一、前述
SparkStreaming是流式处理框架,是Spark API的扩展,支持可扩展、高吞吐量、容错的实时数据流处理,实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。例如:map,reduce,join,window 。最终,处理后的数据可以存放在文件系统,数据库等,方便实时展现。
二、SparkStreaming与Storm的区别
1、Storm是纯实时的流式处理框架,SparkStreaming是准实时的处理框架(微批处理)。因为微批处理,SparkStreaming的吞吐量比Storm要高。
2、Storm 的事务机制要比SparkStreaming的要完善。
3、Storm支持动态资源调度。(spark1.2开始和之后也支持)
4、SparkStreaming擅长复杂的业务处理,Storm不擅长复杂的业务处理,擅长简单的汇总型计算。
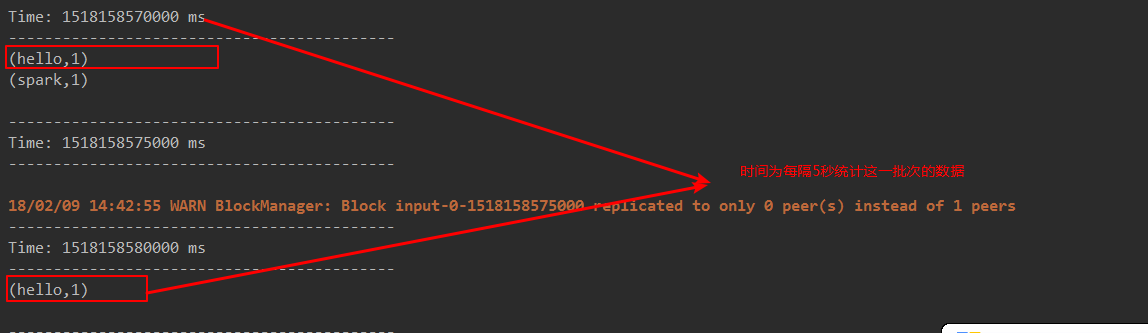
三、Spark初始

- receiver task是7*24小时一直在执行,一直接受数据,将一段时间内接收来的数据保存到batch中。假设batchInterval为5s,那么会将接收来的数据每隔5秒封装到一个batch中,batch没有分布式计算特性,这一个batch的数据又被封装到一个RDD中,RDD最终封装到一个DStream中。
例如:假设batchInterval为5秒,每隔5秒通过SparkStreamin将得到一个DStream,在第6秒的时候计算这5秒的数据,假设执行任务的时间是3秒,那么第6~9秒一边在接收数据,一边在计算任务,9~10秒只是在接收数据。然后在第11秒的时候重复上面的操作。
- 如果job执行的时间大于batchInterval会有什么样的问题?
如果接受过来的数据设置的级别是仅内存,接收来的数据会越堆积越多,最后可能会导致OOM(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟 )。
四、SparkStreaming代码
代码注意事项:
- 启动socket server 服务器:nc –lk 9999
- receiver模式下接受数据,local的模拟线程必须大于等于2,一个线程用来receiver用来接受数据,另一个线程用来执行job。
- Durations时间设置就是我们能接收的延迟度。这个需要根据集群的资源情况以及任务的执行情况来调节。
- 创建JavaStreamingContext有两种方式(SparkConf,SparkContext)
- 所有的代码逻辑完成后要有一个output operation类算子触发执行。
- JavaStreamingContext.start() Streaming框架启动后不能再次添加业务逻辑。
- JavaStreamingContext.stop() 无参的stop方法将SparkContext一同关闭,stop(false),不会关闭SparkContext,方便后面使用
- JavaStreamingContext.stop()停止之后不能再调用start。
package com.spark.sparkstreaming; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; /** * 1、local的模拟线程数必须大于等于2 因为一条线程被receiver(接受数据的线程)占用,另外一个线程是job执行 * 2、Durations时间的设置,就是我们能接受的延迟度,这个我们需要根据集群的资源情况以及监控每一个job的执行时间来调节出最佳时间。 * 3、 创建JavaStreamingContext有两种方式 (sparkconf、sparkcontext) * 4、业务逻辑完成后,需要有一个output operator * 5、JavaStreamingContext.start()straming框架启动之后是不能在次添加业务逻辑 * 6、JavaStreamingContext.stop()无参的stop方法会将sparkContext一同关闭,stop(false) ,默认为true,会一同关闭 * 7、JavaStreamingContext.stop()停止之后是不能在调用start */ /** * foreachRDD 算子注意: * 1.foreachRDD是DStream中output operator类算子 * 2.foreachRDD可以遍历得到DStream中的RDD,可以在这个算子内对RDD使用RDD的Transformation类算子进行转化,但是一定要使用rdd的Action类算子触发执行。 * 3.foreachRDD可以得到DStream中的RDD,在这个算子内,RDD算子外执行的代码是在Driver端执行的,RDD算子内的代码是在Executor中执行。 * */ public class WordCountOnline { @SuppressWarnings("deprecation") public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline"); /** * 在创建streaminContext的时候 设置batch Interval */ JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); // JavaSparkContext sc = new JavaSparkContext(conf); // JavaStreamingContext jsc = new JavaStreamingContext(sc,Durations.seconds(5));//两种办法得到StreamingContext // JavaSparkContext sparkContext = jsc.sparkContext(); JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node04", 9999);//监控socket端口9999 JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { /** * */ private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String s) { return Arrays.asList(s.split(" ")); } }); JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Integer call(Integer i1, Integer i2) { return i1 + i2; } }); //outputoperator类的算子 counts.print(); /*counts.foreachRDD(new VoidFunction<JavaPairRDD<String,Integer>>() { *//** * 这里写的代码是在Driver端执行的 *//* private static final long serialVersionUID = 1L; @Override public void call(JavaPairRDD<String, Integer> pairRDD) throws Exception { pairRDD.foreach(new VoidFunction<Tuple2<String,Integer>>() { *//** * *//* private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Integer> tuple) throws Exception { System.out.println("tuple ---- "+tuple ); } }); } });*/ jsc.start(); //等待spark程序被终止 jsc.awaitTermination(); jsc.stop(false); } }
scala代码:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Durations
object Operator_foreachRDD {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[2]").setAppName("foreachRDD")
val sc = new SparkContext(conf)
val jsc = new StreamingContext(sc,Durations.seconds(5))
val socketDStream = jsc.socketTextStream("node5", 9999)
socketDStream.foreachRDD { rdd => {
rdd.foreach { elem => {
println(elem)
} }
}}
jsc.start()
jsc.awaitTermination()
jsc.stop(false)
}
}