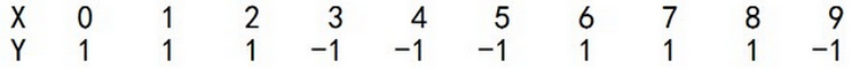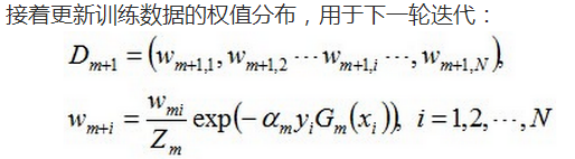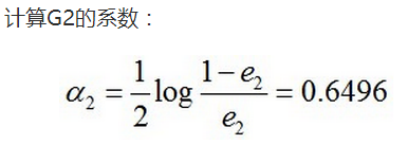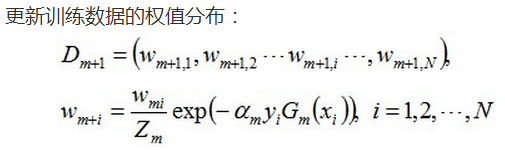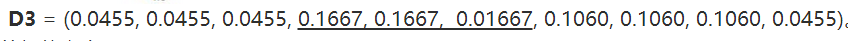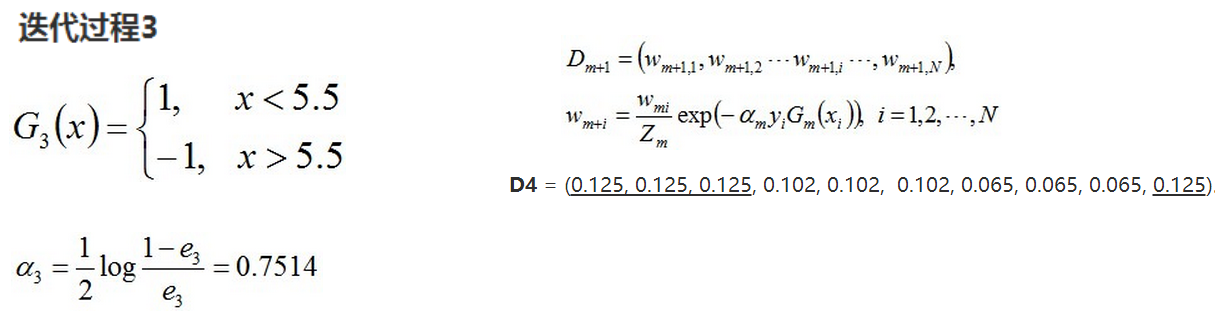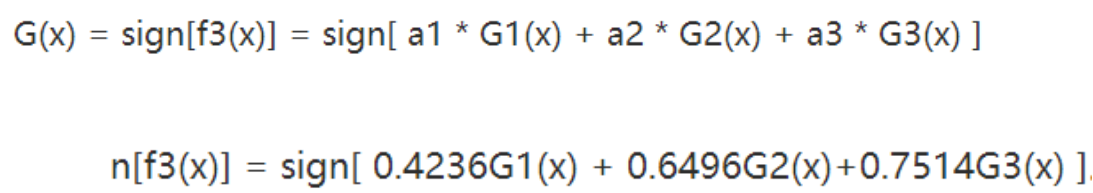一、前述
AdaBoost算法和GBDT(Gradient Boost Decision Tree,梯度提升决策树)算法是基于Boosting思想的机器学习算法。在Boosting思想中是通过对样本进行不同的赋值,对错误学习的样本的权重设置的较大,这样,在后续的学习中集中处理难学的样本,最终得到一系列的预测结果,每个预测结果有一个权重,较大的权重表示该预测效果较好。
二、具体原理
AdaBoost,是英文"Adaptive Boosting"(自适应増强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。它的自适应在于:前一个基本分器分错的样本会得到加强,加权后的全体样本再次被用来训练、下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
1、算法过程
1. 初始化训练数据的权值分布。如果有 N 个样本,则每一个训练样本最开始时都被赋予相同的权重:1/ N
2. 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。然后,权重更新过的样本集被用于训练下一个类器,整个训练过程如此迭代地进行下去。
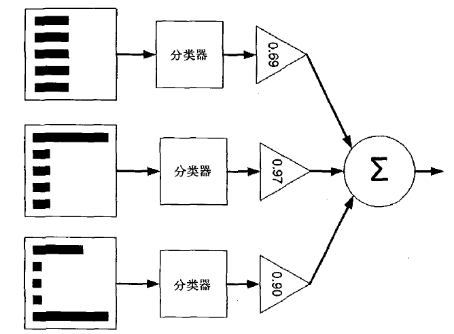
3. 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
2、具体过程
给定一个训练数据集 T ={( x 1, y 1), ( x 2, y 2)...( xN , yN )},其中实例 ;r e 义, yi 属于标记集合{-1, + 1}, Adaboost 的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后从这些弱分类器组合成一个强分类器。
Adaboost 的算法流程如下:



三、案例分析