5.对抗防御
通常包括对抗训练、基于随机的方案、去噪方法、可证明防御以及一些其他方法。
5.1对抗训练
对抗训练:通过与对抗样本一起训练,来尝试提高神经网络的鲁棒性。
通常情况下,可视为如下定义的最大最小游戏:
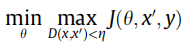
其中,![]() 代表对抗代价,θ代表网络权重,x‘代表对抗输入,y代表真相标签。D(x,x')代表x和x'之间的距离指标。内部的max函数是为了找到最有效的对抗样本,外部的最小化函数是使损失最小化的标准训练程序。
代表对抗代价,θ代表网络权重,x‘代表对抗输入,y代表真相标签。D(x,x')代表x和x'之间的距离指标。内部的max函数是为了找到最有效的对抗样本,外部的最小化函数是使损失最小化的标准训练程序。
5.1.1 FGSM 对抗训练
Goodfellow等人是最早提出通过用良性和FGSM生成的对抗样本训练神经网络来增强神经网络的鲁棒性。训练目标可正式表述如下:

其中
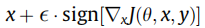
是通过FGSM为良性样本产生的对抗样本,c用于平衡作为超级参数的良性和对抗性样本的准确性。
然而,尽管训练过的模型在防御FGSM生成的对抗性样本时很有效,但仍然容易受到基于迭代优化的对抗攻击。
5.1.2 PGD对抗训练
PGD训练模型都能提高CNNs和ResNets在对抗几种典型的一阶L∞攻击的鲁棒性,比如说FGSM,PGD和CW∞在白盒和黑盒下的攻击。但是,计算代价太大了。
5.1.3 集合对抗训练EAT
为了避免PGD带来的巨大的计算代价和无法抵御黑盒攻击的弊端,提出了一种包含多个从预先训练的模型中转移过来的对抗性样本的训练模型,即整体对抗训练。整体对抗训练增加了用于对抗训练的对抗性样本的多样性,因此增强了网络抵抗来自其他模型的对抗性样本的鲁棒性。在某些情况下,EAT对抗黑盒和灰盒攻击的表现比PGD对抗训练更好。
5.1.4 对抗性logit配对 ALP
ALP通过将良性样本x的对数与对应的扰动样本x'的对数之间的交叉熵包括在训练损失中来鼓励学习对数空间中的成对示例之间的相似性。训练损失定义如下:
![]()
即原始损失加x和x'对数之间的交叉熵乘以一个超参数。
ALP下降损失仅仅围绕输入点,但是在用于ResNet的时候准确率非常低,并且不太适合梯度下降。
5.1.5 生成对抗训练
前文所提对抗训练政策均采用确定性攻击算法来产生训练样本。生成对抗训练采用非确定性攻击算法。
5.2 随机性
DNN总是对随机干扰具有鲁棒性,基于随机化的防御试图将对抗性影响随机化为大多数DNN不关心的随机性影响。基于随机性的防御在黑盒和灰盒设定下有很好的效果,但是对白盒攻击效果不好。
5.2.1 随机输入变换
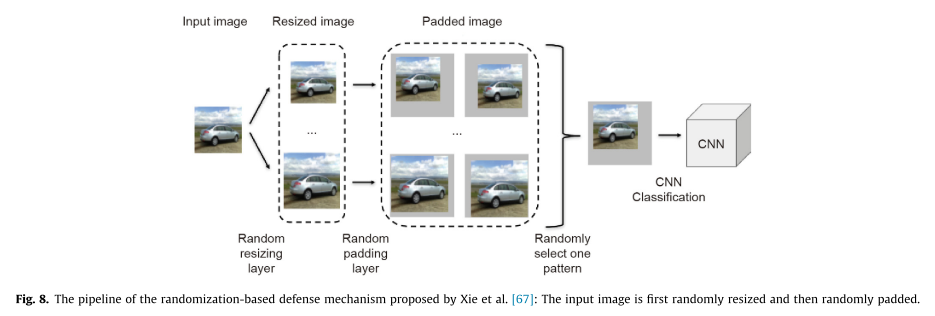
随机调整大小和填补。
随机调整大小指在将图片输送给DNNs之前,调整输出图片为随机尺寸。随机填补是指在输入图像周围随机填充0。在黑盒攻击下表现良好,然而在白盒攻击下不行。
5.2.2 随机噪声
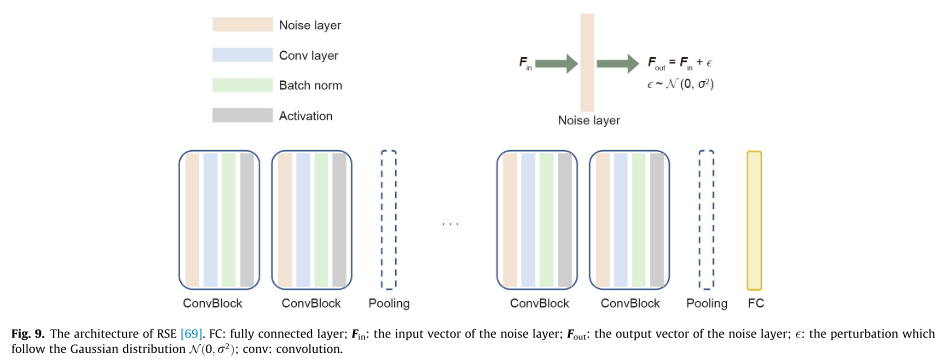
RSE指一种通过随机噪声抵御对抗干扰的方法,它在训练和测试阶段,在每个卷积层之前添加一个噪声层,并针对随机噪声汇总预测结果,以稳定DNN的输出,其工作原理如下:
PixelDP是从差分隐私的角度来看随机噪声防御机制的,它在DNN内集成了一个DP噪声层,以通过基于翻书的小扰动对输入的预测,对分布的变化强制制定DP边界。
5.2.3 随机特征修剪
SAP通过随机修剪每一层中的一部分activation(激活?)来保护预训练网络免受对抗性样本的攻击并且优先保留较大幅度的激活。
另一种方法随机遮罩卷积层输出的特征地图,因此每个过滤器仅从部分位置提取要素。
5.3 去噪
就减轻对抗性干扰影响而言,降噪是一种非常简单的方法。之前有两个方向:输入去噪和特征去噪。输入去噪试图从输入中部分或全部消除对抗性扰动,特征去噪试图减轻对抗性干扰对DNN学习的高级功能的影响。
5.3.1 常规输入整流
Xu等人提出了两种去噪方法:位减少和图像模糊,以减少自由度并消除对抗性扰动。通过比较原始图像和压缩图像上的模型预测来实现横向样本检测,如果原始输入和压缩后的输入与模型产生的输出实质上不同,则原始输入可能是对抗样本。然而特征压缩仍然容易受到具有适应能力的知识型对手的攻击。
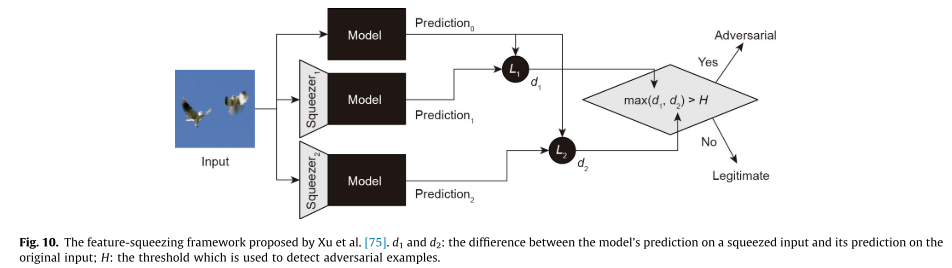
5.3.2 基于GAN的输入清理
GAN是学习生成数据分布模型的强大工具。Defense-GAN和APE-GAN(adversarial perturbation elimination GAN)是利用GAN来学习良性数据分配,以便生成对抗性输入的良性预测的主要算法。
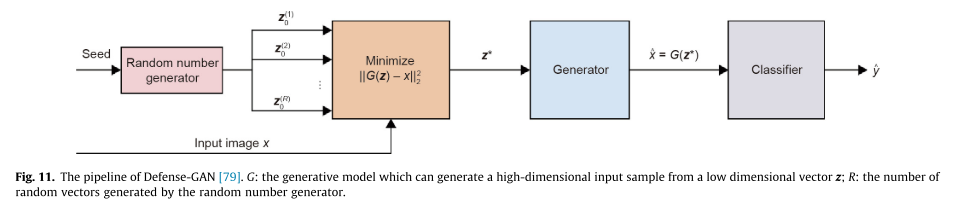
在测试阶段,Defense-GAN通过在其学习的分布中搜索接近对抗输入的图像来清除对抗输入,并且将此良性图像输入分类器。此策略可用于防御各种对抗攻击,目前针对Defense-GAN的最有效的攻击方案是基于反向传递可微近似的。其原理如下:
APE-GAN直接学习生成器,将其用作输入来清除对抗性样本,并输出良性副本。无法抵御白盒CW2攻击。
5.3.3 基于自动编码器的输入去噪
MagNet包括一个检测器和一个重整器,使用自动编码器来学习良性样本的多种形式。对黑盒和灰盒有效,对白盒效果不好。
5.3.4 特征降噪
HGD(high-level representation guided denoiser 高阶表示引导去噪器)不在像素层面,而是利用特征级损失函数来最大程度地减小良性和对抗性样本之间的特征级差异,对抗黑盒攻击效果好。
5.4 可证明的防御
以上防御均为启发式防御,这意味着这些防御措施的有效性只能通过实验验证,而不能在理论上得到证明。