集合框架

集合相关面试题
1、List接口、Set接口、Map接口的区别
List接口是可排序的,可重复的,可单独访问的
Set接口是不可重复,不可单独访问的
Map接口,是键值对,同时添加键和值,通过键访问
2、ArrayList和LinkedList的异同
相同点:
1)都实现List接口、可排序、重复、单独访问
2)所用方法的使用是一样的
不同点:
1)数据结构不同
ArrayList一维数组
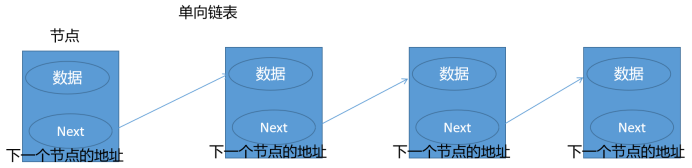
LinkedList是双向链表
2)性能不同
ArrayList
优点:查询速度快,数据是连续的,通过下标访问可以快速查找
缺点:插入和删除速度慢,因为要移动大量的数据
LinkedList
优点:插入和删除速度快,因为只需要修改上一个、下一个节点的地址
缺点:查询速度慢,因为需要一个个向后或向前查找
LinkedList在集合开头或结尾位置插入和删除比较快,在中间位置比较慢,因为定位中间位置需要大量时间,一般开发时查询的需求远大于插入和删除,一般情况下都使用ArrayList。
3、ArrayList和vector的异同
相同点:
数据结构和用法相同
不同点:
ArrayList是非线程同步(不上锁)的,适合单线程使用
Vector是线程同步(上锁)的,适合多线程使用
注:线程同步会降低程序性能,ArrayList性能高于 Vector
4、ArrayList的源码
数据结构是什么?
一维数组
是如何扩容的?
private void grow(int minCapacity) {
// 获得原来数组长度
int oldCapacity = elementData.length;
//oldCapacity >> 1相当于除以2,新容量是原来容量的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 把旧数组的数据复制到新数组中,用新数组替换旧数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
HashMap相关:
HashMap的基本用法:
添加:put(键,值)
取值:get(键)
将自定义类型作为键:
练习:
定义司机类,属性:姓名,年龄,性别
定义汽车类,属性:品牌,颜色,价格
创建HashMap集合,将司机作为键,汽车作为值,添加到集合中
测试通过司机对象查找他的汽车
问题:默认情况下,Map集合是通过键的内存地址来查找值的,如何通过键的对象的属性来查找值,而不是键的内存地址查找。
解决方法:
给作为键的类重写:
hashCode:返回一个整数,该整数是由对象的属性值计算出来的
equals:返回当前对象和参数是否相等(默认是比较内存地址),重写之后就比较属性值,当属性值相同时,也可以查找到对应的值。
注意:作为Map的键,必须要重写hashCode和equals方法
HashMap的内部原理
数据结构:
一维数组 + 单向链表
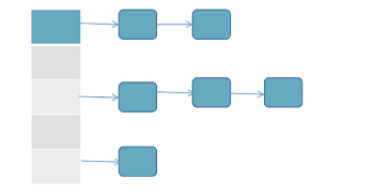
优点:数组的查找速度快,操作方便(一维数组),可能会出现哈希碰撞用链表结构便于数据的存储(链表)
如何来保存数据的:
1)计算键的hashCode返回一个整数值,用该整数算出一个数组的下标
2)通过下标找到数组上的数据(键值对)
哈希碰撞(通过不同的属性值算出同一个整数)
3)如果该位置上没有数据,直接将新数据添加到该位置
4)如果该位置上存在数据,将已有数据的键和新加数据的键调用equals方法进行比较
5)如果equals返回true,将新的值覆盖原来的值
6)如果equals返回false,将新的键放到原来键的后面,直到末尾
HashMap的扩容:
负载因子(以存放数据的个数和数组长度 的比例)
默认是0.75
如果存放数据的比列超过负载因子,会创建新的数组,将原有的数据复制过去,新数组的长度是原来数组的两倍。
Map集合补充
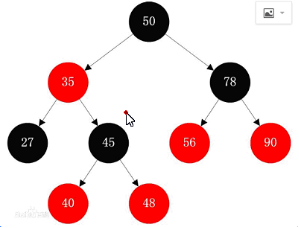
★★★ TreeMap
特点:键会自动排序
数据结构:键是红黑二叉树
TreeMap能够添加自定义类型的数据?
默认情况会出现ClassCastException
添加的自定义类型必须实现Comparable接口
Comparable接口提供比较的方法,用于支持默认的排序操作
int comparaTo(T t)提供比较大小的规则,该方法会在排序时自动调用
返回值用于指定两个值的大小
正数:当前对象大于参数对象
负数:当前对象小于参数对象
0:相等
注意:compara To返回0,数据不能添加到集合
★★★ LinkedHashMap
特点:能够保留键的原始添加顺序
数据结构:
在HashMap的一维数组+单向链表的基础上,新加了一个单向链表,新加的单向链表用于保持添加的顺序
★★★ Hashtable
面试题:
HashMap和Hashtable的区别:
1)Hashtable是线程安全的,HashMap是非线程安全的
2)HashMap的性能高于Hashtable
3)HashMap能够添加null作为键和值,Hashtable不能
★★★ ConcurrentHashMap:JDK 1.5出现,目的是替换Hashtable
concurrent:并发(多线程同时访问)
面试题 :ConcurrentHashMap和Hashtable的区别?
1)Hashtable锁整个集合
2)ConcurrentHashMap使用分段锁,锁集合的一部分数据
3)ConcurrentHashMap的效率要高于Hashtable
Set集合补充
HashSet中添加数据,必须实现hashCode和equals方法
HashSet中封装了HashMap,数据添加在HashMap的键中
TreeSet
添加数据可以自动排序,必须实现Comparable接口
Lambda表达式:jdk1.8的新特性
是一种语法糖,可以提高开发效率。
主要用于实现接口,编写比较简洁的代码。
只能实现函数式接口,函数式接口就是接口中只有一个方法需要实现
语法:
(参数名,参数名...)-> {代码实现}
或
(参数名,参数名...)->值,这个值相当于return值
集合操作:
集合排序:
可以使用list中的sort(Comparator<T>)方法实现
Comparator接口是比较器接口,主要指定两个对象比较的规则
int compara(T t1, T t2);
返回正数:t1> t2
返回负数: t1< t2
返回0:相等
该接口是函数式接口可以使用lambda表达式
集合遍历:
在jdk1.8之后,Collection接口新加方法forEach对集合进行遍历
forEach(Consumer c)
Consumer接口
void accept(T t);
集合.forEach(Lambda表达式)
集合筛选:
JDK1.8退出新工具接口:Stream,提供各种操作集合的方法
可以流式操作:对象.方法1().方法2()...
筛选方法:
Stream filter (Predicate p)
Predicate 接口是函数式的
语法:集合.Stream().filter.方法1().方法2()...
筛选之后的集合的收集:
调用Stream的collect方法
收集的集合 collect(Collect c)
说明:方法的参数是收集器Collectors
Collector的静态方法
toList()
toSet()
toMap()
例如:将筛选之后的对象放到新的集合中,limit限制收集对象的个数
List<Car> cars =list.stream()
.filter((y)->y.getPrice()>700000)
.limit(1)
.collect(Collectors.toList());
集合求最值:
Stream的max方法
最大值对象 = 对象.Stream().max(lambda表达式实现)
Car max = list.stream().max((t1,t2)->{
if (t1.getPrice()>t2.getPrice()) {
return 1;
}else if(t1.getPrice()<t2.getPrice()){
return -1;
}
return 0;
}).get();
System.out.println("最贵的汽车:"+max);