字典
Why:咱们目前已经学习到的容器型数据类型只有list,那么list够用?他有什么缺点呢?
1. 列表可以存储大量的数据类型,但是如果数据量大的话,他的查询速度比较慢。
2. 列表只能按照顺序存储,数据与数据之间关联性不强。
所以针对于上的缺点,说咱们需要引入另一种容器型的数据类型,解决上面的问题,这就需要dict字典。
what:
数据类型可以按照多种角度进行分类,就跟咱们人一样,人按照地域可以划分分为亚洲人,欧洲人,美洲人等,但是按照肤色又可以分为白种人,黄种人,黑种人,等等,数据类型可以按照不同的角度进行分类,先给大家按照可变与不可变的数据类型的分类:
不可变(可哈希)的数据类型:int,str,bool,tuple。
可变(不可哈希)的数据类型:list,dict,set。
字典是Python语言中的映射类型,他是以{}括起来,里面的内容是以键值对的形式储存的:
Key: 不可变(可哈希)的数据类型.并且键是唯一的,不重复的。
Value:任意数据(int,str,bool,tuple,list,dict,set),包括后面要学的实例对象等。
在Python3.5版本(包括此版本)之前,字典是无序的。
在Python3.6版本之后,字典会按照初建字典时的顺序排列(即第一次插入数据的顺序排序)。
当然,字典也有缺点:他的缺点就是内存消耗巨大。
字典查询之所以快的解释:(了解)
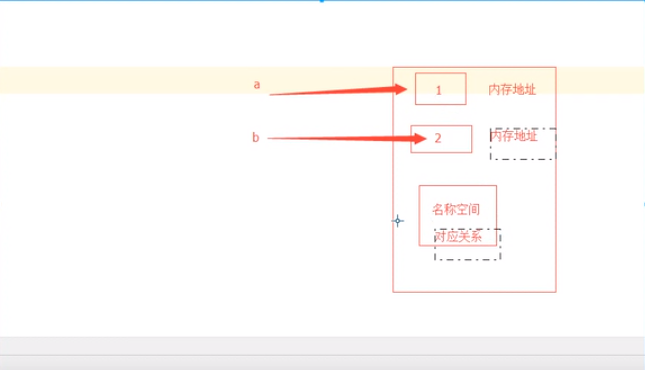
字典的查询速度非常快,简单解释一下原因:字典的键值对会存在一个散列表(稀疏数组)这样的空间中,每一个单位称作一个表元,表元里面记录着key:value,如果你想要找到这个key对应的值,先要对这个key进行hash获取一串数字咱们简称为门牌号(非内存地址),然后通过门牌号,确定表元,对比查询的key与被锁定的key是否相同,如果相同,将值返回,如果不同,报错。(这里只是简单的说一下过程,其实还是比较复杂的。),下面我已图形举例:

''' #数据类型划分:可变数据类型,不可变数据类型 不可变数据类型:元组,bool int str 可哈希 可变数据类型:list,dict set 不可哈希 dict key 必须是不可变数据类型,可哈希, value:任意数据类型。 dict 优点:二分查找去查询 存储大量的关系型数据 特点:无序的 #55 #20 #60 #40 #50 #55 ''' dic = { 'name':['大猛','小孟'], 'py9':[{'num':71, 'avg_age':18,}, {'num': 71, 'avg_age': 18, }, {'num': 71, 'avg_age': 18, }, ], True:1, (1,2,3):'wuyiyi', 2:'二哥', } print(dic) dic1 = {'age': 18, 'name': 'jin', 'sex': 'male',} #增: dic1['high'] = 185 #没有键值对,添加 dic1['age'] = 16 #如果有键,则值覆盖 dic1.setdefault('weight') # 有键值对,不做任何改变,没有才添加。 dic1.setdefault('weight',150) dic1.setdefault('name','二哥') print(dic1) #删 print(dic1.pop('age')) # 有返回删除键对应的值,按键去删除 print(dic1.pop('二哥',None)) # 可设置没有键时返回值,不然会出现报错 print(dic1) print(dic1.popitem()) # 随机删除 有返回值(元组)里面是删除的键值。 3.6+默认按最后一个删除 # print(dic1) del dic1['name'] print(dic1) #del dic1 #print(dic1) # dic1.clear() #清空字典 #改 update dic1['age'] = 16 dic = {"name":"jin","age":18,"sex":"male"} dic2 = {"name":"alex","weight":75} dic2.update(dic) #把dic覆盖添加到dic2 print(dic) print(dic2) dic1 = {'age': 18, 'name': 'jin', 'sex': 'male',} #查 print(dic1.keys(),type(dic1.keys())) # dict_keys(['age', 'name', 'sex']) <class 'dict_keys'> print(dic1.values()) # dict_values([18, 'jin', 'male']) print(dic1.items()) # dict_items([('age', 18), ('name', 'jin'), ('sex', 'male')]) for i in dic1: # 默认打出键值 print(i) for i in dic1.keys(): print(i) for i in dic1.values(): print(i) a,b = 1,2 print(a,b) a = 1 b = 2
print(id(a), id(b))
a,b = b,a #a,b 值互换
print(id(a), id(b))
print(a,b)
a,b = [1,2],[2,3]
print(a, b) a,b = (1,2) print(a,b)
for k,v in dic1.items():
print(k,v)
for k,v in dic1.items(): print(k,v) v1 = dic1['name'] print(v1) #v2 = dic1['name1'] # 报错 #print(v2) print(dic1.get('name1','没有这个键')) dic = { 'name':['alex','wusir','taibai'], 'py9':{ 'time':'1213', 'learn_money':19800, 'addr':'CBD', }, 'age':21 } dic['age'] = 56 print(dic['name']) dic['name'].append('ritian') l = [1,2,'wusir'] l[2] = l[2].upper() dic['name'][1] = dic['name'][1].upper() print(dic) #female : 6 dic['py9']['female'] = 6 print(dic) # fhdklah123rfdj12fdjsl3 ' 123 12 13' info = input('>>>').strip() for i in info: if i.isalpha(): info = info.replace(i," ") l = info.split() #['342', '34']
print(len(l))
# 14,补充代码(从已有的代码下面继续写):(6分) # 有如下值li= [11,22,33,44,55,77,88,99,90],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。 # li = [11,22,33,44,55,77,88,99,90] # result = {} # for row in li: # ...... # li = [11,22,33,44,55,77,88,99,90] # result = {'k1':[],'k2':[]} # for i in li: # if i > 66: # result['k1'].append(i) # elif i == 66: # pass # else: # result['k2'].append(i) # print(result) # 或者(有的话,直接添加,没有的话,创建一个在添加) # li = [11,22,33,44,55,77,88,99,90] # result = {} # for row in li: # if row > 66: # if 'key1' not in result: # result['key1'] = [] # result['key1'].append(row) # if row < 66: # if 'key2' not in result: # result['key2'] = [] # result['key2'].append(row) # print(result)
- 太白金星老师
- 博客:https://www.cnblogs.com/jin-xin/
别人能做的事,你能做的更好。