文件
1 <?xml version="1.0" encoding="UTF-8"?> 2 <books> 3 <book aaa="one" bbb="zhangsan" ccc="c001" ddd="d001"> 4 <name>九阴真经</name> 5 <auth>班长</auth> 6 <price>9.9</price> 7 </book> 8 <book aaa="one" bbb="zhangsan" ccc="c001" ddd="d001"> 9 <name>九阳神功</name> 10 <auth>班导</auth> 11 <price>9.8</price> 12 </book> 13 </books>
b、书写一个Schema文件
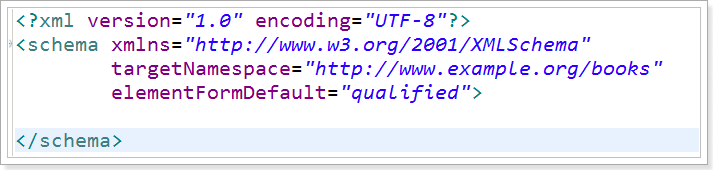
1、在Schema文件中 必须以 schema作为 Schema文件的根标签。

它的含义是表示当前的Schema文件是被当前指定的url(名称空间)所约束。

给当前这个Schema文件起名字,当需要被当前这个Schema文件约束的xml文件,需要通过当前这个名字引入当前Schema文件。
targetNamespace属性对应的属性值,可以是任意的内容。
在Schema文件中书写当前xml中可以出现的标签 以及子标签 等信息
1、先清楚xml中需要多少个不同标签,在Schema文件中就书写多少个element标签
2、element标签中的 name属性 就是xml中 可以书写的标签的名字
3、在Schema中它把xml中可以出现的标签分成简单标签和复杂标签
简单标签:只有文本数据的标签,成为简单标签
复杂标签:如果标签上有属性,或者有子标签,或者有属性和子标签 或 属性和文本的标签复杂标签
4、针对复杂标签,需要在当前的标签中书写子标签来限制当前复杂标签中的其他内容
在element标签中需要使用complexType 声明当前的element标签name属性指定的是一个复杂标签
如果是简单标签可以使用simpleType
5、对于复杂标签 需要 在 complexType中书写 sequence 标签 表示子标签的顺序
1 <schema xmlns="http://www.w3.org/2001/XMLSchema" 2 targetNamespace="http://www.huyouta.com/books" 3 elementFormDefault="qualified"> 4 5 <!-- 6 在Schema文件中书写当前xml中可以出现的标签 以及子标签 等信息 7 1、先清楚xml中需要多少个标签,在Schema文件中就书写多少个element标签 8 2、element标签中的 name属性 就是xml中 可以书写的标签的名字 9 3、在Schema中它把xml中可以出现的标签分成简单标签和复杂标签 10 简单标签:只有文本数据的标签,成为简单标签 11 复杂标签:如果标签上有属性,或者有子标签,或者有属性和子标签 或 属性和文本的标签复杂标签 12 4、针对复杂标签,需要在当前的标签中书写子标签来限制当前复杂标签中的其他内容 13 在element标签中需要使用complexType 声明当前的element标签name属性指定的是一个复杂标签 14 如果是简单标签可以使用simpleType 15 5、对于复杂标签 需要 在 complexType中书写 sequence 标签 表示子标签的顺序 16 17 --> 18 <element name="books"> <!-- books 是一个复杂标签 --> 19 <complexType> 20 <sequence> <!-- 定义当前books 标签中的子标签的顺序 --> 21 <element name="book"> 22 <complexType> <!-- 声明当前的book 又是一个复杂标签 --> 23 <sequence> 24 <!-- 在element 标签中的 type属性来限制当前单标签中文本的类型 --> 25 <element name="name" type="string"></element> 26 <element name="author" type="string"></element> 27 <element name="price" type="double"></element> 28 </sequence> 29 </complexType> 30 </element> 31 </sequence> 32 </complexType> 33 </element> 34 </schema>
3、在xml文件中引入Schema文件
xmlns="http://www.huyouta.com/books"
在xml中引入 Schema文件的名称
1 <?xml version="1.0" encoding="UTF-8"?> 2 <books xmlns="http://www.huyouta.com/books" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://www.huyouta.com/books books.xsd" 5 > 6 <book> 7 <name>葵花宝典</name> 8 <author>班长</author> 9 <price>9.9</price> 10 </book> 11 </books>

5. 2、名称空间
在书写Schema文件的时候,需要在Schema文件中 使用 targetNamespace 属性 给当前的Schema文件起名。
把targetNamespace 属性的 值 成为当前 Schema文件的名称空间。
在xml文件中 需要 通过 xmlns 来引入不同名称下的 Schema文件。
如果我们在同一个 xml文件中引入了多个 Schema的名称空间,这时需要大家 给这些名称空间其别名。
如果在xml文件使用 使用了 多个 xmlns 引入 多个名称空间时 需要 在xmlns后面 使用冒号 给当前的 名称空间 起名。通过这个别名 区分到底 当前xml中的标签 受限于 具体 哪个Schema文件。
Schema中限制xml标签中的属性定义格式:

六、xml解析
xml可扩展的标记语言。
不管是html文件还是xml文件它们都是标记型文档,都可以使用w3c组织制定的dom技术来解析。
dom解析技术是W3C组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。
Java对dom技术解析标记型文档也做了实现:
早期sun公司就制定的 dom 技术。而这个技术在页面xml的时候需要把整个xml文件加载到内存中,可以根据getElementById、getElementsByName 、getElementsByTagName 等方法解析。
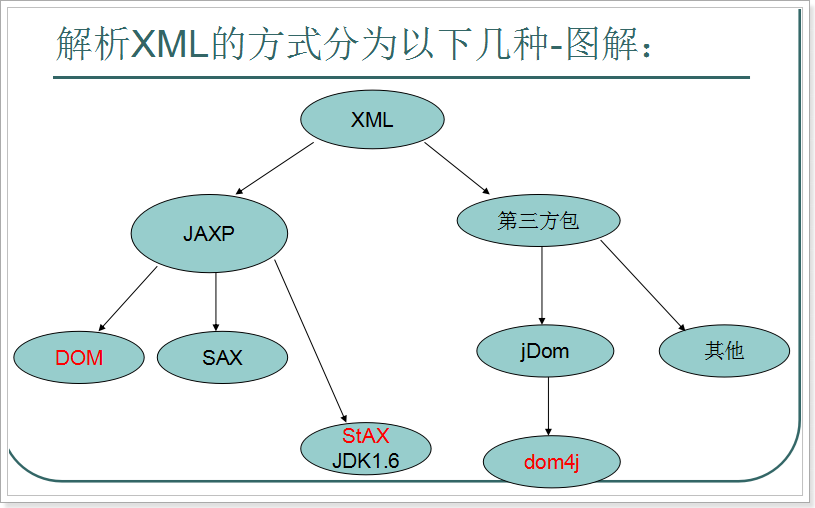
sun公司在JDK6版本对 dom解析技术进行升级 :SAX解析 Stax 解析
sun公司的解析统称 JAXP。
第三方的解析:
pull、xStream、jDOM、dom4j。
七、dom4j解析技术
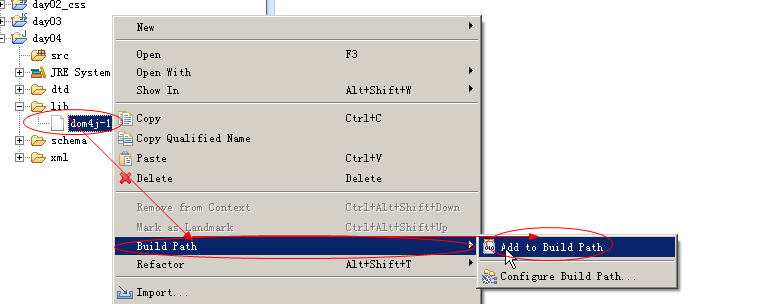
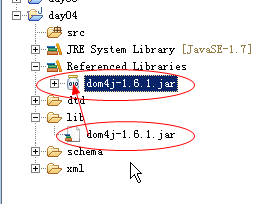
由于dom4j 它不是sun公司的技术,而属于第三方公司的技术,我们需要使用dom4j 就需要到dom4j官网下载dom4j的jar包。

把dom4jjar包拷贝我们的项目中:
在自己的项目中,新建一个lib文件,把dom4j jar包拷贝到其中

准备的xml文件
1 <?xml version="1.0" encoding="UTF-8"?> 2 <users> 3 <user> 4 <name>杨过</name> 5 <age>18</age> 6 <sex>男</sex> 7 </user> 8 <user> 9 <name>小龙女</name> 10 <age>18</age> 11 <sex>女</sex> 12 </user> 13 </users>
1 、获取document对象

2、获取所有标签中的文本值
1 //演示使用dom4j 获取 xml中的标签中的数据 2 public static void getElement()throws Exception{ 3 SAXReader reader = new SAXReader(); 4 // 获取dom树 5 Document dom = reader.read("users.xml"); 6 7 //获取xml中的根标签 8 Element root = dom.getRootElement(); 9 10 //获取 根标签下的所有 子标签 11 List<Element> list = root.elements(); 12 13 //遍历集合,获取到 每个 user标签 14 for (Element e : list) { 15 Element name = e.element("name"); 16 Element age = e.element("age"); 17 Element sex = e.element("sex"); 18 System.out.println(name.getText() + ":" + age.getText() +":"+ sex.getText()); 19 } 20 }
3.修改指定标签中的值
1 //把最后一个user中的sex 修改为女 2 public static void UpdateElement()throws Exception{ 3 SAXReader reader = new SAXReader(); 4 // 获取dom树 5 Document dom = reader.read("users.xml"); 6 7 //先获取 根标签 8 Element root = dom.getRootElement(); 9 //获取 users 下的所有user标签 10 List<Element> list = root.elements(); 11 12 //获取最后一个user标签 13 Element lastUser = list.get(list.size()-1); 14 15 Element sex = lastUser.element("sex"); 16 17 sex.setText("女"); 18 19 //把内存中修改后的dom树 重新写到xml文件中 20 //创建用于写出数据的流对象 21 //XMLWriter writer = new XMLWriter(new FileOutputStream("users.xml")); 22 23 //创建一个格式器 24 OutputFormat format = OutputFormat.createPrettyPrint(); 25 //设置编码表 26 format.setEncoding("gbk"); 27 28 XMLWriter writer = new XMLWriter(new FileWriter("users.xml") ,format ); 29 //写出数据 30 writer.write(dom); 31 //关流 32 writer.close(); 33 34 }
4、删除标签
1 // 删除 2 public static void deleteElement() throws Exception { 3 SAXReader reader = new SAXReader(); 4 // 获取dom树 5 Document dom = reader.read("users.xml"); 6 7 // 删除最后一个user标签 8 9 // 先获取 根标签 10 Element root = dom.getRootElement(); 11 // 获取 users 下的所有user标签 12 List<Element> list = root.elements(); 13 14 // 获取最后一个user标签 15 Element lastUser = list.get(list.size() - 1); 16 17 root.remove(lastUser); 18 19 XMLWriter writer = new XMLWriter(new FileOutputStream("users.xml")); 20 writer.write(dom); 21 // 关流 22 writer.close(); 23 24 }
5、增加标签
1 // 创建一个新的dom写到文件 2 public static void addElement() throws Exception { 3 4 // 先创建一个dom树 这个dom树在内存中 5 Document dom = DocumentHelper.createDocument(); 6 7 // 给树上添加根节点 8 Element books = dom.addElement("books"); 9 10 // 给根books上添加了2个book 标签 11 Element book = books.addElement("book"); 12 Element book2 = books.addElement("book"); 13 14 // 给book标签上添加 子标签 15 Element name = book.addElement("name"); 16 Element author = book.addElement("author"); 17 Element price = book.addElement("price"); 18 19 // 给book下的子标签中添加文本 20 name.setText("九阴真经"); 21 author.addText("王炎"); 22 price.addText("1.1"); 23 24 // 给book标签上添加 子标签 25 Element name2 = book2.addElement("name"); 26 Element author2 = book2.addElement("author"); 27 Element price2 = book2.addElement("price"); 28 29 // 给book下的子标签中添加文本 30 name2.setText("九阳神功"); 31 author2.addText("赵敏"); 32 price2.addText("1.2"); 33 34 // 给book标签上添加属性 35 book.addAttribute("addr", "藏经阁"); 36 book2.addAttribute("addr", "桃花岛"); 37 38 OutputFormat format = OutputFormat.createPrettyPrint(); 39 XMLWriter writer = new XMLWriter(new FileOutputStream("books2.xml"),format); 40 writer.write(dom); 41 // 关流 42 writer.close(); 43 }
6、工具类抽取
1 /** 2 * 这时一个工具类,它的功能是完成对dom数的获取和保存 3 * 4 * @author 上海传智播客 5 * @version 1.0 6 */ 7 public class DomUtils { 8 9 private static Document dom = null; 10 11 static{ 12 try{ 13 SAXReader reader = new SAXReader(); 14 // 获取dom树 15 dom = reader.read("users.xml"); 16 }catch( Exception e ){ 17 //把异常写到日志文件中 18 System.out.println("恭喜您,获取dom树失败!!!"); 19 } 20 } 21 /** 22 * 用于获取dom树的方法 23 */ 24 public static Document getDom(){ 25 return dom; 26 } 27 28 /** 29 * 保存dom树 30 */ 31 public static void saveDom(){ 32 try{ 33 OutputFormat format = OutputFormat.createPrettyPrint(); 34 XMLWriter writer = new XMLWriter(new FileOutputStream("users.xml"),format); 35 writer.write(dom); 36 // 关流 37 writer.close(); 38 }catch(Exception e){ 39 System.out.println("恭喜您,保存dom树失败!!!"); 40 } 41 } 42 }
八、xpath技术
xpath技术 也是 W3C 组织制定的 快速获取 xml 文件中某个 标签的 技术。
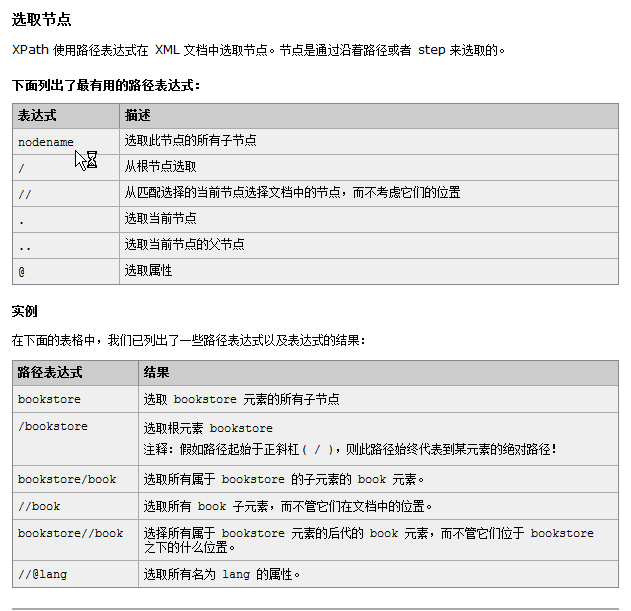
在xpath中 / 表示从根开始找标签 // 表示 不考虑标签的位置 只要匹配上就可以
//abc[@属性名] 选择abc标签,但是要求abc 必须有指定属性名
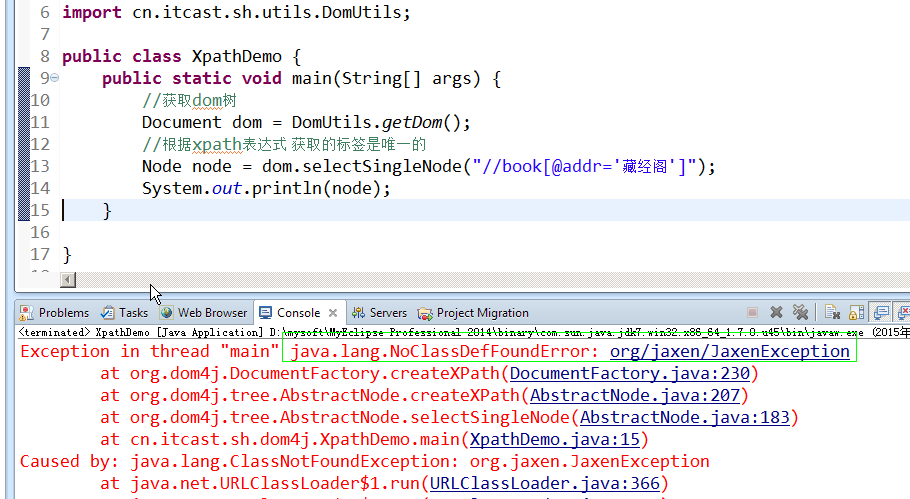
在使用xpath技术结合 dom4j 快速获取标签, 发生了异常:
如果大家以后使用的第三方jar,在运行的时候,报了 类 没有找到 异常。这时一般情况下都是缺少 jar包。
一般如果缺少jar包的话, 在报的异常中的第二个单词 或者第三个单词 是jar包的名称。
去dom4j下的lib包下去找到jaxen 然后add buildpath