什么是索引
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。索引是对数据库表中一个或多个列的值进行排序的结构。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息
常见的查询算法:顺序查找、二分查找、二叉排序树查找、哈希散列法、分块查找、平衡多路搜索树B树(B-tree)
建立索引的优缺点
优点:
1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
缺点:
1.索引需要占用数据表以外的物理存储空间
2.创建索引和维护索引要花费一定的时间
3.当对表进行更新操作时,索引需要被重建,这样降低了数据的维护速度。
索引类型:
根据数据库的功能,可以在数据库设计器中创建索引:唯一索引、主键索引和聚集索引。 尽管唯一索引有助于定位信息,但为获得最佳性能结果,建议改用主键或唯一约束。
唯一索引: UNIQUE 例如:create unique index stusno on student(sno);
表明此索引的每一个索引值只对应唯一的数据记录,对于单列唯一性索引,这保证单列不包含重复的值。对于多列唯一性索引,保证多个值的组合不重复。
主键索引: primary key
数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。 在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
主键和唯一索引都要求值唯一,但是它们还是有区别的:
一张表只能有一个主键,但可以创建多个唯一索引;
主键创建后一定包含一个唯一索引,唯一索引并一定是主键;
主键不能为null,唯一索引可以为null;
主键可以做为外键,唯一索引不行;
聚集索引(也叫聚簇索引):cluster
在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。 如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
索引的实现方式
1.B+Tree 索引
MyISAM和InnoDB存储引擎的默认创建的是B+tree索引,Memory存储引擎也可以为B+tree索引(或者Hash索引)
InnoDB 的 B+Tree 索引分为主索引和辅助索引。
B+Tree的优点
1 B+Tree拥有B-Tree的优点,深度浅,数据块大
2因为只在叶子结点存储数据,从而导致扫全表的能力强,因为叶子结点是顺序的,从而导致排序功能更强。
3查询时间相对稳定,因为原因1:平衡二叉树,解决了查询不会受到结点分布的影响, 原因2:因为数据在叶子结点,导致每次查询的深度是一样的(相对于B-Tree)
B+Tree索引在mysql中的体现形式
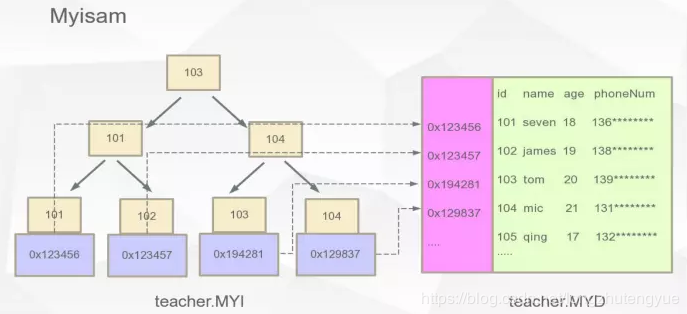
体现形式之一: myisam
体现形式之二: innodb
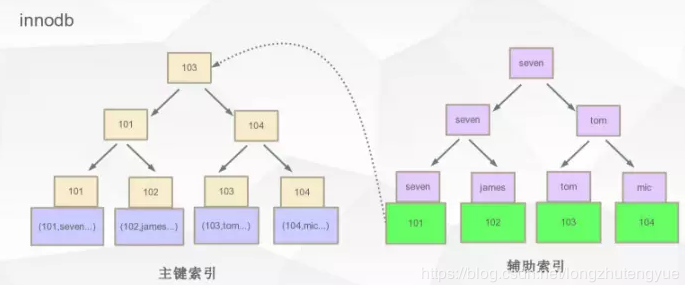
特点:以主键作为索引,同时也是聚集索引:记录在数据库的顺序和物理地址的顺序是一样的
若以name作为索引,则先用辅助索引找到主键,在根据主键找到对应的数据库记录
两者的区别:
Innodb:通过辅助索引找到主键,在通过主键索引来找到记录,
myisam通过索引找到物理地址,再通过物理地址找到对应的记录。
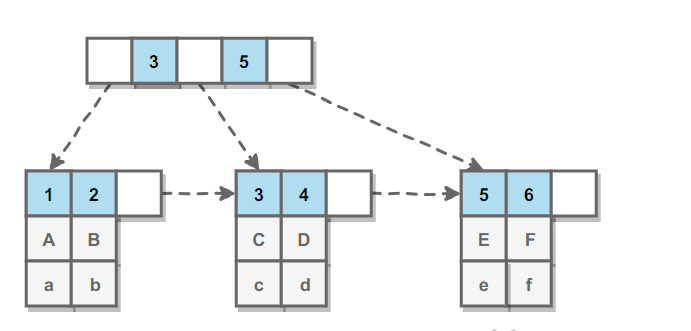
主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引
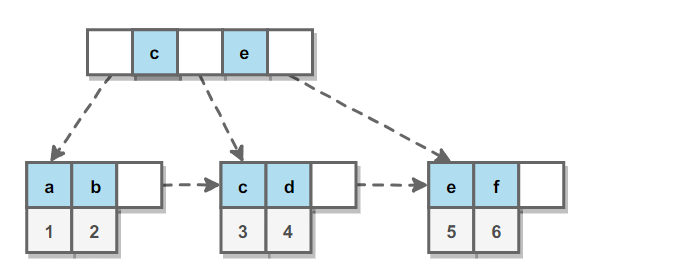
辅助索引 的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找
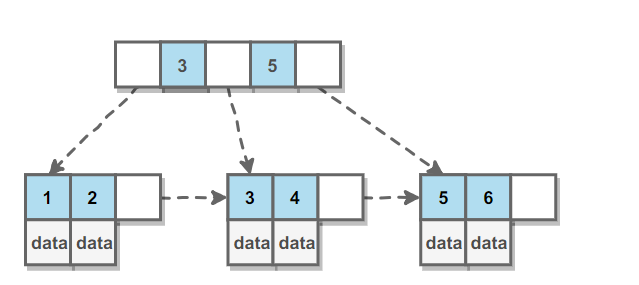
2. 哈希索引
哈希索引能以 O(1) 时间进行查找,但是失去了有序性:无法用于排序与分组;只支持精确查找,无法用于部分查找和范围查找。
InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找
3. 全文索引
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引
4. 空间数据索引
MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。必须使用 GIS 相关的函数来维护数据。
创建索引
X
1.不是越多越好,因为如果建立过多的索引,保存的速度就会下降
2.常更新的表越少越好,因为在字段中做更新(插入)操作后,索引也会更新的,这样的话效率会大大降低
3.数据量小的表最好不要建立索引,因为小的表即使建立索引也不会有大的用处,还会增加额外的索引开销
√
4.不同的值比较多的列才需要建立索引
5.某种数据本身具备唯一性的时候,建立唯一性索引,可以保证定义的列的数据完整性,以提高查询熟度
6.频繁进行排序或分组的列(group by或者是order by)可以建立索引,提高搜索速度
7.经常用于查询条件的字段应该建立索引
不经常引用的列不要建立索引,因为不常用,即使建立了索引也没有多大意义,经常频繁更新的列不要建立索引,因为肯定会影响插入或更新的效率,索引并不是一劳永逸的,用的时间长了需要进行整理或者重建
索引最左前缀匹配
在创建一个n列的索引时,需要遵循“最左前缀”原则。
创建表:create table abc(a varchar(32) not null, b varchar(32), c date, d varchar(32) );
创建普通索引:create index in_abc_acb on abc(a, c, b);
1、必须用到索引的第一个字段
select * from abc where d='d' and b='b'; 不会用到索引,必须要用到左边第一个字段;
2、对于索引的第一个字段,用like时左边必须是固定值,通配符只能出现在右边
select * from AAA where a like ‘1%’;会用到索引;而select * from abc where a like ‘%1’;不会用到索引。
3、遇到范围(>、<、between、like)查询就停止匹配,
select * from abc where a like '1%' and c=sysdate; a 会用到索引,c 则不会
4、字段前加了函数(表达式)索引会被抑制,
select * from abc where trim(a) = 'a' ; a不会用到索引
select * from abc where a = 'a' and c + 1 > sysdate; a会用到索引 c不会用到索引
select * from abc where a = 'a' and c > sysdate - 2; a会用到索引 c会用到索引
5、索引是从左到右匹配,in 和 = 可以乱序
select * from abc where b like 'b%' and c = sysdate and a='a' ;acb的索引都可以用到
Mysql索引失效
1.索引无法存储null值
a.单列索引无法储null值,复合索引无法储全为null的值。·
b.查询时,采用is null条件时,不能利用到索引,只能全表扫描。
2.不适合键值较少的列(不适合重复数据较多的列)
假如索引列TYPE有5个键值,如果有1万条数据,那么 WHERE TYPE = 1将访问表中的2000个数据块。再加上访问索引块,一共要访问大于200个的数据块。如果全表扫描,假设10条数据一个数据块,那么只需访问 1000个数据块,既然全表扫描访问的数据块少一些,肯定就不会利用索引了。
3.前导模糊查询不能利用索引(like '%XX’或者like ‘%XX%’)
假如有这样一列code的值为’AAA’,‘AAB’,‘BAA’,‘BAB’ ,如果where code like '%AB’条件,由于前面是模糊的,所以不能利用索引的顺序,必须一个个去找,看是否满足条件。这样会导致全索引扫描或者全表扫描。如果 是这样的条件where code like 'A % ',就可以查找CODE中A开头的CODE的位置,当碰到B开头的数据时,就可以停止查找了,因为后面的数据一定不满足要求。这样就可以利用索引了。
4.其他几种索引失效的情况
1.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
2.对于多列索引,不是使用的第一部分,则不会使用索引
3.like查询以%开头
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
数据库创建索引的几种方法
1、普通索引
CREATE INDEX indexName ON mytable(username(length));
创建表的时候直接指定:
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
删除索引的语法:
DROP INDEX [indexName] ON mytable;
2、唯一索引
它与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
创建索引:
CREATE UNIQUE INDEX indexName ON mytable(username(length))
修改表结构:
ALTER table mytable ADD UNIQUE [indexName] (username(length))
创建表的时候直接指定:
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
UNIQUE [indexName] (username(length))
);
有四种方式来添加数据表的索引:
1.ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
2.ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
3.ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。4.ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。
例如:
创建索引:ALTER TABLE testalter_tbl ADD INDEX (c);
删除索引:ALTER TABLE testalter_tbl DROP INDEX (c);
显示索引信息
SHOW INDEX FROM table_nameG