1.按位运算:
AND运算 &
and运算通常用于二进制的取位操作,例如一个数 and 1的结果就是取二进制的最末位。这可以用来判断一个整数的奇偶,二进制的最末位为0表示该数为偶数,最末位为1表示该数为奇数。(有0为0,无0为1)
OR运算 |
or运算通常用于二进制特定位上的无条件赋值,例如一个数OR 1的结果就是把二进制最末位强行变成1。如果需要把二进制最末位变成0,对这个数OR 1之后再减一就可以了,其实际意义就是把这个数强行变成最接近的偶数。(有1为1,无1为0)
XOR运算 ^
异或的符号是^。按位异或运算, 对等长二进制模式按位或二进制数的每一位执行逻辑按位异或操作. 操作的结果是如果某位不同则该位为1, 否则该位为0.( 不同则为1,相同则为0。 )
NOT运算 ~
NOT运算的定义是把内存中的0和1全部取反。使用not运算时要格外小心,你需要注意整数类型有没有符号。如果not的对象是无符号整数(不能表示负数),那么得到的值就是它与该类型上界的差,因为无符号类型的数是用00到$FFFF依次表示的。(全体取反)
SHI运算 <<
a SHI b就表示把a转为二进制后左移b位(在后面添b个0)。例如100的二进制为1100100,而110010000转成十进制是400,那么100 SHI 2 = 400。可以看出,a SHI b的值实际上就是a乘以2的b次方,因为在二进制数后添一个0就相当于该数乘以2。
SHR运算 >>
和SHI相似,a SHR b表示二进制右移b位(去掉末b位),相当于a除以2的b次方(取整)。和上面一样的例子,那么400 SHR 2 = 100。
2.逻辑运算:
"∨" 表示"或"
"∧" 表示"与".
"┐"表示"非".
"=" 表示"等价".
1和0表示"真"和"假"
各种编程语言中的逻辑运算符
| 作用 | C | Pascal |
|---|---|---|
| 等于 | == | = |
| 不等于 | != | <> |
| 小于 | < | < |
| 大于 | > | > |
| 小于等于 | <= | <= |
| 大于等于 | >= | >= |
| 与 | && | and |
| 或 | || | or |
| 非 | ! | not |
| 异或 | ^ | xor |
3.位移运算:
<<运算 a<<b 表示把a转为二进制后左移b位(在后面添加 b个0)。例如100的二进制表示为1100100,100左移2位后(后面加2个零):1100100<<2 =110010000 =400,可以看出,a<<b的值实际上就是a乘以2的b次方,因为在二进制数后面添加一个0就相当该数乘以2,2个零即2的2次方 等于4。通常认为a<<1比a*2更快,因为前者是更底层一些的操作。因此程序中乘以2的操作尽量用左移一位来代替。 定义一些常量可能会用到<<运算。你可以方便的用1<<16 -1 来表示65535(unsingned int 最大值16位系统)。很多算法和数据结构要求数据模块必须是2的幂,此时就可以用<<来定义MAX_N等常量。
>>运算 和<<相似,a>>b表示二进制右移b位(去掉末b位),相当于a除以2的b次方(取整)。我们经常用>>1来代替 /2(div 2),比如二分查找、堆的插入操作等等。想办法用>>代替除法运算可以使程序的效率大大提高。最大公约数的二进制算法用除以2操作来代替慢的出奇的%(mod)运算,效率可以提高60%。 int a =100; a/4 ==a>>2;
位移运算运用 例子
1.合并数据 缩短数据:int a =4; int b=2; 可以将数据 a,b 保存于一个变量 int c中,在此int 类型为32位 a=0x0000 0004; / /十六进制 b=0x0000 0002; int c = a<<16;//左移操作-将a数据向左移动16位=0x0004 0000 c |=b; // (|)操作,一个为1 则为1,所以高16位不变,低16位值为 b值,即c = 0x0004 0002;完成数据的合并
2.解析数据 上面c = 0x0004 0002; 读取高位:int a1 = c>>16; / / 右移16位,消除低位数据,读取高位数据 a1 = 0x0000 0004 读取低位:int a2 = c&0xFFFF; //(&)操作,2个都为1 则为1,所以0xFFFF 即 0X0000 FFFF, 所以高位全为0,低位的 1不变,0还是0,a2=0x0000 0002,读取低位成功 读取低位2:int a2 = c<<16; 消除高位,低位存入高位,a2=0x0002 0000; a2 = a2>>16;高位存入低位,消除低位; a2 = 0x0000 0002;
下面列举一些常见的二进制位的变换操作
去掉最后一位 101101->10110 x>>1 在最后加一个0 101101->1011010 x<<1 把最后一位变成1 101100->101101 x | 1 把最后一位变成0 101101->101100 (x |1) - 1 最后一位取反 101101->101100 x ^ 1 把右数第K位变成1 101001->101101,k=3 x | (1<<(k-1)) 把右数第K位变成0 101101->101101,k=3 x & ~(1<<(k-1)) 右数第k位取反 101001->101101,k=3 x ^ (1<<(k-1)) 取末三位 1101101->101 x &7
4.位扩展和位截断运算
一个小规律, 2^n-2^(n-1) = 2^(n-1) 3^n-3^(n-1)=2*3^(n-1) 。
位扩展其实很好理解,正数和0往前加零就够了,负数则是往前加一,不过注意位扩展往往都是隐形的,不知不觉就扩展了,比如 short i = 6; int j = i; 注意 位扩展 数值是不变的
位截断,就是保留低k位二进制码, 比如把一个四位二进制码截断成三位,这不可避免的改变了原来的值,
对于无符号数,B2U([X',X'',X''',X''''......]) mod 2^k 就可以了。 对于有符号数,U2T(B2U([x',x'',x''',x''''.....])mod 2^k)
注: B2U 二进制码解释为无符号数 U2T 无符号数编码解释为补码
MIPS指令系统中涉及的运算

基本运算部件***:
1.串行加法器 :
串行加法器即加法器执行位串行行操作,利用多个时钟周期完成一次加法运算,即输入操作数和输出结果方式为随时钟串行输入/输出。在实际生活中,希望减少硬件资源占用率时,就可以使用位串行加法器。
(这种结构所用元件比较少但是进位传递时间较长)
详见清华大学出版社计算机组成与系统结构(第2版)P71
2.并行进位加法器:
用n位全加器实现两个n位操作数各位同时相加,这种加法器称为并行加法器
详见清华大学出版社计算机组成与系统结构(第2版)P72 73
3.带标志加法器:
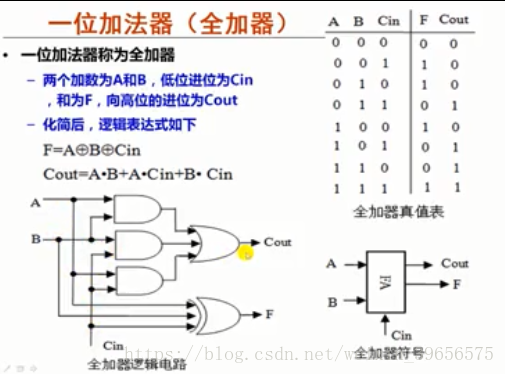
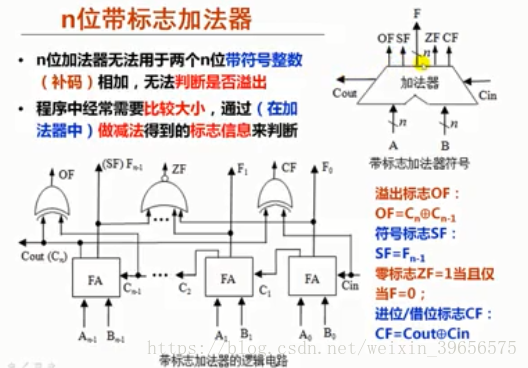
4.算术逻辑部件:
详见清华大学出版社计算机组成与系统结构(第2版)P74
定点数运算
*补码的设计目的*:
(1)使符号位能与有效值部分一起参加运算,从而简化运算规则.
(2)使减法运算转换为加法运算,进一步简化计算机中运算器的线路设计
所有这些转换都是在计算机的最底层进行的,而在我们使用的汇编、C等其他高级语言中使用的都是原码。
1.补码加减运算
补码加法的基本公式为:
整数 [A]补+[B]补=[A+B]补 (mod 2n+1)
小数 [A]补+[B]补=[A+B]补 (mod 2)
即补码表示肋两个数在进行加法运算时,可以把符号位与数位同等处理,只要结果不超出机器能表示的数值范围,运算后的结果按2n+1取模(对于整数);或按2取模(对于小数),就能得到本次加法的运算结果。
对于减法因A-B=A+(-B)
则[A-B]补=[A+(-B)]补
由补妈加法基本公式可得:
整数 [A-B]补=[A]补+[-B]补 (mod 2n+1)
小数 [A-B]补=[A]补+[-B]补 (mod 2)
因此,若机器数采用补码, 当求A-B时, 只需先求[-B]补(称[-B]补为“求补”后的减数),就可按补码加法规则进行运算。而[-B]补由[B]补连同符号位在内,每位取反,末位加1而得。
例:x=0.1010,y=-0.0011,用补码的加法求x+y
解:[x]补=0.1010,[y]补=1.1101
[x]补+[y]补=0.1010+1.1101=0.0111(按模2的意义,最左边的1丢掉)
x+y=0.0111
例:x=0.1001,y=-0.0011,用补码的减法求x-y
解:[x]补=0.1001,[y]补=1.1101,[-y]补=0.0011
[x]补-[y]补=[x]补+[-y]补=0.1001+0.0011=0.1100
x-y=0.1100
例:设机器数字长为8位,其中一位为符号位,令A=-93,B=+45,求[A-B]补。
解:由A=-93=-1011101,得[A]补=1,0100011
由B=+45=+0101101,得[B]补=0,0101101,[-B]补=1,1010011
[A-B]补=[A]补+[-B]补=1,0100011+1,1010011=10,1110110
按模2n+1的意义,最左边的“1”自然丢掉,故[A-B]补=0,1110110,还原成真值得A-B=118,结果出错,这是因为A-B=-138超出了机器字长所能表示的范围。在计算机中,这种超出机器字长的现象,叫溢出。为此,在补码定点加减运算过程中,必须对结果是否溢出作出明确的判断。
解:由A=-93=-1011101,得[A]补=1,0100011
2.原码一位乘法(详见清华大学出版社计算机组成与系统结构(第2版)P78 79 80)
由于原码表示与真值极为相似,只差一个符号,而乘积的符号又可通过两数符号的逻辑异或求得,因此,上述讨论的结果可以直接用于原码一位乘,只需加上符号位处理即可。
上图是一个32位乘法器的结构框图,其中32位被乘数放在R2中,运算开始时32位乘数放在R1中,运算结束时64位乘积的高位放在R0中,低位放在R1中,R0和R1串联移位。完成这个定点原码一位乘法的运算规则可以用如下图所示的逻辑流程图表示。
在该乘法过程中,每次操作是根据乘数的一位进行操作,对于32位数的乘法,需要循环32次完成一个乘法操作,因此称为一位乘法。
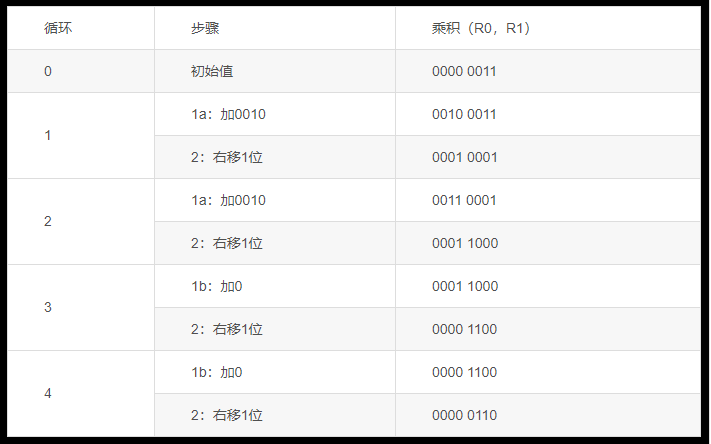
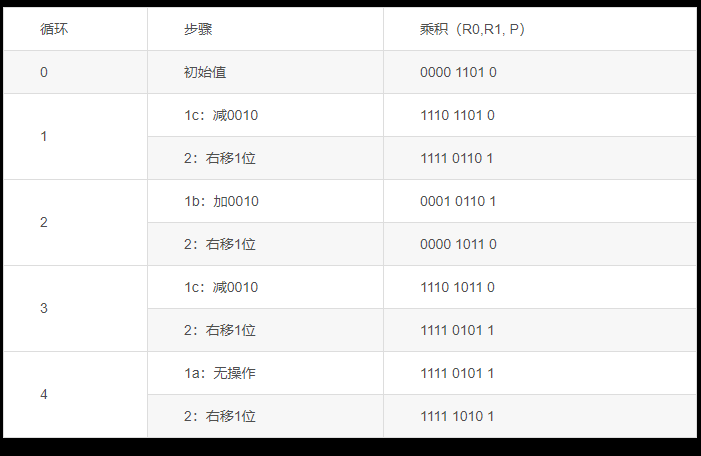
例:用原码的乘法方法进行2×3的四位乘法。
解:在乘法开始之前,R0和R1中的初始值为0000和0011,R2中的值为0010。
在乘法的第一个循环中,判断R1的最低位为1,所以进入步骤1a,将R0的值加上R2的值,结果0010送人R0,然后进入第二步,将R0和R1右移一位,R0、Rl的结果为0001 0001,见下表的循环1,表中黑体字的数据位是乘法过程中判断的R1最低位。
第二个循环过程中,判断R1的最低位为l,仍进入步骤la,加0010,结果为0011,然后在第二步中将R0和R1右移一位,结果为0001 1000,见下表的循环2。
第三次循环中,因R1的最低位为0,进入步骤lb,R0不变,第二步移位后结果为00001100,见下表的循环3。
第四次循环时仍因R1最低位为0,只作移位,结果为00000110,这就是乘法的结果6,见下表的循环4。
3.补码一位乘法
(详见清华大学出版社计算机组成与系统结构(第2版)P81 82 83)
一种比较好的带符号数乘法的方法是布斯(Booth)算法。它采用相加和相减的操作计算补码数据的乘积。Booth算法对乘数从低位开始判断,根据两个数据位的情况决定进行加法、减法还是仅仅移位操作。判断的两个数据位为当前位及其右边的位(初始时需要增加一个辅助位0),移位操作是向右移动。在上例中,第一次判断被乘数0110中的最低位0以及右边的位(辅助位0),得00;所以只进行移位操作;第二次判断0110中的低两位,得10,所以作减法操作并移位,这个减法操作相当于减去2a的值;第三次判断被乘数的中间两位,得11,于是只作移位操作;第四次判断0110中的最高两位,得01,于是作加法操作和移位,这个加法相当于加上8a的值,因为a的值已经左移了三次。
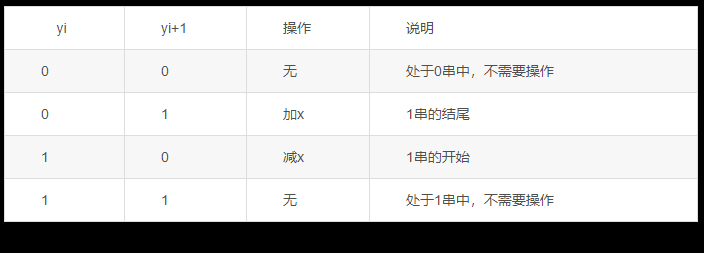
一般而言,设y=y0,yly2…yn为被乘数,x为乘数,yi是a中的第i位(当前位)。根据yj与yi+1的值,Booth算法表示如下表所示,其操作流程如下图所示。在Booth算法中,操作的方式取决于表达式(yi+1-yi)的值,这个表达式的值所代表的操作为:
0 无操作
+1 加x
-1 减x
Booth算法操作表示
实现32位Booth乘法算法的流程图
乘法过程中,被乘数相对于乘积的左移操作可表示为乘以2,每次循环中的运算可表示为对于x(yi+1-yi)231-i项的加法运算(i=3l,30,…,1,0)。这样,Booth算法所计算的结果 可表示为:
x×(0-y31)×20
+x×(y31-y30)×21
+x×(y30-y29)×22
…
+x×(y1-y0)×231
=x×(-y0×231 +y1×230 +y2×229+y31×20)
=x×y
例:用Booth算法计算2×(-3)。
解:[2]补=0010, [-3]补=1101,在乘法开始之前,R0和R1中的初始值为0000和1101,R2中的值为0010。
在乘法的第一个循环中,判断R1的最低位和辅助位为10,所以进入步骤1c,将R0的值减去R2的值,结果1110送人R0,然后进人第二步,将R0和Rl右移一位,R0和R1的结果为11110110,辅助位为l。
在第二个循环中,首先判断Rl的最低位和辅助位为0l,所以进入步骤1b,作加法,R0+R2=1111+0010,结果0001送入R0,这时R0R1的内容为0001 0110,在第二步右移后变为0000 1011,辅助位为0。
在第三次循环中,判断位为10,进入步骤lc,R0减去R2,结果1110送入R0,R1不变;步骤2移位后R0和R1的内容为1111 01011,辅助位为1。
第四次循环时,因两个判断位为11,所以不作加减运算,向右移位后的结果为1111 1010,这就是运算结果(—6)。
这个乘法的过程描述如下表所示,表中乘积一栏表示的是R0、R1的内容以及一个辅助位P,黑体字表示对两个判断位的判断。
用Booth补码一位乘法计算2 ×(-3)的过程
2.原码除法:
原码除法和原码乘法一样,符号位是单独处理的。以小数为例:
式中 为x的绝对值,记作x*
为y的绝对值,记作y*
即商符由两数符号位“异或”运算求得,商值由两数绝对值相除(x/y)求得。
小数定点除法对被除数和除数有一定的约束,即必须满足下列条件:
0<|被除数|≤|除数|
实现除法运算时,还应避免除数为0或被除数为0。前者结果为无限大,不能用机器的有限位数表示;后者结果总是0,这个除法操作等于白做,浪费了机器时间。至于商的位数一般与操作数的位数相同。
原码除法中由于对余数的处理不同,又可分为恢复余数法和不恢复余数法(加减交替法)两种。
(1)恢复余数法。恢复余数法的特点是:当余数为负时,需加上除数,将其恢复成原来的余数。
由上所述,商值的确定是通过比较被除数和除数的绝对值大小,即x-y实现的, 而计算机内只设加法器, 故需将x-y操作变为[x]补+[-y]补的操作。
例:已知:x=-0.1011,y=-0.1101,求:[x÷y]原
解:由x*=0.1011,[x]原=1.1011
y*=0.1101,[-y]补=1.0011,[y]原=1.1101
商值的求解过程如下: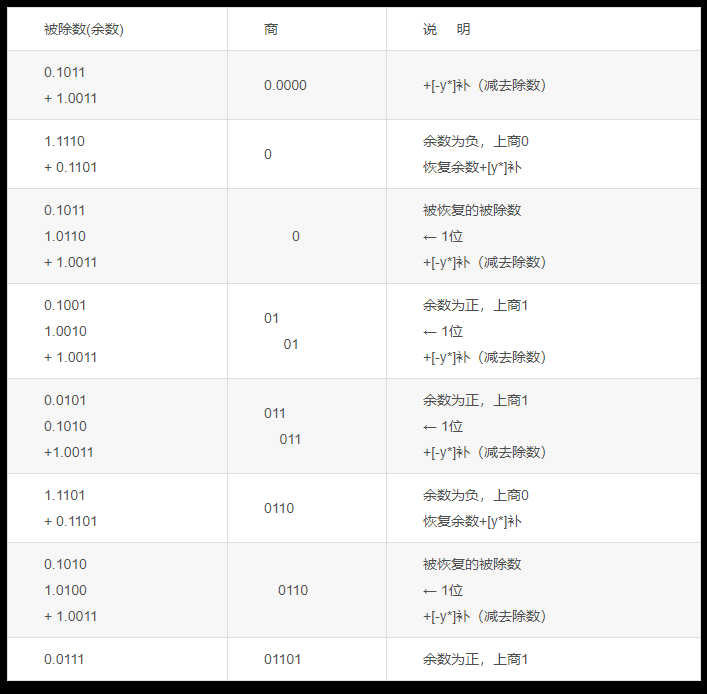
故商值为0.1101
商的符号位为 x0⊕y0=1⊕1=0 故[x+y]=0.1101
由此可见,共上商5次,第一次上的商在商的整数位上,这对小数除法而言,可用它作溢出判断。即当该位为“1”时,表示此除法为溢出,不能进行,应由程序进行处理;当该位为“0”时,说明除法合法,可以进行。
在恢复余数法中,每当余数为负时,都需恢复余数,这变延长了机器除法的时间,操作也很不规则,对线路结构不利。加减交替法可克服这些缺点。
(2)加减交替法。加减交替法又称不恢复余数法,可以认为它是恢复余数法的一种改进算法。
分析原码恢复余数法得知:
当余数Ri>0时,可上商“1”,再对Ri左移一位后减除数,即2Ri-y*。
当余数Ri>0时,可上商“0”,然后再做Ri+y,即完成恢复余数的运算,再做2(Ri+y)-y,也即2Ri+y。
可见,原码恢复余数法可归纳为:
当余数Ri>0时,商上“1”,做2Ri-y*的运算;
当余数Ri<0时,商上“0”,做2Ri+y*的运算。
这里已看不出余数的恢复问题了,而只是做加y或减y,因此,一般把它叫做加减交替法或不恢复余数法。
例:已知:x=-0.1011,y=-0.1101,求:[x÷ y]原
解:[x]原=1.1011, x*=0.1011
[y]原=0.1101, y=0.1101, [-y]补=1.0011
商值的求解过程如下表所示: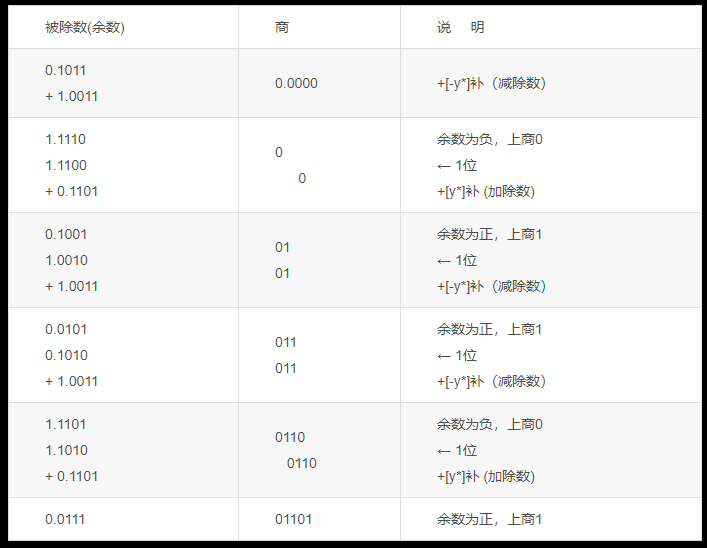
商的符号位为x0⊕y0=1⊕0=1
所以[x+y]=1.1101
分析此例可见,n位小数的除法共上商n+1次,第一次商用来判断是否溢出。倘若比例因子选择恰当,除数结果不溢出,则第一次商肯定是0。如果省去这位商,只需上商n次即可,此时除法运算一开始应将被除数左移一位减去除数,然后再根据余数上商。
对于整数除法,要求满足以下条件:
0<|除数|≤|被除数|
因为这样才能得到整数商。通常在做整数除法前,先要对这个条件进行判断,若不满足上述条件,机器发出出错信号,程序要重新设定比例因子。
浮点数的加减运算一般由以下五个步骤完成:对阶、尾数运算、规格化、舍入处理、溢出判断
一、对阶
所谓对阶是指将两个进行运算的浮点数的阶码对齐的操作。对阶的目的是为使两个浮点数的尾数能够进行加减运算。因为,当进行M x·2Ex与M y·2Ey加减运算时,只有使两浮点数的指数值部分相同,才能将相同的指数值作为公因数提出来,然后进行尾数的加减运算。对阶的具体方法是:首先求出两浮点数阶码的差,即⊿E=E x-E y,将小阶码加上⊿E,使之与大阶码相等,同时将小阶码对应的浮点数的尾数右移相应位数,以保证该浮点数的值不变。几点注意:
(1)对阶的原则是小阶对大阶,之所以这样做是因为若大阶对小阶,则尾数的数值部分的高位需移出,而小阶对大阶移出的是尾数的数值部分的低位,这样损失的精度更小。
(2)若⊿E=0,说明两浮点数的阶码已经相同,无需再做对阶操作了。
(3)采用补码表示的尾数右移时,符号位保持不变。
(4)由于尾数右移时是将最低位移出,会损失一定的精度,为减少误差,可先保留若干移出的位,供以后舍入处理用。
二、尾数运算
尾数运算就是进行完成对阶后的尾数相加减。这里采用的就是我们前面讲过的纯小数的定点数加减运算。
三、结果规格化
在机器中,为保证浮点数表示的唯一性,浮点数在机器中都是以规格化形式存储的。对于IEEE754标准的浮点数来说,就是尾数必须是1.M的形式。由于在进行上述两个定点小数的尾数相加减运算后,尾数有可能是非规格化形式,为此必须进行规格化操作。
规格化操作包括左规和右规两种情况。
左规操作:将尾数左移,同时阶码减值,直至尾数成为1.M的形式。例如,浮点数0.0011·25是非规格化的形式,需进行左规操作,将其尾数左移3位,同时阶码减3,就变成1.1100·22规格化形式了。
右规操作:将尾数右移1位,同时阶码增1,便成为规格化的形式了。要注意的是,右规操作只需将尾数右移一位即可,这种情况出现在尾数的最高位(小数点前一位)运算时出现了进位,使尾数成为10.xxxx或11.xxxx的形式。例如,10.0011·25右规一位后便成为1.00011·26的规格化形式了。
四、 舍入处理
浮点运算在对阶或右规时,尾数需要右移,被右移出去的位会被丢掉,从而造成运算结果精度的损失。为了减少这种精度损失,可以将一定位数的移出位先保留起来,称为保护位,在规格化后用于舍入处理。
IEEE754标准列出了四种可选的舍入处理方法:
(1)就近舍入(round to nearest)这是标准列出的默认舍入方式,其含义相当于我们日常所说的“四舍五入”。例如,对于32位单精度浮点数来说,若超出可保存的23位的多余位大于等于100…01,则多余位的值超过了最低可表示位值的一半,这种情况下,舍入的方法是在尾数的最低有效位上加1;若多余位小于等于011…11,则直接舍去;若多余位为100…00,此时再判断尾数的最低有效位的值,若为0则直接舍去,若为1则再加1。
(2)朝+∞舍入(round toward +∞)对正数来说,只要多余位不为全0,则向尾数最低有效位进1;对负数来说,则是简单地舍去。
(3)朝-∞舍入(round toward -∞)与朝+∞舍入方法正好相反,对正数来说,只是简单地舍去;对负数来说,只要多余位不为全0,则向尾数最低有效位进1。
(4)朝0舍入(round toward 0)
即简单地截断舍去,而不管多余位是什么值。这种方法实现简单,但容易形成累积误差,且舍入处理后的值总是向下偏差。
五、 溢出判断
与定点数运算不同的是,浮点数的溢出是以其运算结果的阶码的值是否产生溢出来判断的。若阶码的值超过了阶码所能表示的最大正数,则为上溢,进一步,若此时浮点数为正数,则为正上溢,记为+∞,若浮点数为负数,则为负上溢,记为-∞;若阶码的值超过了阶码所能表示的最小负数,则为下溢,进一步,若此时浮点数为正数,则为正下溢,若浮点数为负数,则为负下溢。正下溢和负下溢都作为0处理。
要注意的是,浮点数的表示范围和补码表示的定点数的表示范围是有所不同的,定点数的表示范围是连续的,而浮点数的表示范围可能是不连续的。
六、例子
float a=0.3;b=1.6;
a=(0.3)10=(0011 1110 1001 1001 1001 1001 1001 1010)2 Sa=0 Ea=011 1110 1 Ma=1.001 1001 1001 1001 1001 1010
b=(1.6)10=(0011 1111 1100 1100 1100 1100 1100 1101)2 Sb=0 Eb=011 1111 1 Mb=1.100 1100 1100 1100 1100 1101
a+b=?
第一步:对阶
∵ Ea<Eb Eb-Ea=2
∴ Ma要调整为 0.0 1001 1001 1001 1001 1001 10 10
E=011 1111 1
第二步:尾数运算
0.01001100110011001100110
+ 1.10011001100110011001101
1.11100110011001100110011
第三步:规格化
1.11100110011001100110011已经是个规格化数据了
第四步:舍入处理
由于在对阶时,Ma有右移,且第一次最高为1,第二次为0,所以按"0舍1入",尾数运算结果调整为 1.11100110011001100110100
第五步:溢出判断
没有溢出,阶码不调整,所以最后的结果为
a+b=(0 01111111 11100110011001100110100)2=(0011 1111 1111 0011 0011 0011 0011 0100)2=(3FF33334)16
转为10进制
a+b=1.90000010
b-a=?
第一步:对阶
跟上面加法一样
第二步:尾数运算
1.10011001100110011001101
- 0.01001100110011001100110
1.01001100110011001100111
第三步:规格化
1.01001100110011001100111已经是个规格化数据了
第四步:舍入处理
由于在对阶时,Ma有右移,且第一次最高为1,第二次为0,所以按"0舍1入",尾数运算结果调整为 1.01001100110011001100110
第五步:溢出判断
没有溢出,阶码不调整,所以最后的结果为
a-b=(0 01111111 01001100110011001100110)2=(0011 1111 1010 0110 0110 0110 0110 0110)2=(3FA66666)16
转为10进制