1 Spark 概述
1.1 什么是 Spark

1.2 Spark 内置模块
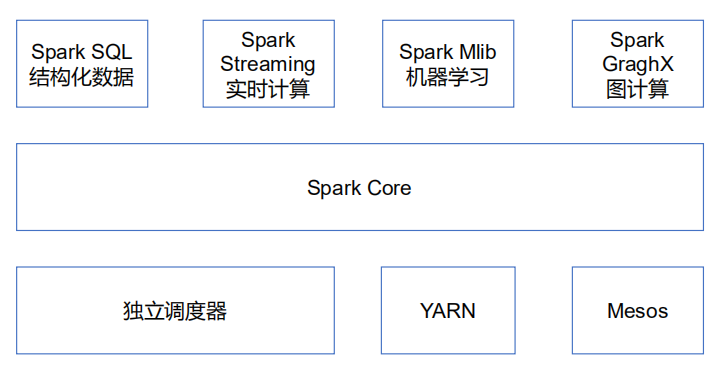
Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储
系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(Resilient Distributed
DataSet,简称 RDD)的 API 定义。
Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用
SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,
比如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数
据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同
过滤等,还提供了模型评估、数据 导入等额外的支持功能。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计
算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(Cluster
Manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度
器,叫作独立调度器。
Spark 得到了众多大数据公司的支持,这些公司包括 Hortonworks、IBM、Intel、
Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的
Spark 已应用于大搜索、直达号、百度大数据等业务;阿里利用 GraphX 构建了大规模的图
计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯 Spark 集群达到 8000 台的规
模,是当前已知的世界上最大的 Spark 集群。
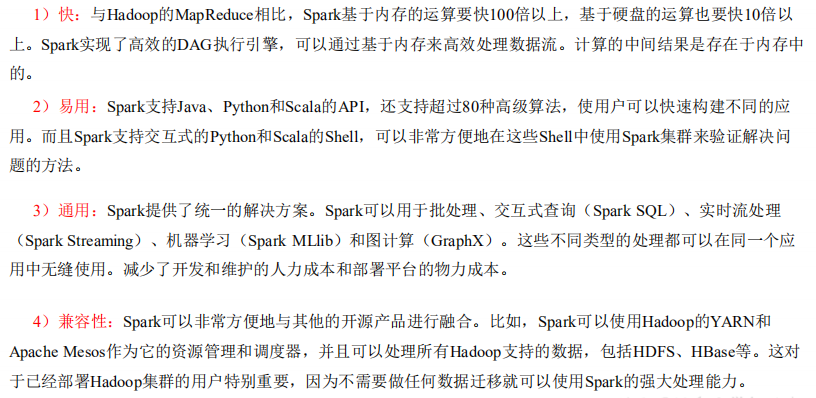
1.3 Spark 特点
2 Spark 运行模式
2.1 Spark 安装地址
1.官网地址
http://spark.apache.org/
2.文档查看地址
https://spark.apache.org/docs/2.1.1/
3.下载地址
https://spark.apache.org/downloads.html
2.3 Local 模式
2.3.1 概述

2.3.2 安装使用
1)上传并解压 spark 安装包
[lxl@hadoop102 sorfware]$ tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/ [lxl@hadoop102 module]$ mv spark-2.1.1-bin-hadoop2.7 spark
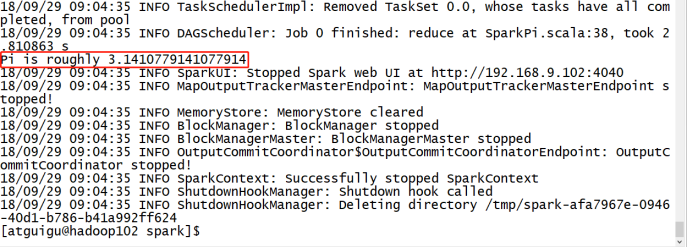
2)官方求 PI 案例
[lxl@hadoop102 spark]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --executor-memory 1G --total-executor-cores 2 ./examples/jars/spark-examples_2.11-2.1.1.jar 100
(1)基本语法
bin/spark-submit --class --master --deploy-mode --conf = ... # other options [application-arguments]
(2)参数说明:
--master 指定 Master 的地址,默认为 Local --class: 你的应用的启动类 (如 org.apache.spark.examples.SparkPi) --deploy-mode: 是否发布你的驱动到 worker 节点(cluster) 或者作为一个本地客户端 (client) (default: client)* --conf: 任意的 Spark 配置属性, 格式 key=value. 如果值包含空格,可以加引号 “key=value” application-jar: 打包好的应用 jar,包含依赖. 这个URL 在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path 都包含同样的 jar application-arguments: 传给 main()方法的参数 --executor-memory 1G 指定每个 executor 可用内存为 1G --total-executor-cores 2 指定每个 executor 使用的 cup 核数为 2 个
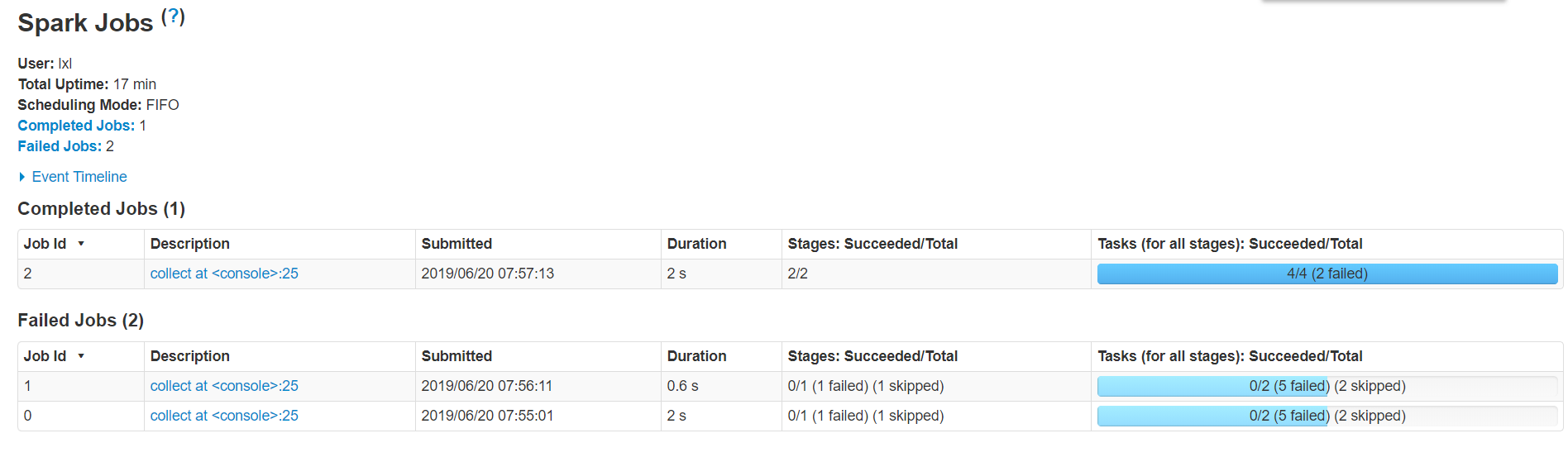
3) 结果展示
该算法是利用蒙特·卡罗算法求PI
4)准备文件
[lxl@hadoop102 spark]$ mkdir input
在 input 下创建 3 个文件 1.txt 和 2.txt,并输入以下内容
hello atguigu
hello spark
5)启动 spark-shell
[lxl@hadoop102 spark]$ bin/spark-shell
scala>
开启另一个 CRD 窗口
[lxl@hadoop102 ~]$ jps 2421 Worker 2551 SparkSubmit 2632 CoarseGrainedExecutorBackend 2333 Master 2703 Jps
可登录 hadoop102:4040 查看程序运行:
6)运行 WordCount 程序
scala>sc.textFile("input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect res2: Array[(String, Int)] = Array((hive,3), (oozie,3), (spark,3), (hadoop,6), (hbase,3))
可登录 hadoop102:4040 查看程序运行