一、导入url
以这个链接为例 https://www.hurun.net/zh-CN/Info/Detail?num=E7190250C866
# 导入pandas 这个模块
import pandas as pd
# 网页链接
url = "xxx"
# header=0指定列标题所在的行为第0行,encoding="utf-8"中文字符编码,不添加可能会出现乱码
text = pd.read_html(url, encoding="utf-8", header=0)
text
运行可得以下数据:
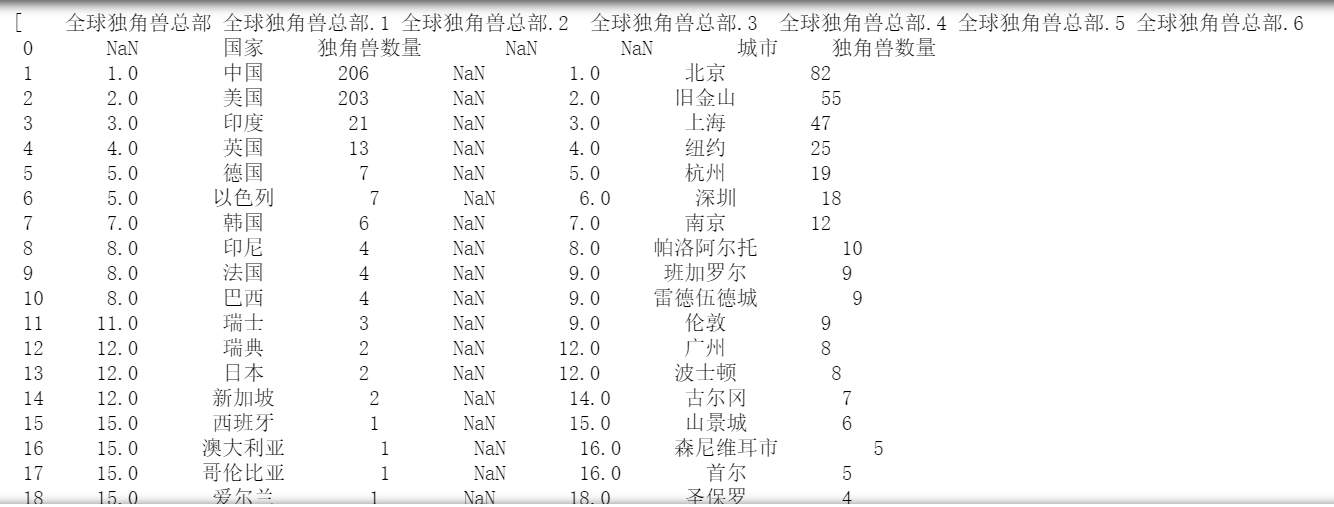
二、将表格展示出来
python重要内置函数:enumerate
enumerate函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
#利用for循环将所有表格遍历出来
for i,a in enumerate(text):
print('第',i,'个表格') #注意:字符串与变量连接要用逗号“,”,字符串与字符串拼接才用“+”号
display(a) #display这里是用来输出表格的,而print()是属于python内置函数不能输出表格的
运行可得以下数据:

三、取出表格
# 列表中用[]访问元素,这里是取出这个列表中第10个表格
all_table=text[10]
all_table
运行可得以下数据:
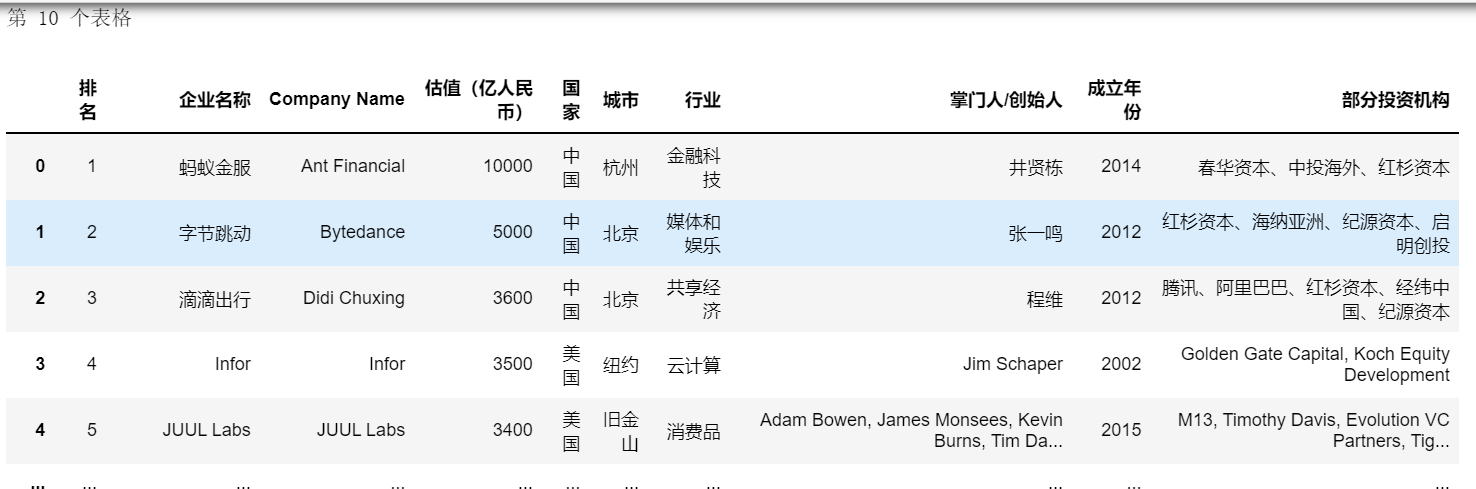
四、输出成excel表格
- 单页输出:xx.to_excel("文件名")
- 多页sheet表格输出到一个excel文件中:使用pandas模块中pd.ExcelWriter
- excel文件已经存在并且里边有内容,输出数据会覆盖掉原有内容
- excel文件不存在,pd.ExcelWriter会自动生成一个新的excel文件
这里采用单页输出
all_table.to_excel("全球独角兽企业.xlsx")
运行可以在文件夹中找到这个:
