一、前述
今天继续整理几个Transformation算子如下:
- mapPartitionWithIndex
- repartition
- coalesce
- groupByKey
- zip
- zipWithIndex
二、具体细节
- mapPartitionWithIndex
类似于mapPartitions,除此之外还会携带分区的索引值。
java代码:
package com.spark.spark.transformations; import java.util.ArrayList; import java.util.Arrays; import java.util.Iterator; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function2; public class Operator_mapPartitionWithIndex { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("mapPartitionWithIndex"); JavaSparkContext sc = new JavaSparkContext(conf); List<String> names = Arrays.asList("zhangsan1", "zhangsan2", "zhangsan3","zhangsan4"); /** * 这里的第二个参数是设置并行度,也是RDD的分区数,并行度理论上来说设置大小为core的2~3倍 */ JavaRDD<String> parallelize = sc.parallelize(names, 3); JavaRDD<String> mapPartitionsWithIndex = parallelize.mapPartitionsWithIndex( new Function2<Integer, Iterator<String>, Iterator<String>>() { /** * */ private static final long serialVersionUID = 1L; @Override public Iterator<String> call(Integer index, Iterator<String> iter) throws Exception { List<String> list = new ArrayList<String>(); while(iter.hasNext()){ String s = iter.next(); list.add(s+"~"); System.out.println("partition id is "+index +",value is "+s ); } return list.iterator(); } }, true); mapPartitionsWithIndex.collect(); sc.stop(); } }
scala代码:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import scala.collection.mutable.ListBuffer
object Operator_mapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("mapPartitionsWithIndex")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List("a","b","c"),3)
rdd.mapPartitionsWithIndex((index,iter)=>{
val list = ListBuffer[String]()
while(iter.hasNext){
val v = iter.next()
list.+(v)
println("index = "+index+" , value = "+v)
}
list.iterator
}, true).foreach(println)
sc.stop();
}
}
代码解释:
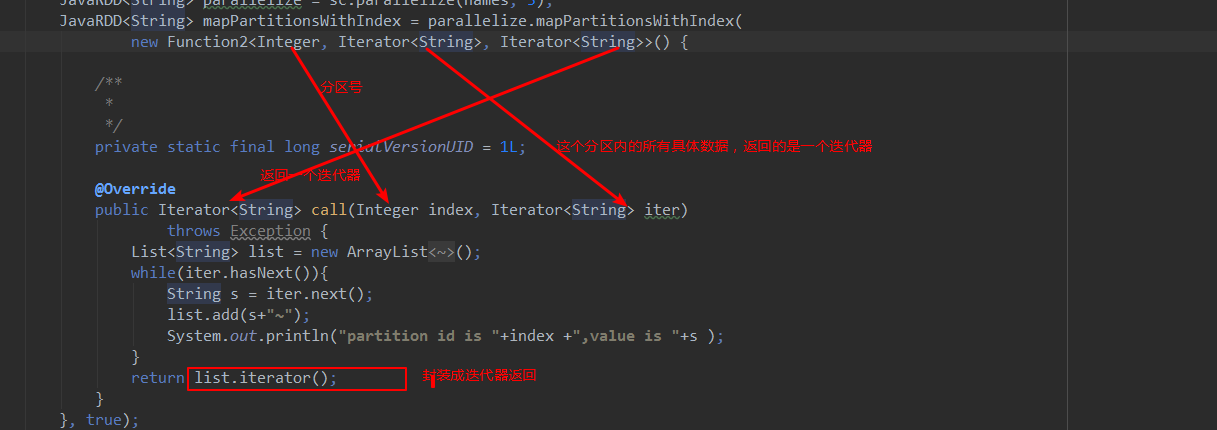
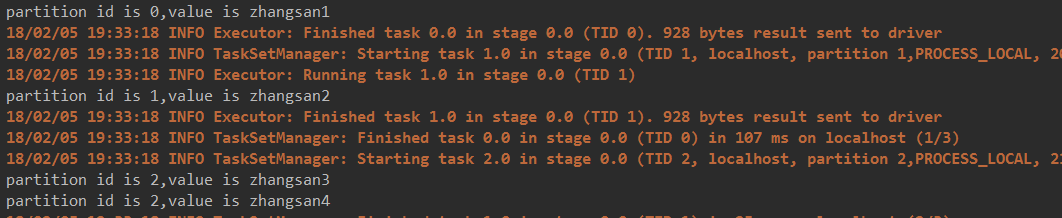
结果:
- coalesce
coalesce常用来减少分区,第二个参数是减少分区的过程中是否产生shuffle。
true为产生shuffle,false不产生shuffle。默认是false。
如果coalesce设置的分区数比原来的RDD的分区数还多的话,第二个参数设置为false不会起作用,如果设置成true,效果和repartition一样。即repartition(numPartitions) = coalesce(numPartitions,true)
java代码:
package com.spark.spark.transformations; import java.util.ArrayList; import java.util.Arrays; import java.util.Iterator; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function2; /** * coalesce减少分区 * 第二个参数是减少分区的过程中是否产生shuffle,true是产生shuffle,false是不产生shuffle,默认是false. * 如果coalesce的分区数比原来的分区数还多,第二个参数设置false,即不产生shuffle,不会起作用。 * 如果第二个参数设置成true则效果和repartition一样,即coalesce(numPartitions,true) = repartition(numPartitions) * * @author root * */ public class Operator_coalesce { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("coalesce"); JavaSparkContext sc = new JavaSparkContext(conf); List<String> list = Arrays.asList( "love1","love2","love3", "love4","love5","love6", "love7","love8","love9", "love10","love11","love12" ); JavaRDD<String> rdd1 = sc.parallelize(list,3); JavaRDD<String> rdd2 = rdd1.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>(){ /** * */ private static final long serialVersionUID = 1L; @Override public Iterator<String> call(Integer partitionId, Iterator<String> iter) throws Exception { List<String> list = new ArrayList<String>(); while(iter.hasNext()){ list.add("RDD1的分区索引:ll【"+partitionId+"】,值为:"+iter.next()); } return list.iterator(); } }, true); JavaRDD<String> coalesceRDD = rdd2.coalesce(2, false);//不产生shuffle //JavaRDD<String> coalesceRDD = rdd2.coalesce(2, true);//产生shuffle //JavaRDD<String> coalesceRDD = rdd2.coalesce(4,false);//设置分区数大于原RDD的分区数且不产生shuffle,不起作用 // System.out.println("coalesceRDD partitions length = "+coalesceRDD.partitions().size()); //JavaRDD<String> coalesceRDD = rdd2.coalesce(5,true);//设置分区数大于原RDD的分区数且产生shuffle,相当于repartition // JavaRDD<String> coalesceRDD = rdd2.repartition(4); JavaRDD<String> result = coalesceRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>(){ /** * */ private static final long serialVersionUID = 1L; @Override public Iterator<String> call(Integer partitionId, Iterator<String> iter) throws Exception { List<String> list = new ArrayList<String>(); while(iter.hasNext()){ list.add("coalesceRDD的分区索引:【"+partitionId+"】,值为: "+iter.next()); } return list.iterator(); } }, true); for(String s: result.collect()){ System.out.println(s); } sc.stop(); } }
scala代码:
package com.bjsxt.spark.transformations
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ListBuffer
object Operator_repartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("repartition")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(1,2,3,4,5,6,7),3)
val rdd2 = rdd1.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = new ListBuffer[String]()
while(iter.hasNext){
list += "rdd1partitionIndex : "+partitionIndex+",value :"+iter.next()
}
list.iterator
})
rdd2.foreach{ println }
val rdd3 = rdd2.repartition(4)
val result = rdd3.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = ListBuffer[String]()
while(iter.hasNext){
list +=("repartitionIndex : "+partitionIndex+",value :"+iter.next())
}
list.iterator
})
result.foreach{ println}
sc.stop()
}
}
代码解释:
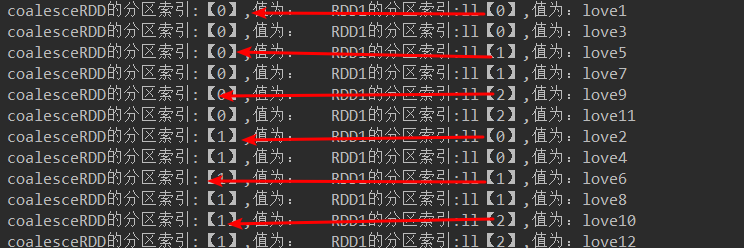
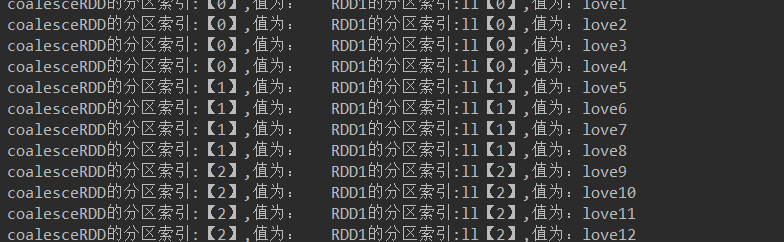
JavaRDD<String> coalesceRDD = rdd2.coalesce(2, true);//产生shuffle
代码结果:
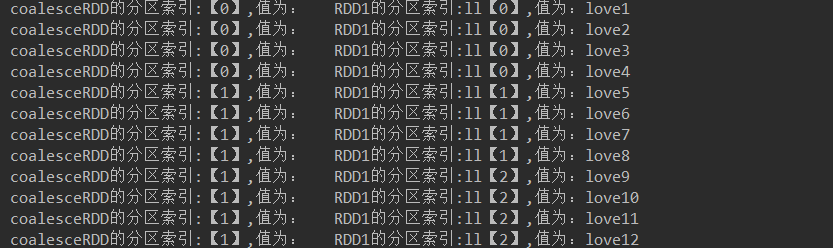
JavaRDD<String> coalesceRDD = rdd2.coalesce(2, false);//不产生shuffle
代码解释:
代码结果:
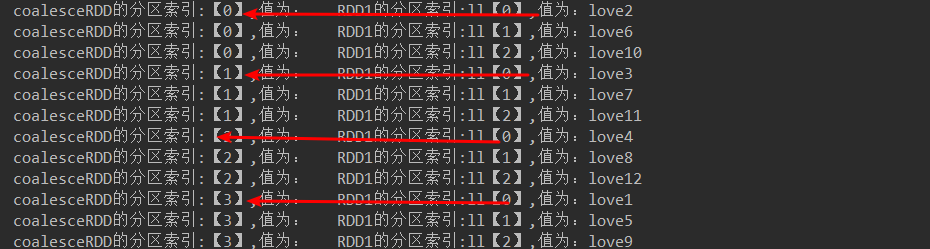
JavaRDD<String> coalesceRDD = rdd2.coalesce(4,false);//设置分区数大于原RDD的分区数且不产生shuffle,不起作用
代码结果:
JavaRDD<String> coalesceRDD = rdd2.coalesce(4,true);//设置分区数大于原RDD的分区数且产生shuffle,相当于repartition
代码结果:
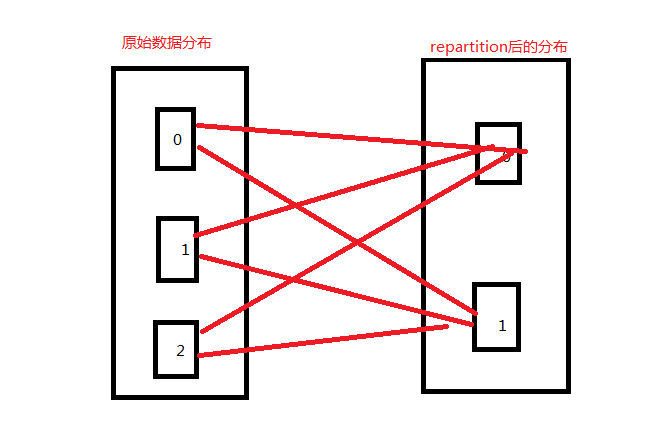
- repartition
增加或减少分区。会产生shuffle。(多个分区分到一个分区不会产生shuffle)
java代码
package com.spark.spark.transformations; import java.util.ArrayList; import java.util.Arrays; import java.util.Iterator; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function2; /** * repartition * 减少或者增多分区,会产生shuffle.(多个分区分到一个分区中不会产生shuffle) * @author root * */ public class Operator_repartition { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("coalesce"); JavaSparkContext sc = new JavaSparkContext(conf); List<String> list = Arrays.asList( "love1","love2","love3", "love4","love5","love6", "love7","love8","love9", "love10","love11","love12" ); JavaRDD<String> rdd1 = sc.parallelize(list,3); JavaRDD<String> rdd2 = rdd1.mapPartitionsWithIndex( new Function2<Integer, Iterator<String>, Iterator<String>>(){ /** * */ private static final long serialVersionUID = 1L; @Override public Iterator<String> call(Integer partitionId, Iterator<String> iter) throws Exception { List<String> list = new ArrayList<String>(); while(iter.hasNext()){ list.add("RDD1的分区索引:【"+partitionId+"】,值为:"+iter.next()); } return list.iterator(); } }, true); // JavaRDD<String> repartitionRDD = rdd2.repartition(1); JavaRDD<String> repartitionRDD = rdd2.repartition(2); // JavaRDD<String> repartitionRDD = rdd2.repartition(6); JavaRDD<String> result = repartitionRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>(){ /** * */ private static final long serialVersionUID = 1L; @Override public Iterator<String> call(Integer partitionId, Iterator<String> iter) throws Exception { List<String> list = new ArrayList<String>(); while(iter.hasNext()){ list.add("repartitionRDD的分区索引:【"+partitionId+"】,值为: "+iter.next()); } return list.iterator(); } }, true); for(String s: result.collect()){ System.out.println(s); } sc.stop(); } }
scala代码:
package com.bjsxt.spark.transformations
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ListBuffer
object Operator_repartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("repartition")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(1,2,3,4,5,6,7),3)
val rdd2 = rdd1.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = new ListBuffer[String]()
while(iter.hasNext){
list += "rdd1partitionIndex : "+partitionIndex+",value :"+iter.next()
}
list.iterator
})
rdd2.foreach{ println }
val rdd3 = rdd2.repartition(4)
val result = rdd3.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = ListBuffer[String]()
while(iter.hasNext){
list +=("repartitionIndex : "+partitionIndex+",value :"+iter.next())
}
list.iterator
})
result.foreach{ println}
sc.stop()
}
}
代码解释:
JavaRDD<String> repartitionRDD = rdd2.repartition(2);
代码结果:
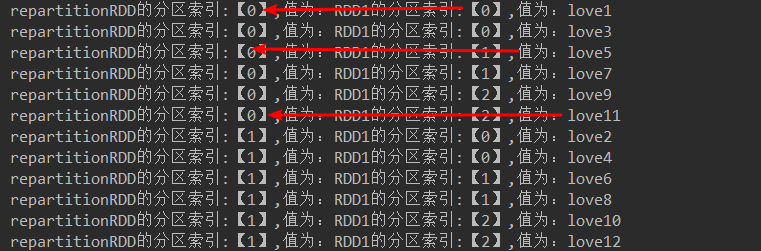
JavaRDD<String> repartitionRDD = rdd2.repartition(1);//不产生shuffle
代码结果:
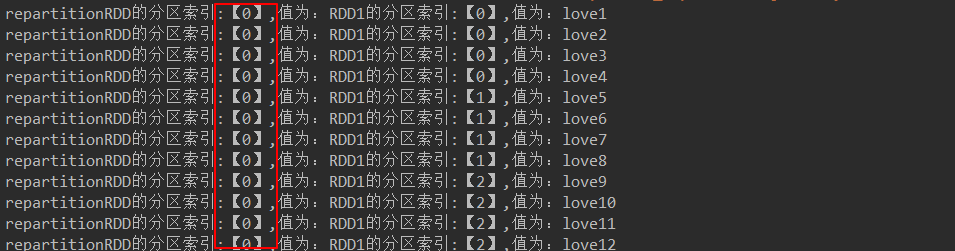
- groupByKey(是一个transformation算子注意和reducebykey区分)
作用在K,V格式的RDD上。根据Key进行分组。作用在(K,V),返回(K,Iterable <V>)。
java代码:
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class Operator_groupByKey { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("groupByKey"); JavaSparkContext sc = new JavaSparkContext(conf); JavaPairRDD<String, Integer> parallelizePairs = sc.parallelizePairs(Arrays.asList( new Tuple2<String,Integer>("a", 1), new Tuple2<String,Integer>("a", 2), new Tuple2<String,Integer>("b", 3), new Tuple2<String,Integer>("c", 4), new Tuple2<String,Integer>("d", 5), new Tuple2<String,Integer>("d", 6) )); JavaPairRDD<String, Iterable<Integer>> groupByKey = parallelizePairs.groupByKey(); groupByKey.foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Iterable<Integer>> t) throws Exception { System.out.println(t); } }); } }
scala代码:
package com.bjsxt.spark.transformations
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object Operator_groupByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("groupByKey")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(Array(
(1,"a"),
(1,"b"),
(2,"c"),
(3,"d")
))
val result = rdd1.groupByKey()
result.foreach(println)
sc.stop()
}
}
代码结果:

- zip
将两个RDD中的元素(KV格式/非KV格式)变成一个KV格式的RDD,两个RDD的个数必须相同。
java代码:
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class Operator_zip { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("zip"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> nameRDD = sc.parallelize(Arrays.asList("zhangsan","lisi","wangwu")); JavaRDD<Integer> scoreRDD = sc.parallelize(Arrays.asList(100,200,300)); // JavaRDD<Integer> scoreRDD = sc.parallelize(Arrays.asList(100,200,300,400)); JavaPairRDD<String, Integer> zip = nameRDD.zip(scoreRDD); zip.foreach(new VoidFunction<Tuple2<String,Integer>>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Integer> tuple) throws Exception { System.out.println("tuple --- " + tuple); } }); // JavaPairRDD<String, String> parallelizePairs = sc.parallelizePairs(Arrays.asList( // new Tuple2<String, String >("a","aaa"), // new Tuple2<String, String >("b","bbb"), // new Tuple2<String, String >("c","ccc") // )); // JavaPairRDD<String, String> parallelizePairs1 = sc.parallelizePairs(Arrays.asList( // new Tuple2<String, String >("1","111"), // new Tuple2<String, String >("2","222"), // new Tuple2<String, String >("3","333") // )); // JavaPairRDD<Tuple2<String, String>, Tuple2<String, String>> result = parallelizePairs.zip(parallelizePairs1); sc.stop(); } }
scala代码:
package com.bjsxt.spark.transformations
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* 将两个RDD中的元素(KV格式/非KV格式)变成一个KV格式的RDD,两个RDD的个数必须相同。
*/
object Operator_zip {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("zip").setMaster("local")
val sc = new SparkContext(conf)
val nameRDD = sc.makeRDD(Array("zhangsan","lisi","wangwu"))
val scoreRDD = sc.parallelize(Array(1,2,3))
val result = nameRDD.zip(scoreRDD)
result.foreach(println)
sc.stop()
}
}
结果:

- zipWithIndex
该函数将RDD中的元素和这个元素在RDD中的索引号(从0开始)组合成(K,V)对。
java代码:
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; /** * zipWithIndex 会将RDD中的元素和这个元素在RDD中的索引号(从0开始) 组合成(K,V)对 * @author root * */ public class Operator_zipWithIndex { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("zipWithIndex"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> nameRDD = sc.parallelize(Arrays.asList("zhangsan","lisi","wangwu")); JavaPairRDD<String, Long> zipWithIndex = nameRDD.zipWithIndex(); zipWithIndex.foreach(new VoidFunction<Tuple2<String,Long>>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Long> t) throws Exception { System.out.println("t ---- "+ t); } }); // JavaPairRDD<String, String> parallelizePairs = sc.parallelizePairs(Arrays.asList( // new Tuple2<String, String >("a","aaa"), // new Tuple2<String, String >("b","bbb"), // new Tuple2<String, String >("c","ccc") // )); // JavaPairRDD<Tuple2<String, String>, Long> zipWithIndex2 = parallelizePairs.zipWithIndex(); // zipWithIndex2.foreach(new VoidFunction<Tuple2<Tuple2<String,String>,Long>>() { // // /** // * // */ // private static final long serialVersionUID = 1L; // // @Override // public void call(Tuple2<Tuple2<String, String>, Long> t) // throws Exception { // System.out.println(" t ----" + t); // } // }); sc.stop(); } }
scala代码:
package com.bjsxt.spark.transformations
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* 该函数将RDD中的元素和这个元素在RDD中的索引号(从0开始)组合成(K,V)对
*/
object zipWithIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("zipWithIndex")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c")))
val result = rdd1.zipWithIndex()
result.foreach(println)
sc.stop()
}
}
代码结果:
java结果:

scala结果:
