第 7 章HBase 优化
7.1 高可用
1.关闭 HBase 集群(如果没有开启则跳过此步)
[lxl@hadoop102 hbase]$ bin/stop-hbase.sh
2.在 conf 目录下创建 backup-masters 文件
[lxl@hadoop102 hbase]$ touch conf/backup-masters
3.在 backup-masters 文件中配置高可用 HMaster 节点
[lxl@hadoop102 hbase]$ echo hadoop103 > conf/backup-masters
4.将整个 conf 目录 scp 到其他节点
[atguigu@hadoop102 hbase]$ scp -r conf/ hadoop103:/opt/module/hbase/ [atguigu@hadoop102 hbase]$ scp -r conf/ hadoop104:/opt/module/hbase/
[lxl@hadoop102 hbase]$ xsync conf/backup-masters
5.启动hbase:
[lxl@hadoop102 hbase]$ bin/start-hbase.sh
starting master, logging to /opt/module/hbase/logs/hbase-lxl-master-hadoop102.out
hadoop102: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-lxl-regionserver-hadoop102.out
hadoop104: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-lxl-regionserver-hadoop104.out
hadoop103: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-lxl-regionserver-hadoop103.out
hadoop103: starting master, logging to /opt/module/hbase/bin/../logs/hbase-lxl-master-hadoop103.out
[lxl@hadoop102 hbase]$ util.sh
================ lxl@hadoop102 ================
13040 HMaster
2868 NodeManager
2949 JobHistoryServer
13190 HRegionServer
3115 QuorumPeerMain
2460 NameNode
13535 Jps
2575 DataNode
================ lxl@hadoop103 ================
8562 Jps
8307 HMaster
2868 QuorumPeerMain
8229 HRegionServer
2407 ResourceManager
2268 DataNode
2525 NodeManager
================ lxl@hadoop104 ================
2384 SecondaryNameNode
8864 Jps
2484 NodeManager
8676 HRegionServer
2646 QuorumPeerMain
2279 DataNode
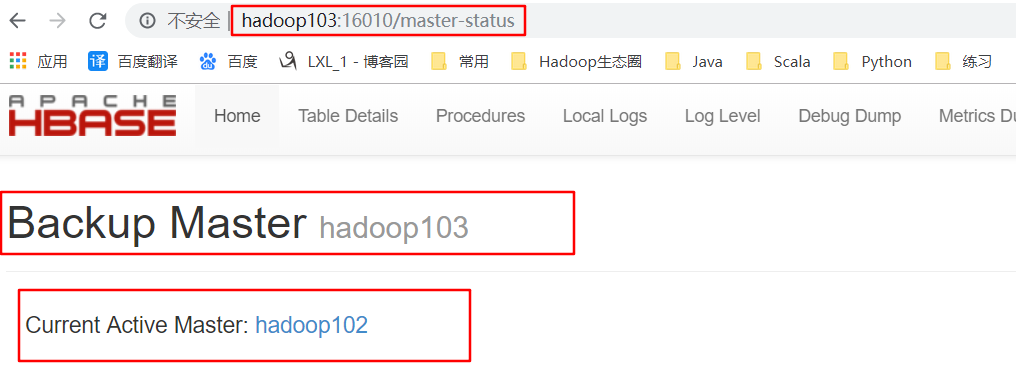
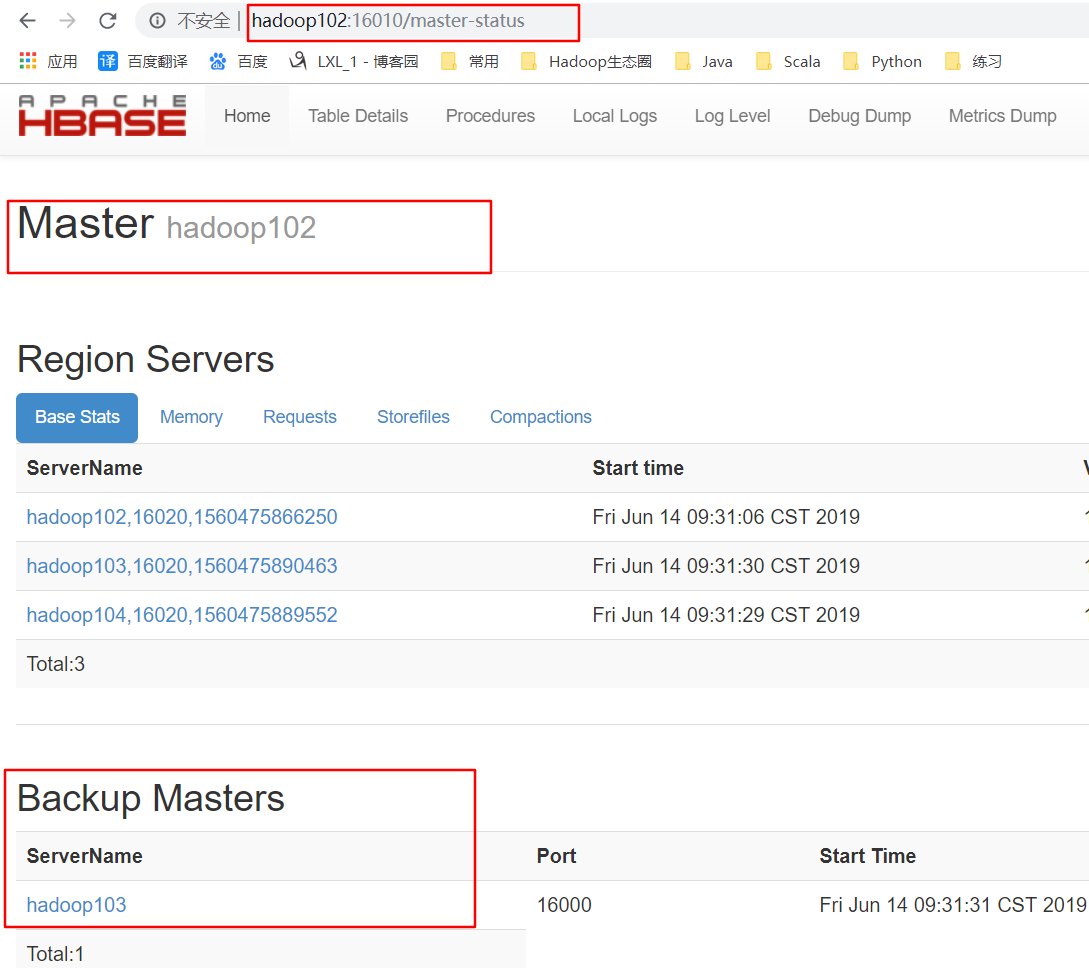
6.打开页面测试查看
http://hadooo102:16010
7.2 预分区
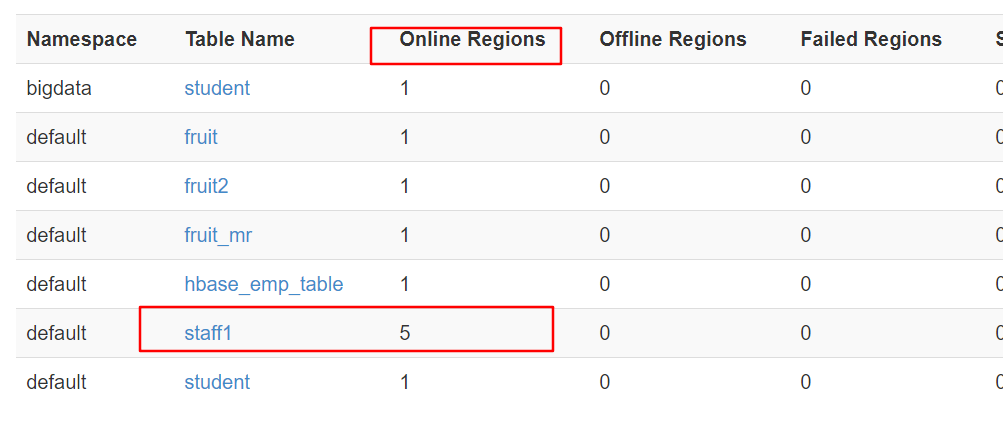
1.手动设定预分区
hbase> create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']

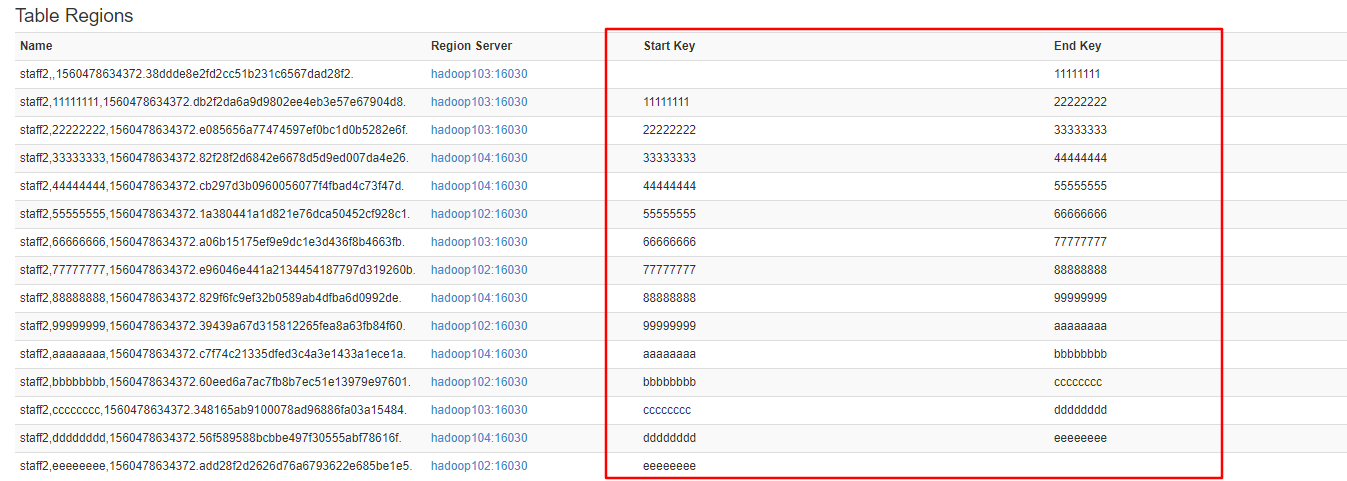
2.生成 16 进制序列预分区
hbase(main):002:0> create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
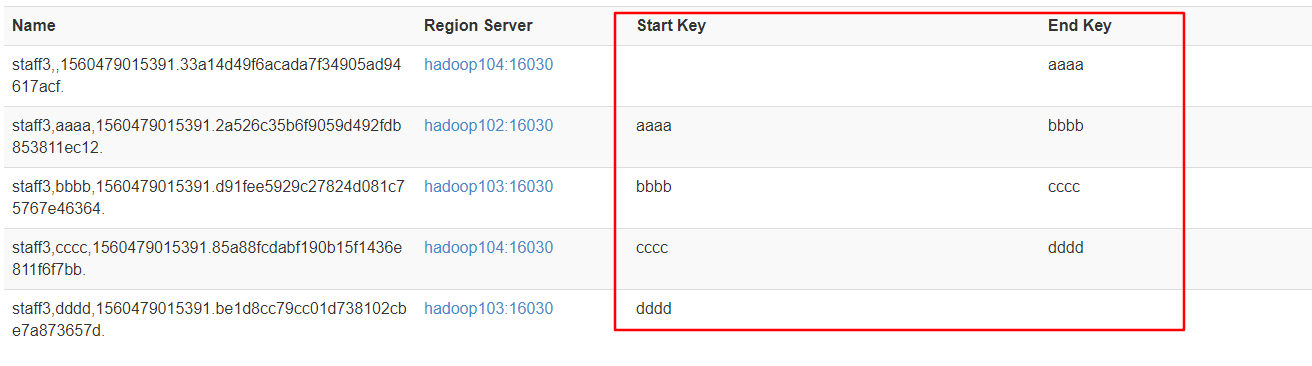
3.按照文件中设置的规则预分区
aaaa
dddd
cccc
bbbb

hbase(main):003:0> create 'staff3','partition3',SPLITS_FILE => 'splits.txt'
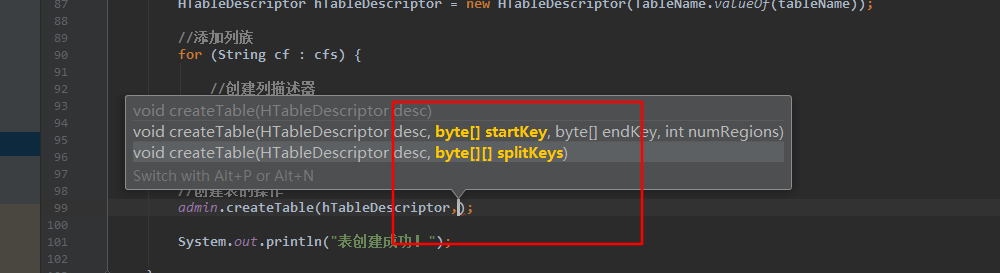
4.使用 JavaAPI 创建预分区
//自定义算法,产生一系列 Hash 散列值存储在二维数组中 byte[][] splitKeys = 某个散列值函数 //创建 HBaseAdmin 实例 HBaseAdmin hAdmin = new HBaseAdmin(HBaseConfiguration.create()); //创建 HTableDescriptor 实例 HTableDescriptor tableDesc = new HTableDescriptor(tableName); //通过 HTableDescriptor 实例和散列值二维数组创建带有预分区的 HBase 表 hAdmin.createTable(tableDesc, splitKeys);
7.3 RowKey 设计
1.生成随机数、hash、散列值
比如: 原 本 rowKey 为 1001 的 , SHA1 后变成: dd01903921ea24941c26a48f2cec24e0bb0e8cc7 原 本 rowKey 为 3001 的 , SHA1 后变成: 49042c54de64a1e9bf0b33e00245660ef92dc7bd 原 本 rowKey 为 5001 的 , SHA1 后变成: 7b61dec07e02c188790670af43e717f0f46e8913 在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的 rowKey 来 Hash 后作为每个分区的临界值。
2.字符串反转
20170524000001 转成 10000042507102 20170524000002 转成 20000042507102
3.字符串拼接
20170524000001_a12e
20170524000001_93i7
7.4 内存优化
7.5 基础优化
1.允许在 HDFS 的文件中追加内容
属性:dfs.support.append 解释:开启 HDFS 追加同步,可以优秀的配合 HBase 的数据同步和持久化。默认值为 true。
2.优化 DataNode 允许的最大文件打开数
属性:dfs.datanode.max.transfer.threads 解释:HBase 一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作,//合并文件或者刷写的时候会操作大量的文件 设置为 4096 或者更高。默认值:4096 //需要看集群的大小而定
3.优化延迟高的数据操作的等待时间
属性:dfs.image.transfer.timeout 解释:如果对于某一次数据操作来讲,延迟非常高,socket 需要等待更长的时间,建议把 该值设置为更大的值(默认 60000 毫秒),以确保 socket 不会被 timeout 掉。
4.优化数据的写入效率
属性: mapreduce.map.output.compress mapreduce.map.output.compress.codec 解释:开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为 true,第二个属性值修改为:org.apache.hadoop.io.compress.GzipCodec 或者 其他压缩方式。
5.设置 RPC 监听数量
属性:hbase.regionserver.handler.count 解释:默认值为 30,用于指定 RPC 监听的数量,可以根据客户端的请求数进行调整,读写 请求较多时,增加此值。
6.优化 HStore 文件大小
属性:hbase.hregion.max.filesize 解释:默认值 10737418240(10GB),如果需要运行 HBase 的 MR 任务,可以减小此值, 因为一个 region 对应一个 map 任务,如果单个 region 过大,会导致 map 任务执行时间 过长。该值的意思就是,如果 HFile 的大小达到这个数值,则这个 region 会被切分为两 个 Hfile。
7.优化 hbase 客户端缓存
属性:hbase.client.write.buffer 解释:用于指定 HBase 客户端缓存,增大该值可以减少 RPC 调用次数,但是会消耗更多内 存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少 RPC 次数的目的。
8.指定 scan.next 扫描 HBase 所获取的行数
属性:hbase.client.scanner.caching
解释:用于指定 scan.next 方法获取的默认行数,值越大,消耗内存越大。
9.flush、compact、split 机制
<!-- 一个store里面允许存的hfile的个数,超过这个个数会被写到新的一个hfile里面 也即是每个region的每个列族对应的memstore在fulsh为hfile的时候,默认情况下当超过3个hfile的时候就会 对这些文件进行合并重写为一个新文件,设置个数越大可以减少触发合并的时间,但是每次合并的时间就会越长 --> <property> <name>hbase.hstore.compactionThreshold</name> <value>3</value> <description> If more than this number of HStoreFiles in any one HStore (one HStoreFile is written per flush of memstore) then a compaction is run to rewrite all HStoreFiles files as one. Larger numbers put off compaction but when it runs, it takes longer to complete. </description> </property> <!-- 每个minor compaction操作的 允许的最大hfile文件上限 --> <property> <name>hbase.hstore.compaction.max</name> <value>10</value> <description>Max number of HStoreFiles to compact per 'minor' compaction.</description> </property> <!-- regionServer的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionserver级别的 flush会阻塞客户端读写 --> <property> <name>hbase.regionserver.global.memstore.size</name> <value></value> <description>Maximum size of all memstores in a region server before new updates are blocked and flushes are forced. Defaults to 40% of heap (0.4). Updates are blocked and flushes are forced until size of all memstores in a region server hits hbase.regionserver.global.memstore.size.lower.limit. The default value in this configuration has been intentionally left emtpy in order to honor the old hbase.regionserver.global.memstore.upperLimit property if present. </description> </property> <!-- 内存中的文件在自动刷新之前能够存活的最长时间,默认是1h --> <property> <name>hbase.regionserver.optionalcacheflushinterval</name> <value>3600000</value> <description> Maximum amount of time an edit lives in memory before being automatically flushed. Default 1 hour. Set it to 0 to disable automatic flushing. </description> </property> <!-- 单个region里memstore的缓存大小,超过那么整个HRegion就会flush,默认128M --> <property> <name>hbase.hregion.memstore.flush.size</name> <value>134217728</value> <description> Memstore will be flushed to disk if size of the memstore exceeds this number of bytes. Value is checked by a thread that runs every hbase.server.thread.wakefrequency. </description> </property>