redis
1 NoSQL技术简介
- Schemaless (弱结构)
- In-Memory (基于内存)
- 弱化事务
- 适用于Cluster(集群)环境
- 没有复杂的连接查询操作
- 脚本语言支持
市场上流行的nosql 产品如下

- Cassandra: 基于图片存储
- Hbase:基于列存储
- mongoDB:基于文档存储
- CouchDB:基于文档存储
- Riak:基于键值存储
- Redis:基于键值存储
1 Redis 简介
1.1 Redis是什么?
Redis是用C 语言开发的、一个开源、支持网络、基于内存、键值对型的NOSQL数据库。
参考学习网站:http://www.runoob.com/redis/redis-tutorial.html
2.2 Redis的特点
- Redis是一个高性能的Key/VaIue数据库
- 基于内存
- 数据类型丰富(stringlistsetsortsethash)
- 持久化
- 单线程
- 订阅/发布模型
2.3 Redis与Memcached对比
- Redis不仅仅支持简单的k/v类型的数据,同时还提供list, set, hash等数据结构存储
- Redis支持数据的主从复制,即master-slave模式的数据备份;
- Redis支持数据的持久化,可以将内存中的数据保存到磁盘中,重启的时候可以再次加载原有数据;
- Redis单个value的最大限制是1 GB, memcached只能保存1MB的数据
2.4 技术架构
2.4.1 传统的架构
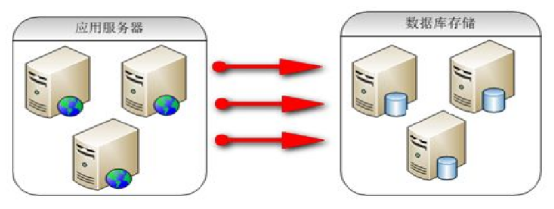
2.4.2 Redis 存储非关系型数据架构
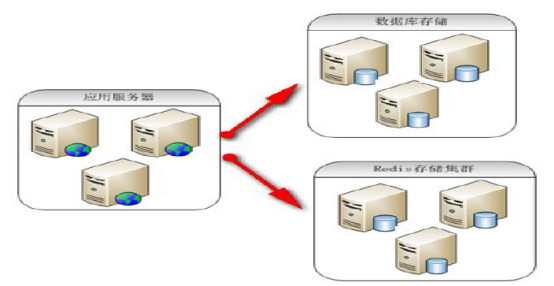
2.4.3 Redis 充当缓存服务器架构

3 Redis 的安装
3.1 环境准备
- VMWare(虚拟机)
- CentOS7
- Gcc(编译器)
- WinSCP/filezilla FTP/ssh
- redis-4.0.1.tar.gz (安装包)
3.2 安装步骤
1)安装redis编译的c环境,yum install gcc-c++
2)将redis-4.0.1.tar.gz上传到Linux系统中
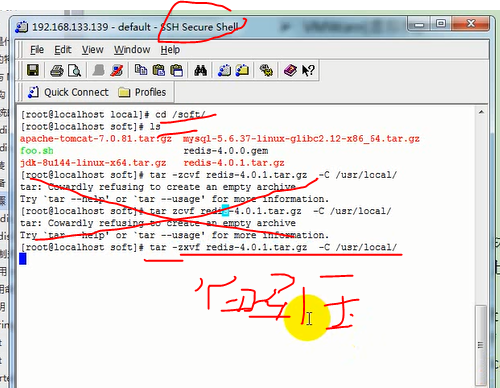
3)解压到/usr/local下 tar -xvf redis-4.0.1.tar.gz -C /usr/local
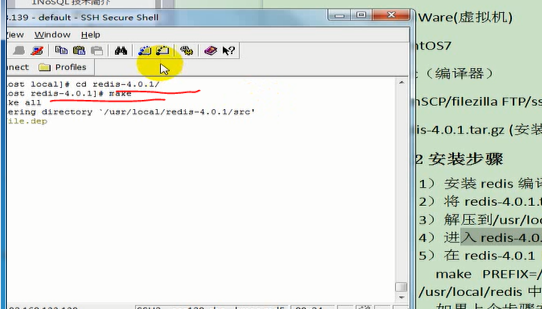
4)进入redis-4.0.1目录 使用make命令编译redis
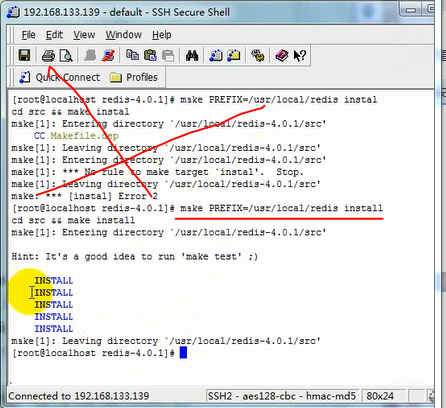
5)在redis-4.0.1目录中 使用make PREFIX=/usr/local/redis install命令安装redis到/usr/local/redis中如果上个步骤安装失败执行make MALLOC=libc
6)拷贝redis-4.0.1中的redis.conf到安装目录redis/bin中
7)设置redis.conf,即设置redis 的启动方式,让它在后台启动

说明;如果不在后台启动,则当前窗口如果关闭则redis 服务也会关闭,所以要使用后台启动。
3.3 启动 redis服务
1) 启动redis ,在bin下执行命令./redis-server redis.conf
2)使用命令查看6379端口是否启动,6379端口是redsi默认端口ps -ef | grep redis 或通过 查询redis 的运行的端口号ps -aux |grep redis

3.4 关闭redis服务
3.4..1 强制关闭 (可能导致持久化数据丢失) Kill -9 pid
3.4.2 使用redis客户端关闭
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
安装过程演示:
1 安装redis编译的c环境,yum install gcc-c++ 在连接网络情况下输入命令自动下载
2将redis-4.0.1.tar.gz上传到Linux系统中
3解压到/usr/local下 tar -xvf redis-4.0.1.tar.gz -C /usr/local
4进入redis-4.0.1目录 使用make命令编译redis
5)在redis-4.0.1目录中 使用make PREFIX=/usr/local/redis install命令安装redis到/usr/local/redis中如果上个步骤安装失败执行make MALLOC=libc
6拷贝redis-4.0.1中的redis.conf到安装目录redis/bin中
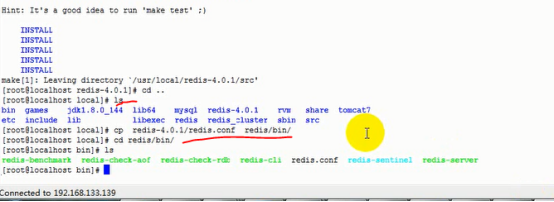
7设置redis.conf,即设置redis 的启动方式,让它在后台启动
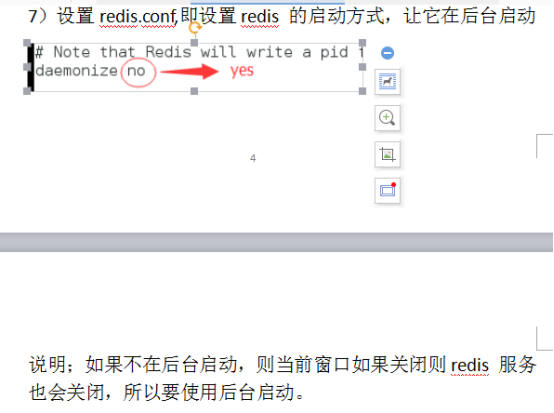
直接启动:不能继续输入命令
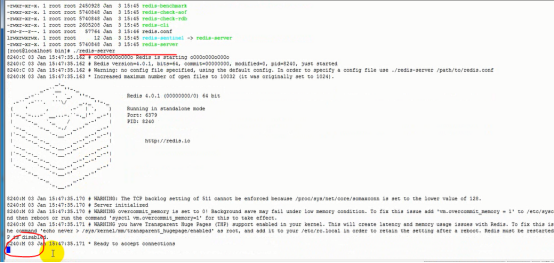
使用后台打开设置 vim

找到该位置 输入i修改

按配置启动
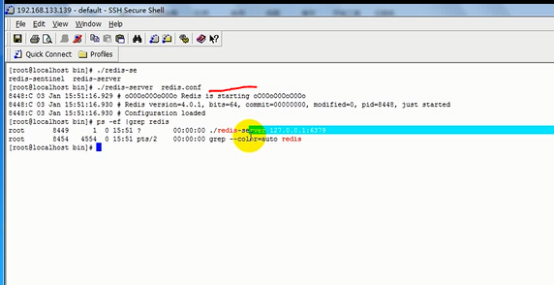
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
=======================================================================================================================================================
=======================================================================================================================================================
4 Redis 的常用命令
4.1 简要说明
redis是一种高级的key-value的存储系统
其中的key是字符串类型,尽可能满足如下几点:
1)key不要太长,最好不要超过1024个字节,否则这不仅会消耗内存还会降低查找效率
2)key不要太短,如果太短会降低key的可读性
3)在项目中,key最好有一个统一的命名规范(根据企业的需求)
其中value 支持五种数据类型
1)字符串型 string
2)字符串列表 list
3)字符串集合 set
4)有序字符串集合 sorted set
5)哈希类型 hash
4.1 存储String
|
命令 |
说明 |
示例 |
|
set |
设置一个key/value |
set name lucy |
|
get |
根据key获取对应的 value |
get name |
|
mset |
一次设置多个key value |
met name lucy age 12 |
|
mget |
一次获取多个key 的value |
mget name age |
|
getset |
获取原始 key的值,同时设置新值 |
getset name john |
|
strlen |
获取key 的value的长度 |
Strlen name |
|
append |
为对应key的value 追加内容 |
Append name love |
|
getrange |
截取value的内容 |
Getrange name 0 3 |
|
setex |
设置key存活的时间(秒) |
Setex name 3 lucy |
|
psetex |
设置key存活的时间(毫秒) |
|
|
setnx |
只有当key不存在时再等效set |
|
|
msetnx |
同时设置多个key |
|
|
decr |
进行数值类型的-1 操作 |
decr age |
|
decrby |
根据提供的数据继续减法操作 |
|
|
lncr |
进行数值类型的+1 操作 |
|
|
lncrby |
根据提供的数据继续加法操作 |
|
|
lncrbyfloat |
根据提供的数据加入浮点数 |
incrbyfloat age 1.5 |
Flushall : 清空所有的键 keys * : 列出所有的 key的值
4.3 存储list(链表)
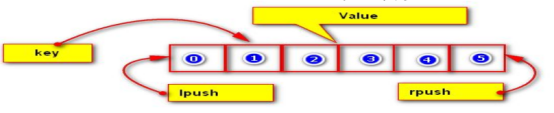
在Redis中,List类型是按照插入顺序排序的字符串链表。和数据结构中的普通链表一样,我们可以在其头部(Ieft)和尾部(right)添加新的元素。在插入时,如果该键并不存在,Redis将为该键创建
一个新的链表。如果链表中所有的元素均被移除,那么该键也将会被从数据库中删除。
List中可以包含的最大元素数量是42949672950, 从元素插入和删除的效率来看,如果我们是在链表的两头插入或删除元素,这将会是非常高效的操作,即使链表中己经存储了百万条记录,该操作也可以在常量时间内完成。然而需要说明的是,如果元素插入或删除操作是作用于链表中间,那将会是非常低效的。
|
命令 |
说明 |
示例 |
|
lpush |
从左侧加入值到key列表 |
Lpush list a |
|
lpushx |
同lpush但必须保证key存在 |
Lpushx list a |
|
rpush |
从右侧加入值到key列表 |
|
|
rpushx |
同rpush但必须保证key存在 |
|
|
lpop |
从左侧返回和移除第一个元素 |
Lpop list |
|
rpop |
从右侧返回和移除第一个元素 |
|
|
lrang |
获取某一个下标区间的元素 |
Lrange 0 2 lrang 0 -1 表示全部显示 |
|
llen |
获取列表元素个数 |
|
|
lset |
设置某一个下标的元素(覆盖原有元素) |
|
|
lrem |
删除重复的元素 |
Lrem list 2 m表示删除2个list中重复元素 m |
|
ltrim |
只保留指定区间内的元素,不在指定区间之内的元素都将被删除 |
Ltrim list 2 5 |
|
linsert |
在列表的元素前或者后插入元素 |
Linsert list before b a |
|
rpoplpush |
将链表中的尾部元素弹出并添加到头部 |
Rpoplpush list |
Rpoplpush 使用场景
Redis链表经常会被用于消息队列的服务,以完成多程序之间的消息交换。假设一个应用程序正在执行LPUSH操作向链表中添加新的元素,我们通常将这样的程序称之为”生产者(Producer)",而另外一个应用程序正在执行RPOP操作从链表中取出元素,我们称这样的程序为”消费者(Consumer)",如果此时,消费者程序在取出消息元素后立刻崩溃,由于该消息已经被取出且没有被正常处理,那么我们就可以认为该消息己经丢失,由此可能会导致业务数据丢失,或业务状态的不一致等现象的发生。然而通过使用RPOPLPUSH命令,消费者程序在从主消息队列中取出消息之后再将其插入到备份队列中直到消费者程序完成正常的处理逻辑后再将该消息从备份队列中删除。同时我们还可以提供一个守护进程,当发现备份队列中的消息过期时,可以重新将其再放回到主消息队列中,以便其它的消费者程序继续处理。
4.4 存储set
在Redis中,我们可以将Set类型看作为没有排序的字符集合,和List类型一样,我们也可以在该类型的数据值上执行添加、删除或判断某一元素是否存在等操作。和List类型不同的是,Set集介中不允许重复。换句话说,如果多次添加相同元素,Set中将仅保留该元素的一份拷贝。和List类型相比,Set类型在功能上还存在着一个非常重要的特性,即在服务器端完成多个Sets之间的聚合计算操作,如。Unions(并集), intersection(交集)和differences(差集)。由于这些操作均在服务端完成,因此效率极高,而且也节省了大量的网络10开销。
- sadd key values[valuel, value2...]:向set中添加数据,如果该key的值己有则不会重复添加
- srem key members[memberl, member2...]:删除:指定的成员
- 获得集合中的元素
n smembers key:获取set中所有的成员
n sismember key member:判断参数中指定的成员是否在该s et中,1表示存在,0表示不存在或者该key本身就不存在。(无论集合中有多少元素都可以极速的返回结果)
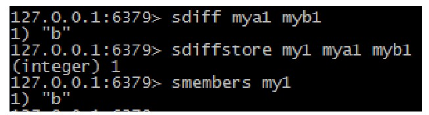
- 集合的差集运算A-B sdiff keyl key2..:返回keyl与key2中相差的成员,与key的顺序有关。即返回差集

- 集合的交集运算A n B sinter keyl key2 key3...:返A和B交集。
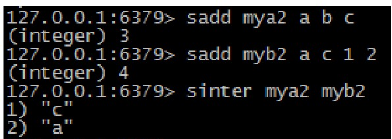
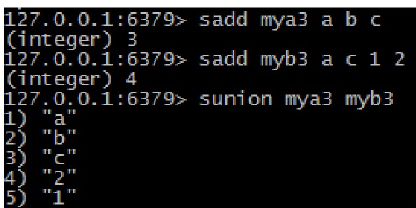
- 集合的并集运算 A U B sunion keyl key2 key3… 返回并集
- scard key:获取set中成员的数量
- SRANDMEMBER key:随机返回set中的一个成员
- sdiffstore destination keyl key2..:将key1, key2相差的成员存储在destination上
- sinterstore destination key1 key2…:将返回的交集存储在destination上

- sunionstore destination key[key二」:将返回的并集存储在destination上

4.5 存储sortedset
Sorted-Set和Set类型极为相似,它们都是字符串的集合,都不允许重复的成员出现在一个Set中。它们主要差别是Sorted-Set中的每一个成员都会有一个分数(score)与之关联,Redis正是通过分数来为集合中的成员进行从小到大的排序。然而需要额外指出的是,尽管Sorted-Set中的成员必须是唯一的,但是分数(score)却是可以重复的
在Sorted-Set中添加、删除或更新一个成员都是非常快速的操作,其时间复杂度为集合中成员数量的对数。由于Sorted-Set中的成员在集合中的位置是有序的,因此,即便是访问位于集合中部的成员也仍然是非常高效的。事实上,Redis所具有的这一特征在很多其它类型的数据库中是很难实现的,换句话说,在该点上要想达到和Red is同样的高效,在其它数据库中进行建模是非常困难的。
例如:游戏排名、微博热点话题等使用场景。
- 添加元素
zadd key score member score2 member2 ...:将所有成员以及该成员的分数存放到sorted-set中。如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前己经存在的元素。
- 获得元素
zscore key member:返回指定成员的分数 zcard key:获取集合中的成员数量
- 删除成员
zrem key member[member...]:移除集合中指定的成员,可以指定多个成员口
- 范围查找
zrange key start end [withscores]: 获取集合中脚标为start-e n d的成员,[withscores]参数表明返回的成员包含其分数。
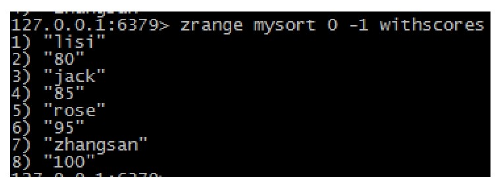
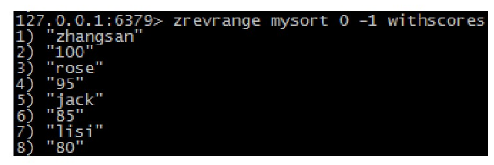
zrevrange key start stop [withscores]:按照元素分数从大到小的顺序返回索引从start到stop之间的所有元素(包含两端的元素)
- zremrangebyrank key start stop:按照排名范围删除元素

- zremrangebyscore key min max:按照分数范围删除元素

4.6 存储hash
Redis中的Hash类型可以看成具有String Key和String Value的map容器。所以该类型非常适合于存储值对象的信息。
- hset key field value:为指定的key设定field/value对(键值对)。

- hmset key fieid value [field2 value2 ...]:设置key中的多个filed/value

- hget key field:返回指定的key中的field的值

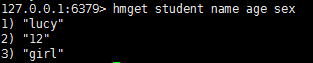
- hmget key fileds:获取key中的多个filed的值
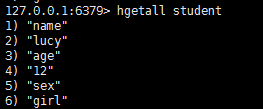
- hgetall key:获取key中的所有filed vaule
hdel key field [field ... ]:可以删除一个或多个字段,返回值是被删除的字段个数
- del key:删除整个list
- hincrby key field increment:设置key中filed的值增加i ncrement

- hexists key field:判断指定的key中的filed是否存在
- hlen key:获取key所包含的field的数量
- hkeys key:获得所有的key
- hvals key:获得所有的value
=======================================================================================================================================================
=======================================================================================================================================================
5 Redis 特性
5.1 多数据库
一个Redis:实例可以包括多个数据库,客户端可以指定连接某个redis实例的哪个数据库,就好比一个mysql中创建多个数据库,客户端连接时指定连接哪个数据库。
一个redis实例最多可提供16个数据库,下标从0到15,客户端默认连接第0号数据库,也可以通过select选择连接哪个数据库
- 默认数据库下内容为

- 选择1号数据库,并查看库中的内容

- 把0号数据的某个key转移到1 号数据中

5.2 其他命令
- ping 测试连接是否存活
 表示连接可用
表示连接可用
- dbsize 表示当前数据库中key的数量
- flushdb 删除当前数据库中所有的key
- type key:返回key的类型
5.3订阅与发布
- subscribe channel:订阅频道
- subscribe channel*:批量订阅频道,例:subscribe s*,订阅以s开头的频道
- publish channel content:在指定的频道中发布消息
- 取消订阅 unsubscribe [channel]
订阅示例在一个终端订阅消息
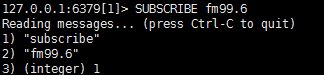
在重新打开一个终端发布消息

这时订阅终端会收到消息
5.4 Redis事务
5.4.1 简介
和其它数据库一样,Redis作为NoSQL数据库也同样提供了事务机制。在Redis中MULTI/EXEC/DISCARD/这三个命令是我们实现事务的基石。
MULTI: 开启事务
EXEC:提交事务
DISCARD:回滚事务
5.4.2 示例

5.4.3 示例3
打开一个终端
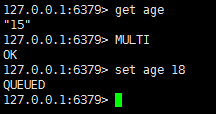
再打开一个终端

由于age 在事务中,并没有提交,所以查到的还是15
5.5 Redis 持久化
5.5.1 概念
Redis的高性能是由于其将所有数据都存储在了内存中,为了使Redis在重启之后仍能保证数据不丢失,需要将数据从内存中同步到硬盘中,这一过程就是持久化。 Redis支持两种方式的持久化,一种是RDB方式,一种是AOF方式。可以单独使用其中一种或将二者结合使用。
1) RDB持久化(默认支持,无需配置)
该机制是指在指定的时间间隔内将内存中的数据集快照写入磁盘。
2) AOF持久化
该机制将以日志的形式记录服务器所处理的每一个写操作,在Redis服务器启动之初会读取该文件来重新构建数据库,以保证启动后数据库中的数据是完整的。
3) 无持久化
我们可以通过配置的方式禁用Redis服务器的持久化功能,这样就可以将Redis视为一个功能加强版的memcached了。
4) redis可以同时使用RDB和AOF
5.5.2 使用RDB 持久化
v Snapshotting(RDB)机制的运行原理
1.Redis通过fork产生子进程;
2.父进程继续处理client请求,子进程负责将快照写入临时文件;
3.子进程写完后,用临时文件替换原来的快照文件,然后子进程退出。

- Snapshotting(RDB)机制的开发步骤
编辑redis.conf文件

v Append-Only File(AOF)机制的运行原理
1. Redis 通过fork一个子进程
2.父进程继续处理client请求,子进程把AOF内容写入缓冲区;
3.子进程写完退出,父进程接收退出消息,将缓冲区AOF写入临时文件;
4.临时文件重命名成appendonly.aof,原来文件被覆盖,整个过程完。
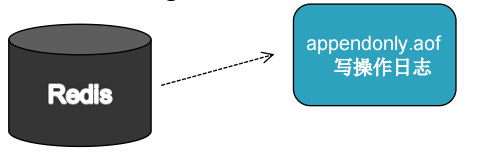
1.1.1 Append-Only File(AOF)机制的开发步骤
编辑redis.conf文件

|
持久化技术 |
优势 |
缺点 |
|
RDB |
1、RDB产生的文件小。 2、RDB恢复快,并且简单,例如你可以快 速的将RDB文件传输到其他主机,做数据的恢复。 3、在进行RDB备份的时候,主进程仅仅需 要创建一个子进程,所有的I/O操作都由子进程完成 |
1、不能完全保证数据安全,在两个备份点之间可能会发 生数据丢失 2、当数据量很大时,创建子进程可能会是一个非常耗时 的操作,甚至可能需要1秒,在这个期间,Redis无法 向客户端提供服务。 |
|
AOF |
1、数据的备份粒度更小,数据安全性更高。 2、AOF只会对日志文件进行追加操作,不 会修改已经写好的内容。即使在掉电的情况下,AOF日志仍然是可用的 |
1、AOF文件通常比相同的数据集的RDB文件更大。 2、AOF写日志可能会很慢,这跟fsync的机制有关 |
5.6集群环境下的Session管理
在下图中,如果一台服务器对外提供服务,受网络和服务器内存、性能的限制,很难完成高并发的要求,所以水平扩展服务的数量,即集群,有了集群后,又引入负载均衡器,负载均衡器通过内部的算法,可以把请求均发到不同服务器,这样就可以缓解单个服务器并发的问题。但是这样会出现session 的共享问题,即如果用户登录请求的是第一个web服务器器,那么会在服务器端会创建用户的 session ,而如果接下来其他的请求有可能会被负载均衡器,把请求分配到第二个服务器,第二个服务器并没有该用的session。这样就会出现问题。
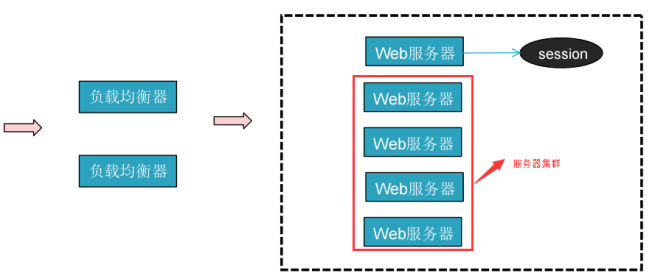
最好的解决办法如下图:

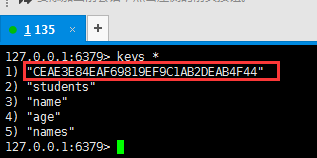
所有的session 存储在redis中,当服务器需要session时,从resdis中获取。
- 搭建步骤:
1) 在tomcat7的lib 下导入如下jar 包
注意最后一个 jar,网上下载的大部分有问题,所以本教程提供
2、在tomcat的conf/context.xml 中加入
|
<Valve className="com.radiadesign.catalina.session.RedisSessionHandlerValve" /> <Manager className="com.radiadesign.catalina.session.RedisSessionManager" host="192.168.133.135" port="6379" maxInactiveInterval="60"/> |
注意:host换成对应的IP 地址
2、测试代码示例
- 建立web工程、jsp页面,向session中存入内容
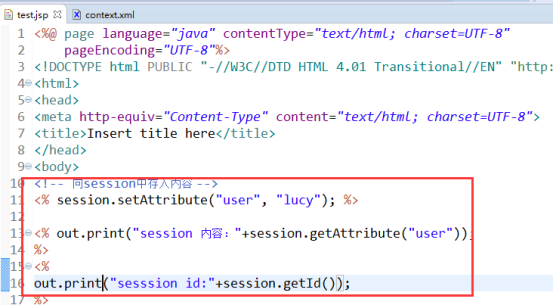
- 运行工程,访问test.jsp
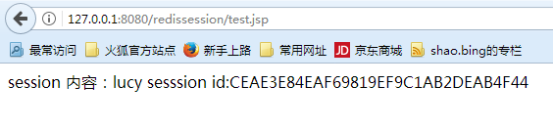
- 查看redis中的session id
6 Redis集群的搭建
6.1 redis-cluster架构图
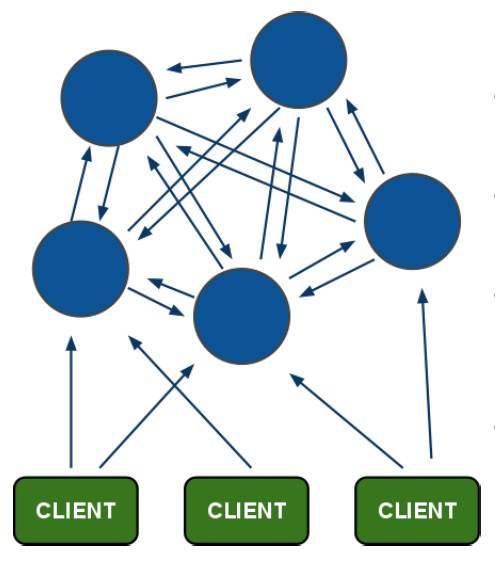
客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
6.2 redis-cluster投票:容错
解决redis的单点问题。在一个或多个节点出现宕机的情况下,集群内部通过投票的机制能够快速的进行选举和不停机的情况下进行服务持续提供
- (1)投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超时(cluster-node-timeout),则认为该当前master节点挂掉.
- (2):什么时候整个集群不可用(cluster_state:fail)?
a:如果集群任意master挂掉,且当前master没有slave.集群进入 fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态.
b:如果集群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
ps:当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
6.3 架构细节
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
6.4 Redis集群的搭建
Redis集群中至少应该有三个节点。要保证集群的高可用,需要每个节点有一个备份机。Redis集群至少需要6台服务器。
由于条件限制,这里搭建伪分布式,即使用一台虚拟机运行6个redis实例。需要修改redis的端口号7001-7006
6.4.1 创建6个redis实例
1.在usr/local/ 创建目录
mkdir redis_cluster
在redis_cluster 下创建6个目录
mkdir 7001 mkdir 7002 mkdir 7003 mkdir 7004 mkdir 7005 mkdir 7006
2.拷贝一个redis到 redis_cluster 下
cp -r redis redis_cluster/
3.配置redis.conf
vim redis.conf
1) daemonize yes
2) port 7001
3) #bind 127.0.0.1
4) cluster-enabled yes
5)protected-mode yes 改为 no
4、把配置好的redis分别拷贝到7001~7006 目录下
并修改7002~7006 的resdis.conf的port端口为目录对应的端口即7002~7006
5、启动redis
为了方便启动,创建批量启动文件 redis_startall.sh.
目录位置
内容为:
|
cd 7001/redis/bin ./redis-server redis.conf cd ../../.. cd 7002/redis/bin ./redis-server redis.conf
cd ../../.. cd 7003/redis/bin ./redis-server redis.conf cd ../../.. cd 7004/redis/bin ./redis-server redis.conf cd ../../.. cd 7005/redis/bin ./redis-server redis.conf cd ../../.. cd 7006/redis/bin ./redis-server redis.conf |
6.批量关闭redis服务
在相同的目录下创建redis_shutdown.sh

内容为:
|
cd 7001/redis/bin ./redis-cli -p 7001 shutdown cd ../../.. cd 7002/redis/bin ./redis-cli -p 7002 shutdown cd ../../.. cd 7003/redis/bin ./redis-cli -p 7003 shutdown cd ../../.. cd 7004/redis/bin ./redis-cli -p 7004 shutdown cd ../../.. cd 7005/redis/bin ./redis-cli -p 7005 shutdown cd ../../.. cd 7006/redis/bin ./redis-cli -p 7006 shutdown |
6.4.2 安装ruby环境
redis集群管理工具redis-trib.rb ,该文件在/usr/local/redis-4.0.1/src
- 复制src目录中的redis-trib.rb 到/usr/local/redis_cluster目录下
ll *.rb

要想运行redis-trib.rb 需要安装其依赖ruby环境
2安装ruby环境
yum install -y ruby
yum install -y rubygems
3安装ruby的包
通过ssh工具把redis-4.0.0.gem 上传到linux中
切换到该文件目录下 运行 gem install redis-4.0.0.gem
问题:
|
redis requires Ruby version >= 2.2.2问题 1.安装curl sudo yum install curl 2. 安装RVM gpg2 --keyserver hkp://keys.gnupg.net --recv-keys D39DC0E3 curl -L get.rvm.io | bash -s stable 3. source /usr/local/rvm/scripts/rvm 4. 查看rvm库中已知的ruby版本 rvm list known 5. 安装一个ruby版本 rvm install 2.3.3 6. 使用一个ruby版本 rvm use 2.3.3 7. 查询版本 ruby --version 8. 卸载一个已知版本 rvm remove 2.0.0 9. 再安装redis就可以了 gem install redis |
6.4.3 启动Redis
运行批量启动redis服务文件

6.4.4 创建集群
执行如下命令
./redis-trib.rb create --replicas 1 192.168.133.110:7001 192.168.133.110:7002 192.168.133.110:7003 192.168.133.110:7004 192.168.133.110:7005 192.168.133.110:7006
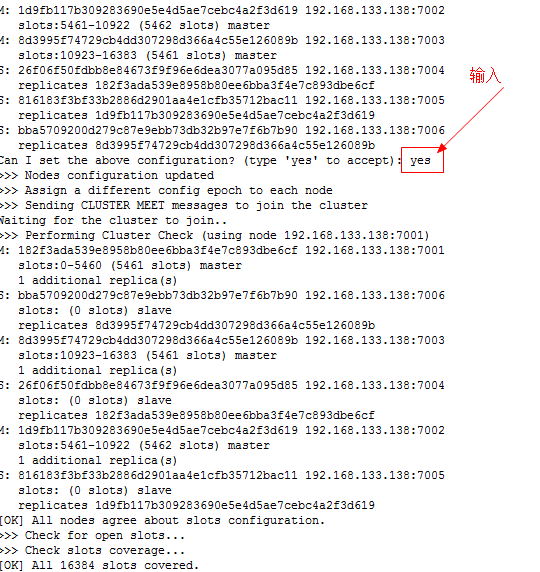
如果创建失败,需要清空每个节点下的node.conf

再从重新执行 ./redis-trib.rb create --replicas 1 192.168.133.138:7001 192.168.133.138:7002 192.168.133.138:7003 192.168.133.138:7004 192.168.133.138:7005 192.168.133.138:7006
6.4.5 集群的连接
[root@localhost bin]# ./redis-cli -p 7001 -c
7 Jedis
Redis不仅是使用命令来操作,现在基本上主流的语言都有客户端支持,比如Java, C. C#, C++,php, Node.js. Go等
在官方网站里列一些JAVA的客户端,有Jedis. Redisson. Jredis. JDBC-Redis.等其中官方推荐使用Jedis和Redisson。在企业中用的最多的就是Jedis,下面我们就重点学习下Jedis
7.1 通过 maven导入jar
|
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> |
7.2 单个redis示例测试string
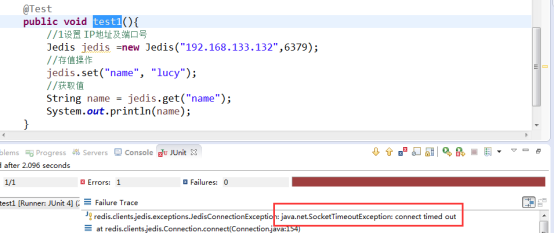
7.3 改动redis.conf
1) 默认情况下redis运行在保护模式(这种模式下,访问不需要密码),但是这种模式只允许本地访问
protected-mode yes 改为 no
2) 配置了只在127.0.0.1上绑定监听,取消一下
默认 bind 127.0.0.1 改为 #bind 127.0.0.1
7.4 防火墙
|
firewall-cmd --zone=public --add-port=6379/tcp --permanent firewall-cmd --reload |
7.5 示例2测试list
|
@Test public void testList(){ //1设置 IP地址及端口号 Jedis jedis =new Jedis("192.168.133.132",6379); //存值操作 jedis.lpush("names", "A","B","C"); //获取值 List<String> list = jedis.lrange("names", 0, -1); for (String name : list) { System.out.println(name); } } |
7.6 示例3 测试hash
|
@Test public void testHash(){ //1设置 IP地址及端口号 Jedis jedis =new Jedis("192.168.133.132",6379); Map<String,String> map = new HashMap<String,String>(); map.put("lucy", "12"); map.put("lily", "11"); //存值操作 jedis.hmset("students", map); //获取值 List<String> list = jedis.hmget("students", "lucy","lily" ); for (String name : list) { System.out.println(name); } } |
7.7 Jedis的连接池使用
import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; public class JedisPoolUtils { private static JedisPool pool = null; static{ //加载配置文件 InputStream in = JedisPoolUtils.class.getClassLoader().getResourceAsStream("redis.properties"); Properties pro = new Properties(); try { pro.load(in); } catch (IOException e) { e.printStackTrace(); } //获取连接池配置对象,并设置 JedisPoolConfig poolConfig = new JedisPoolConfig(); poolConfig.setMaxIdle(Integer.parseInt(pro.get("redis.maxIdle").toString()));//最大空闲连接数, 默认8个 poolConfig.setMinIdle(Integer.parseInt(pro.get("redis.minIdle").toString()));//最小空闲连接数, 默认0个 poolConfig.setMaxTotal(Integer.parseInt(pro.get("redis.maxTotal").toString()));//最大连接数, 默认8个 pool = new JedisPool(poolConfig,pro.getProperty("redis.url") , Integer.parseInt(pro.get("redis.port").toString())); } //对外提供获取连接方法 public static Jedis getJedis(){ return pool.getResource(); } //对外提供关闭连接方法 public static void colseJedis(Jedis jedis){ if(jedis!=null){ jedis.close(); } } }
- 把 下面内容存储成redis.properties 并放到资源文件路径下
|
redis.maxIdle=30 redis.minIdle=10 redis.maxTotal=100 redis.url=192.168.133.135 redis.port=6379 |
7.8 jedis连接集群版
第一步:使用JedisCluster对象。需要一个Set<HostAndPort>参数,Redis节点的列表。
第二步:直接使用JedisCluster对象操作redis。在系统中单例存在。
第三步:打印结果
第四步:系统关闭前,关闭JedisCluster对象。
注意需要开放相关端口号:

public class JedisTest { @Test public void test1() throws IOException{ // 第一步:使用JedisCluster对象。需要一个Set<HostAndPort>参数。Redis节点的列表。 Set<HostAndPort> nodes = new HashSet<>(); nodes.add(new HostAndPort("192.168.133.110", 7001)); nodes.add(new HostAndPort("192.168.133.110", 7002)); nodes.add(new HostAndPort("192.168.133.110", 7003)); nodes.add(new HostAndPort("192.168.133.110", 7004)); nodes.add(new HostAndPort("192.168.133.110", 7005)); nodes.add(new HostAndPort("192.168.133.110", 7006)); JedisCluster jedisCluster = new JedisCluster(nodes); // 第二步:直接使用JedisCluster对象操作redis。在系统中单例存在。 jedisCluster.set("name", "lucy"); String result = jedisCluster.get("name"); // 第三步:打印结果 System.out.println(result); // 第四步:系统关闭前,关闭JedisCluster对象。 jedisCluster.close(); } }
7.9 业务逻辑中添加缓存
7.9.1 接口封装
常用的操作redis的方法提取出一个接口,分别对应单机版和集群版创建两个实现类。
7.9.2 接口定义
public interface JedisClient { String set(String key, String value); String get(String key); Boolean exists(String key); Long expire(String key, int seconds); Long ttl(String key);//返回key 的过期时间 Long incr(String key); Long hset(String key, String field, String value); String hget(String key, String field); Long hdel(String key, String... field); }
7.9.3 单机版的实现类
public class JedisClientPool implements JedisClient { @Autowired private JedisPool jedisPool; @Override public String set(String key, String value) { Jedis jedis = jedisPool.getResource(); String result = jedis.set(key, value); jedis.close(); return result; } @Override public String get(String key) { Jedis jedis = jedisPool.getResource(); String result = jedis.get(key); jedis.close(); return result; } @Override public Boolean exists(String key) { Jedis jedis = jedisPool.getResource(); Boolean result = jedis.exists(key); jedis.close(); return result; } @Override public Long expire(String key, int seconds) { Jedis jedis = jedisPool.getResource(); Long result = jedis.expire(key, seconds); jedis.close(); return result; } @Override public Long ttl(String key) { Jedis jedis = jedisPool.getResource(); Long result = jedis.ttl(key); jedis.close(); return result; } @Override public Long incr(String key) { Jedis jedis = jedisPool.getResource(); Long result = jedis.incr(key); jedis.close(); return result; } @Override public Long hset(String key, String field, String value) { Jedis jedis = jedisPool.getResource(); Long result = jedis.hset(key, field, value); jedis.close(); return result; } @Override public String hget(String key, String field) { Jedis jedis = jedisPool.getResource(); String result = jedis.hget(key, field); jedis.close(); return result; } @Override public Long hdel(String key, String... field) { Jedis jedis = jedisPool.getResource(); Long result = jedis.hdel(key, field); jedis.close(); return result; } }
7.9.4 集群版实现类
@Component public class JedisClientCluster implements JedisClient { @Autowired private JedisCluster jedisCluster; @Override public String set(String key, String value) { return jedisCluster.set(key, value); } @Override public String get(String key) { return jedisCluster.get(key); } @Override public Boolean exists(String key) { return jedisCluster.exists(key); } @Override public Long expire(String key, int seconds) { return jedisCluster.expire(key, seconds); } @Override public Long ttl(String key) { return jedisCluster.ttl(key); } @Override public Long incr(String key) { return jedisCluster.incr(key); } @Override public Long hset(String key, String field, String value) { return jedisCluster.hset(key, field, value); } @Override public String hget(String key, String field) { return jedisCluster.hget(key, field); } @Override public Long hdel(String key, String... field) { return jedisCluster.hdel(key, field); } }
注意:集群版和单机版不能共用
7.9.5 业务系统中使用缓存
- 思路分析
1、查询数据库之前先查询缓存。
2、查询到结果,直接响应结果。
3、查询不到,缓存中没有则需要查询数据库。
4、把查询结果添加到缓存中。
5、返回结果。
例子:
package com.hrxb.zj.controller.menu; import java.util.List; import javax.servlet.http.HttpSession; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Scope; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.ResponseBody; import com.google.gson.Gson; import com.google.gson.reflect.TypeToken; import com.hrxb.zj.pojo.ScMenu; import com.hrxb.zj.pojo.ScUser; import com.hrxb.zj.service.menu.MenuService; import com.hrxb.zj.utils.EasyUITree; import com.hrxb.zj.utils.JedisClientCluster; import com.hrxb.zj.utils.MenuUtil; @RequestMapping("menu") @Scope("prototype") @Controller public class MeunController { @Autowired private MenuService menuService; @Autowired private JedisClientCluster jedisClientCluster; @Autowired private Gson gson; //从配置文件中获取对应的key @Value("${menu_list}") private String menu_list; /** * 根据用户返回对应菜单 */ @ResponseBody @RequestMapping("/selectMenuList") public List<EasyUITree> selectMenu(HttpSession session) { // 从sessio获取当前登录人的信息 ScUser scUser = (ScUser) session.getAttribute("user"); // 查询缓存 try { String result = jedisClientCluster.hget(menu_list, scUser.getUsername()); if (null != result && result.length() > 0){ //把json串转为 Java对象 List<EasyUITree> retList = gson.fromJson(result, new TypeToken<List<EasyUITree>>() { }.getType()); return retList; } } catch (Exception e) { e.printStackTrace(); } //查询数据库 获取当前登录人的菜单 List<ScMenu> menuList = menuService.selectAllByResp(scUser); // 把对象转为easy的树形属性 List<EasyUITree> treeList = MenuUtil.createTreeMenu(menuList, 0); //放入缓存 try { jedisClientCluster.hset(menu_list, scUser.getUsername(), gson.toJson(treeList)); } catch (Exception e) { e.printStackTrace(); } return treeList; } }
7.10 高可用(High Availability)
是当一台服务器停止服务后,对于业务及用户毫无影响。 停止服务的原因可能由于网卡、路由器、机房、CPU负载过高、内存溢出、自然灾害等不可预期的原因导致,在很多时候也称单点问题
1)解决单点问题主要有2种方式:
1.1.1 主备方式
这种通常是一台主机、一台或多台备机,在正常情况下主机对外提供服务,并把数据同步到备机,当主机宕机后,备机立刻开始服务。
Redis HA中使用比较多的是keepalived,它使主机备机对外提供同一个虚拟IP,客户端通过虚拟IP进行数据操作,正常期间主机一直对外提供服务,宕机后VIP自动漂移到备机上。
优点是对客户端毫无影响,仍然通过VIP操作。
缺点也很明显,在绝大多数时间内备机是一直没使用,被浪费着的。
1.1.2 主从方式
这种采取一主多从的办法,主从之间进行数据同步。 当Master宕机后,通过选举算法(Paxos、Raft)从slave中选举出新Master继续对外提供服务,主机恢复后以slave的身份重新加入。
主从另一个目的是进行读写分离,这是当单机读写压力过高的一种通用型解决方案。 其主机的角色只提供写操作或少量的读,把多余读请求通过负载均衡算法分流到单个或多个slave服务器上。
缺点是主机宕机后,Slave虽然被选举成新Master了,但对外提供的IP服务地址却发生变化了,意味着会影响到客户端。 解决这种情况需要一些额外的工作,在当主机地址发生变化后及时通知到客户端,客户端收到新地址后,使用新地址继续发送新请求。
1.1.3 数据同步
无论是主备还是主从都牵扯到数据同步的问题,这也分2种情况:
l 同步方式:当主机收到客户端写操作后,以同步方式把数据同步到从机上,当从机也成功写入后,主机才返回给客户端成功,也称数据强一致性。 很显然这种方式性能会降低不少,当从机很多时,可以不用每台都同步,主机同步某一台从机后,从机再把数据分发同步到其他从机上,这样提高主机性能分担同步压力。 在redis中是支持这种配置的,一台master,一台slave,同时这台salve又作为其他slave的master。
l 异步方式:主机接收到写操作后,直接返回成功,然后在后台用异步方式把数据同步到从机上。 这种同步性能比较好,但无法保证数据的完整性,比如在异步同步过程中主机突然宕机了,也称这种方式为数据弱一致性。
1.1.4 分布式
分布式(distributed), 是当业务量、数据量增加时,可以通过任意增加减少服务器数量来解决问题。
至少部署两台Redis服务器构成一个小的集群,主要有2个目的:
- 高可用性:在主机挂掉后,自动故障转移,使前端服务对用户无影响。
- 读写分离:将主机读压力分流到从机上。
可在客户端组件上实现负载均衡,根据不同服务器的运行情况,分担不同比例的读请求压力。
逻辑图:
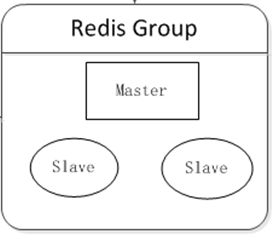
l 配置redis 的主从
Redis的主从复制功能非常强大,一个master可以拥有多个slave,而一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群架构。下面楼主简单的进行一下配置。
1、上面安装好的一个Redis作为master,其ip:169.254.250.250,然后使用VMWare的虚拟机克隆功能将刚刚那个linux系统克隆一份作为slave,
并修改其IP为 169.254.250.251
2、修改slave的redis配置文件:
slaveof 169.254.250.250 6379 (映射到主服务器上)
如果master设置了验证密码,还需配置masterauth。楼主的master设置了验证密码为admin,所以配置masterauth admin。
配置完之后启动slave的Redis服务,OK,主从配置完成。
下面测试一下:
通过info 命令查看当前主服务的信息:
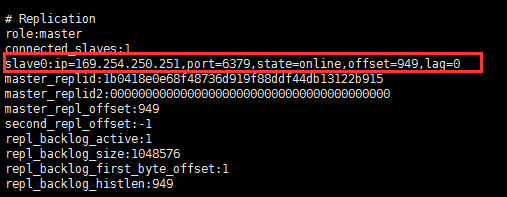
通过info 命令查看当前从服务的信息:

主服务器:
从服务器: