论文地址:MelGAN:条件波形合成的生成对抗网络
代码地址:https://github.com/descriptinc/melgan-neurips
音频实例:https://melgan-neurips.github.io/
配有MelGAN解码器的音乐翻译网络:https://www.descript.com/overdub
摘要
以前的工作(Donahue等人,2018a;Engel等人,2019a)已经发现用GAN生成相干的原始音频波形是一个挑战。在本文中,我们证明了通过引入一系列结构变化和简单的训练技术,可以可靠地训练GANs以产生高质量的相干波形。主观评价指标(Mean-Opinion Score,简称MOS)表明了该方法对高质量mel谱图inversion(反推)的有效性。为了建立这些技术的通用性,我们展示了我们的模型在语音合成、音乐领域翻译和无条件音乐合成方面的定性结果。我们通过烧蚀研究来评估模型的各个组成部分,并提出一套指导方针来设计条件序列合成任务的通用鉴别器和生成器。我们的模型是非自回归的,完全卷积的,参数明显少于竞争模型,并且可以推广到看不见的说话者进行梅尔谱图反演。我们的Pytorch实现在GTX1080Ti GPU上的运行速度比实时快100倍以上,在CPU上比实时运行快2倍以上,而没有任何针对硬件的优化技巧。
1、引言
建模原始音频是一个特别具有挑战性的问题,因为数据时间分辨率很高(通常至少16000个样本每秒),并且在不同的时间尺度上存在短期和长期的依赖关系。因此,与其直接建模原始时间音频,大多数方法通常对原始时间信号更低分辨率音频建模来简化问题。通常选择这样的表示形式比原始音频更容易建模,同时保留足够的信息以允许准确地倒转回音频。在言语方面,对齐的语言特征(Van Den Oord等人,2016)和mel-spectograms (Shen等人,2018;Gibiansky等人,2017)是两种常用的中间表示。因此,音频建模通常被分解为两个阶段。
- 将文本转换成一种中间特征表示,然后对这种特征进行建模。
- 将中间表示法转换回音频。
在本研究中,我们关注的是后一阶段,并选择mel-spectogram作为中间表征。目前的mel-spectogram反演方法可以分为三类:
- 纯信号处理技术
- 自回归神经网络
- 非自回归神经网络
我们将在接下来的段落中描述这三种主要的研究方向。
纯信号处理方法
不同的信号处理方法已被探索,以找到一些方便的低分辨率音频表示,既可以容易地建模和有效地转换回时间音频。例如,Griffin-Lim(Griffin&Lim,1984)算法允许有效地将STFT序列解码回时域信号,代价是引入较强的机器人伪像,如Wang等人所述(2017)。目前已经研究了更复杂的表示和信号处理技术。例如,WORLD声码器(MORISE et al,2016)引入了一种中间类表示形式,专门针对基于类似于mel频谱图的特征的语音建模而设计。 WORLD声码器与专用信号处理算法配对,以将中间表示映射回原始音频。 它已成功用于进行文本到语音的合成,例如在Char2Wav中,其中WORLD声码器功能通过基于注意力的递归神经网络进行建模(Sotelo等,2017; Shen等,2018; Ping 等人,2017)。 这些纯信号处理方法的主要问题在于,从中间特征到音频的映射通常会引入明显的伪像。
基于自回归神经网络的模型
WaveNet (Van Den Oord等人,2016)是一种全卷积自回归序列模型,可以根据与原始音频时间一致的语言特征生成高度真实的语音样本。它也能够产生高质量的无条件语音和音乐样本。SampleRNN (Mehri等人,2016)是一种实现无条件波形生成的替代架构,它使用多尺度递归神经网络在不同时间分辨率上显式地为原始音频建模。WaveRNN (Kalchbrenner et al., 2018)是一种基于简单的单层递归神经网络的更快的自回归模型。WaveRNN引入了各种技术,如稀疏化和子尺度生成,以进一步提高合成速度。这些方法已经在文本到语音合成(Sotelo et al., 2017; Shen et al., 2018; Ping et al., 2017)和其他音频生成任务(Engel et al., 2017)中取得了最先进的成果。不幸的是,由于音频样本必须按顺序生成,因此使用这些模型进行推理的速度天生就很慢且效率低下。因此,自回归模型通常不适合实时应用。
非自回归模型
近来,人们致力于开发非自回归模型以反转低分辨率音频表示。这些模型比自回归模型快几个数量级,因为它们具有高度可并行性,并且可以充分利用现代深度学习硬件(例如GPU和TPU)。现在已经出现了两种不同的方法来训练这种模型。
1.)Parallel Wavenet(Oord等人,2017)和Clarinet(Ping等人,2018)将经过训练的自回归解码器提炼成基于流的卷积学生模型。使用基于Kulback-Leibler散度KL$KL[P_{student}||P_{teacher}]$以及其他感知损失项的概率蒸馏目标对学生进行了训练。
2.)WaveGlow(Prenger等人,2019)是基于流的生成模型,基于Glow(Kingma&Dhariwal,2018)。 WaveGlow是一种非常高容量的生成流,它由12个耦合和12个可逆1x1卷积组成,每个耦合层由8层扩张卷积的堆栈组成。作者指出,需要为期8周的GPU培训,才能获得单个扬声器模型的高质量结果。尽管在GPU上推理速度很快,但是模型的庞大尺寸使其对于内存预算有限的应用程序不切实际。
GANs for audio
到目前为止,尚未针对音频建模探索的一种方法是生成对抗网络(GAN)(Goodfellow et al,2014)。 GAN在无条件图像生成(Gulrajani等,2017; Karras等,2017,2018),图像到图像翻译方面(Isola等,2017; Zhu等,2017; Wang等2018b)和视频到视频合成(Chan等人,2018; Wang等人,2018a)取得了稳步进展。尽管它们在计算机视觉方面取得了巨大的成功,但在使用GAN进行音频建模方面,我们还没有看到多少进展。Engel等人(2019b)使用GAN通过模拟STFT幅度和相位角来生成音乐音色,而不是直接模拟原始波形。 Neekhara等(2019)提出使用GANs来学习从梅尔频谱图到简单幅度频谱图的映射,并将其与相位估计相结合,恢复原始音频波形。Yamamoto等人(2019)使用GAN提取自回归模型,生成原始语音音频,但是他们的结果表明仅对抗损失不足以产生高质量的波形;它需要基于KL散度的蒸馏目标作为一个关键组成部分。迄今为止,使它们在此领域中良好运行一直是一项挑战(Donahue等,2018a)。
主要贡献
- 我们提出了MelGAN,一个非自回归前馈卷积架构,用于在GAN设置中生成音频波形。 据我们所知,这是第一项成功培训GAN的原始音频生成工作,而没有额外的蒸馏或感知损失功能,同时仍能产生高质量的文本到语音合成模型的第一项工作。
- 通过在通用音乐翻译、文本到语音的生成和无条件音乐合成方面的实验,我们证明了自回归模型可以很容易地用快速并行的MelGAN解码器代替,尽管质量会有轻微的下降。
- 我们还表明,MelGAN大大快于其他mel-spectrogram反演方案。特别是,它比目前最快的型号快10倍(Prenger et al,2019),而且音频质量没有明显下降。
2、MelGAN模型
在这一节中,我们描述我们的mel-spectrogram反演的生成器和鉴别器架构。我们描述了模型的核心组件,并讨论了执行无条件音频合成的修改。我们在参数数量和在CPU和GPU上的推理速度方面,将提出的模型与竞争方法进行了比较。 图1显示了整体架构。
2.1 生成器
架构
我们的生成器是一个完全卷积的前馈网络,输入的信号为梅尔谱图,输出的原始波形为x。由于梅尔谱图在256x的时间分辨率上(用于所有实验),因此我们使用一维转置卷积层对输入序列进行上采样。 每个转置的卷积层后面是一堆带有扩张卷积的残差块。 与传统的GAN不同,我们的生成器不使用全局噪声矢量作为输入。 我们在实验中注意到,当额外的噪声馈入发生器时,生成的波形几乎没有感知差异。 这是违反直觉的结果,因为$s --> x$的求逆涉及到一个一对多的映射,因为s是x的有损压缩。 但是,这一发现与Mathieu等人的观点一致。 (2015)和Isola等(2017),这表明如果条件信息非常强,则噪声输入并不重要。
感应感受野(Induced receptive field)
在基于卷积神经网络的图像生成器中,由于感应接受域的高度重叠,空间上靠近的像素点之间存在一种感应偏差。 我们设计的生成器架构,以产生一个感应偏置,即音频时间步长之间存在长距离相关性。我们在每个上采样层之后添加了带有扩张的残差块,这样在时间上,后续每一层的输出激活都有明显的输入重叠。 一叠扩展卷积层的接受场随层数的增加而指数增加。 与Van Den Oord等类似(2016年),将这些纳入我们的生成器使我们能够有效地增加每个输出时间步长的感应接收场。 这有效地暗示了相距较远的时间步长的感应接收场中存在较大的重叠,从而产生更好的长距离相关性。
Checkerboard artifacts
正如Odena等人(2016年)所指出的,如果未仔细选择转置卷积层的内核大小和步幅,则反卷积生成器很容易生成“棋盘格”模式。 Donahue等人(2018b)对原始波形生成进行了研究,发现这种重复的模式会导致可听到的高频嘶嘶声。 为了解决这个问题,我们仔细选择反卷积层的内核大小和步幅,作为Donahue等人(2018b)中引入的PhaseShuffle层的一个更简单的替代方案。 跟随Odena等人(2016),我们使用内核大小作为跨步的倍数。 如果未正确选择扩张和内核大小,则这种重复模式的另一个来源可能是扩张卷积堆栈。 我们确保扩展随核大小的增长而增长,这样堆栈的接受域看起来就像一个完全平衡的(均匀地看到输入)和以内核大小作为分支因子的对称树。
标准化技术(Normalization technique)
我们注意到,生成器结构总选择归一化技术对于样品质量至关重要。用于图像生成的常用条件GAN架构(Isola等人,2017;Wang等人,2018b)在生成器的所有层中使用实例归一化(instance Normalization, Ulyanov et al.2016)。但是,在音频生成的情况下,我们发现实例规范化会冲走重要的音高信息,使音频听起来具有金属感。根据Zhang等人和Park等人(2019)的建议,在生成器上应用频谱归一化(Miyato等人,2018)时,我们也获得了较差的结果。。我们认为,对鉴别器的强烈Lipshitz约束会影响用于训练生成器的特征匹配目标(在3.2节中进行了说明)。在所有可用的归一化技术中,权重归一化(Weight normalization)(Salimans和Kingma,2016)效果最好,因为它不会限制鉴别器的容量或对激活进行归一化。它只是通过将权重矢量的比例从方向上解耦来简单地重新参数化权重矩阵,从而获得更好的训练动力学。因此,我们在生成器的所有层中使用权重归一化。
2.2 鉴别器
多尺度结构(Multi-Scale Architecture)
在Wang et al. (2018b)之后,我们采用了具有3个鉴别器(D1、D2、D3)的尺度架构,这些鉴别器具有相同的网络结构,但在不同的音频尺度scale上运行。 D1操作在原始音频的尺度上,而D2; D3分别操作在原始音频下采样2倍和4倍的尺度上。 下采样是使用内核大小为4的strided average pooling。音频具有不同层次的结构,因此可以激发不同尺度的多个鉴别器。 这种结构具有感应偏差,每个鉴别器都可以学习音频不同频率范围的特征。 例如,对下采样音频进行操作的鉴别器无法访问高频分量,因此倾向于仅基于低频分量学习鉴别特征。
基于窗的目标(Window-based objective)
每个单独的鉴别器都是基于马尔可夫窗口的鉴别器(类似于图像修复,Isola等人(2017)),由一系列kernel size的跨步卷积层组成。我们利用分组卷积(grouped convolutions)来允许使用更大的内核,同时保持较小的参数数量。虽然标准GAN鉴别器学习在整个音频序列的分布之间进行分类,而基于窗的鉴别器学习在小音频块的分布之间进行分类。由于鉴别器损耗是在每个窗口都非常大(等于鉴别器的感受野)的重叠窗口上计算的,因此,MelGAN模型学习在各个块之间保持一致性。我们选择了基于窗的鉴别器,因为它们已经被证明可以捕获基本的高频结构,需要较少的参数,运行速度更快,并且可以应用于可变长度的音频序列。与生成器类似,我们在鉴别器的所有层中使用权重归一化。
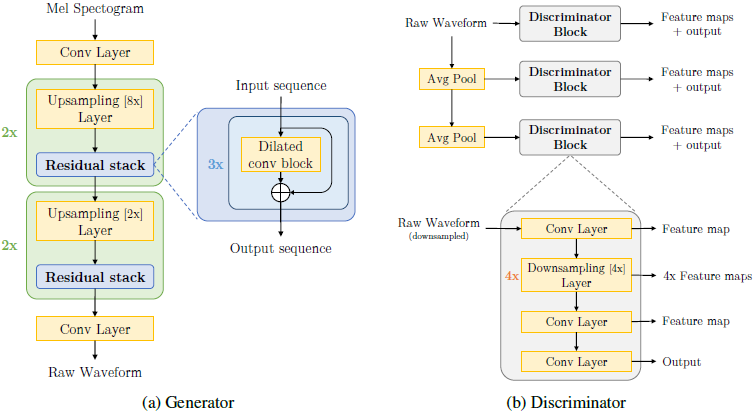
图1:MelGAN模型架构。 每个上采样层都是一个转置卷积,内核大小是步幅的两倍(与该层的上采样率相同)。256x上采样分为8x, 8x, 2x和2x上采样4个阶段。每个残差扩张卷积叠加有三个层,分别为扩张1、扩张3和扩张9,核大小为3,总感受野为27个时间步长。 我们使用leaky-relu进行激活。 每个判别器块具有4个步幅为4的步幅卷积。更多详细信息,请参见附录6。
2.3 训练目标
为了训练GAN,我们的GAN目标函数使用hinge损失版本 (Lim & Ye, 2017; Miyato et al., 2018)。我们还试验了最小二乘(LSGAN)公式(Mao et al.,2017),并注意到hinge版本有轻微改进。
$$公式1:\min _{D_{k}} \mathbb{E}_{x}\left[\min \left(0,1-D_{k}(x)\right)\right]+\mathbb{E}_{s, z}\left[\min \left(0,1+D_{k}(G(s, z))\right)\right], \forall k=1,2,3$$
$$公式2:\min _{G} \mathbb{E}_{s, z}\left[\sum_{k=1,2,3}-D_{k}(G(s, z))\right]$$
其中x表示原始波形,s表示条件信息(例如。mel-spectrogram)和z表示高斯噪声向量
特征匹配
除了鉴别器的信号外,我们使用特征匹配损失函数(Larsen等,2015)来训练生成器。 该目标最小化真实音频和合成音频的鉴别器特征图之间的L1距离。 直观的说,这可以看作是学习的相似性度量,一个鉴别器学习了一个特征空间,从而从真实数据中鉴别出假数据。 值得注意的是,我们没有使用任何损失的原始音频空间。 这与其他有条件的GAN(Isola等人,2017)相反,其中L1损失被用来匹配有条件生成的图像及其相应的ground-truths,以增强全局一致性。 实际上,在我们的案例中,在音频空间中增加L1损耗会引入可听噪声,从而损害音频质量。
$$公式3:\mathcal{L}_{\mathrm{FM}}\left(G, D_{k}\right)=\mathbb{E}_{x, s \sim p_{\text {data }}}\left[\sum_{i=1}^{T} \frac{1}{N_{i}}\left\|D_{k}^{(i)}(x)-D_{k}^{(i)}(G(s))\right\|_{1}\right]$$
为了简化符号,$D_k^{(i)}$表示第$k$个鉴别器块的第$i$层特征图输出,$N_i$表示第一层的单元数,特征匹配类似于感知损失(Dosovitskiy & Brox, 2016; Gatys et al., 2016; Johnson et al., 2016)。在我们的工作中,我们在所有鉴别块的每个中间层使用特征匹配。
$$公式4:\min _{G}\left(\mathbb{E}_{s, z}\left[\sum_{k=1,2,3}-D_{k}(G(s, z))\right]+\lambda \sum_{k=1}^{3} \mathcal{L}_{\mathrm{FM}}\left(G, D_{k}\right)\right)$$
2.4 参数数量和推理速度
在我们的体系结构中,归纳偏差使得整个模型在参数数量上明显小于竞争模型。由于是非自回归且完全卷积的模型,因此我们的模型推理速度非常快,能够在GTX1080 Ti GPU上以2500kHz的频率全精度运行(比最快的竞争模型快10倍以上),在CPU上达到50kHz(更多) 比最快的竞争机型快25倍)。 我们认为我们的模型也非常适合硬件特定的推理优化(例如Tesla V100的半精度(Jia等人,2018; Dosovitskiy&Brox,2016)和量化(如Arik等人(2017)所做的那样)),这将进一步提高推理速度,表1给出了详细的比较。
表1:参数数量和推理速度的比较。n kHz的速度意味着该模型可以每秒生成n*1000个原始音频样本。所有模型都使用相同的硬件进行基准测试

3 结果
为了鼓励重现性,我们在论文所附的代码中附加了代码:https://github.com/descriptinc/melgan-neurips。
3.1 Ground truth mel-spectrogram反演
烧蚀研究 首先,为了理解我们提出的模型的各个组成部分的重要性,我们对重建的音频进行了定性和定量分析,以完成声谱图反演任务。我们删除某些关键的体系结构决策,并使用测试集评估音频质量。表2显示了通过人类听力测试评估的音频质量的平均意见得分。每个模型在LJ语音数据集上进行了40万次迭代训练(Ito,2017)。我们的分析得出以下结论:生成器中没有扩展卷积堆栈或删除权重归一化会导致高频伪像。使用单个鉴别器(而不是多尺度鉴别器)会产生金属音频,尤其是在说话人呼吸时。此外,在我们内部的6个干净的说话人数据集上,我们注意到这个版本的模型跳过了某些浊音部分,完全丢失了一些单词。使用频谱归一化或去除基于窗口的鉴别器损失会使我们难以学习到清晰的高频模式,从而导致样本产生明显的噪声。在真实波形和生成的原始波形之间添加额外的L1惩罚,会使样本听起来像金属质感,并带有额外的高频伪像。
表2:消融研究的平均意见评分。为了评估由每个组件引起的偏差,我们一次移除一个组件,并对每个组件训练500个epoch的模型。评估方案/详情见附录B。

基准竞争模型 接下来,比较MelGAN在将ground truth mel-spectrograms转化为raw音频与现有方法(如WaveNet vocoder, WaveGlow, Griffin-Lim和ground truth audio)的性能,我们运行了一个独立的MOS测试,其中MelGAN 训练模型直到收敛(大约2.5M迭代)。 与消融研究类似,这些比较是在LJ语音Datset训练的模型上进行的。 比较结果如表3所示。
表3:平均意见得分
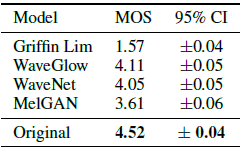
实验结果表明,MelGAN在质量上可与目前最先进的高容量基于波形的模型(如WaveNet和WaveGlow)相媲美。我们相信,通过进一步探索将GANs用于音频合成的这一方向,在未来可以迅速弥补这一性能差距。
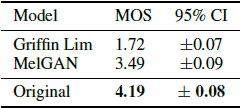
泛化到看不见的说话者
有趣的是,我们注意到,当我们在包含多个说话者的数据集上训练MelGAN时(内部6个说话者数据集由3个男性和3个女性说话者组成,每个说话者大约需要10个小时),结果模型能够推广到全新的(看不见的)说话者 在训练集外。 该实验验证了MelGAN是能够学习说话人不变的mel频谱图到原始波形的映射。
为了提供一个易于比较的指标来系统地评估这种泛化(针对当前和未来的工作),我们在公开的VCTK数据集上运行了MOS听力测试,用于实地梅尔谱图反演(Veaux等人,2017) 。 该测试的结果示于表4。
表4 VCTK数据集上的平均意见得分(Veaux et al., 2017)
3.2 端到端语音合成
我们在提出的MelGAN与竞争模型之间进行了定量和定性的比较,这些模型基于梅尔频谱图 inversion 用于端到端语音合成。 我们将MelGAN模型插入端到端语音合成管道(图2),并使用竞争模型评估文本到语音样本的质量。

图2:文本到语音的管道
具体来说,我们比较了使用MelGAN进行频谱图反转与使用Text2mel((开源char2wav模型的改进版本))的WaveGlow时的样品质量(Sotelo等人,2017)。 Text2mel生成mel-谱图,而不是声码器帧,使用音素作为输入表示,并可以与WaveGlow或MelGAN耦合来反转生成的mel-谱图。 我们使用此模型是因为它的采样器训练速度更快,并且不会像Tacotron2那样执行任何mel频率削波。 此外,我们还采用了最先进的Tacotron2模型(Shen et al., 2018)和WaveGlow进行基线比较。我们使用NVIDIA在Pytorch中心存储库中提供的Tacotron2和WaveGlow的开源实现来生成示例。在使用WaveGlow时,我们使用官方存储库中提供的强度为0:01的去噪器来删除高频工件。MOS测试结果如表5所示。
对于所有的实验,MelGAN都是在单个NVIDIA RTX2080Ti GPU上以批处理大小16进行训练的。我们用Adam作为优化器,对于生成器和鉴别器的学习率为1e-4,$\beta _1=0.5$且$\beta_2=0.9$。定性分析的样本可以在附呈的网页中找到。您可以尝试根据上述端到端语音合成管道在此处创建的语音校正应用程序。
结果表明,作为TTS管道的声码器组件,MelGAN可以与一些迄今为止性能最好的模型相媲美。为了更好地进行比较,我们还使用Text2mel + WaveNet声码器创建了一个TTS模型。我们使用Yamamoto(2019)提供的预训练过的WaveNet声码器模型,对Text2mel模型进行相应的数据预处理。然而,该模型获得的MOS评分仅为3.40+0.04。在我们所有的端到端TTS实验中,我们只在地面真值谱图上训练神经声码器,然后直接在生成的谱图上使用它。我们怀疑Text2Mel + WaveNet实验的糟糕结果可能是由于没有在生成的谱图上对WaveNet声码器进行校正(如在Tacotron2中所做的那样)。因此,我们决定不在表格中报告这些分数。
3.3 非自回归解码器的音乐翻译
为了证明MelGAN是健壮的,并且可以插入到目前使用自回归模型进行波形合成的任何设置中,我们用MelGAN生成器替换了通用音乐翻译网络(Mor等人,2019)中的wavenet-type自回归译码器。
在本实验中,我们使用作者提供的预训练的通用音乐编码器,将16kHz的原始音频转换为64通道的潜在码序列,在时间维上降低采样因子800。这意味着该域独立潜在表示的信息压缩率为12.5。仅使用来自目标音乐域的数据,我们的MelGAN解码器被训练来从我们前面描述的GAN设置中的潜在代码序列重建原始波形。我们调整模型的超参数,得到10,10,2,2,2的上采样因子,以达到输入分辨率。对于MusicNet上的每个选定域(Thickstun et al.,2018),在可用数据上的RTX2080 Ti GPU上训练一个解码器4天。
添加了MelGAN解码器的音乐翻译网络能够以良好的质量将任意音乐域的音乐翻译到它所训练的目标域。我们将我们模型中的定性样本与原始模型进行比较5。在RTX2080 Ti GPU上,增强版只需160毫秒就能翻译1秒的输入音乐音频,比在相同硬件上的原始版快2500倍。
3.4 VQ-VAE非自回归解码器
为了进一步确定我们方法的通用性,我们将矢量量化的VAEs (van den Oord et al., 2017)中的解码器替换为我们提出的反向学习解码器。VQ-VAE是一种变分自编码器,它产生一个下采样离散潜编码的输入。VQ-VAE使用一个高容量自回归波网解码器来学习数据条件$p(x|z_q)$。
图3显示了用于音乐生成任务的VQ-VAE的改编版本。在我们的变体中,我们使用两个编码器。该本地编码器将该音频序列编码成一个64向下采样的时间序列ze。然后使用码本将该序列中的每个向量映射到512个量化向量中的1个。这与(van den Oord等人,2017)中提出的结构相同。第二个编码器输出一个全局连续值潜行向量y。

图3:采用VQ-VAE模型进行无条件的音乐生成。在训练过程中,本地编码器将输入信息沿时间维向下采样到一个序列$z_e$中,然后将其映射到一个向量嵌入字典中,形成$z_q$。全局编码器路径为带高斯后验的vanilla VAE模型的前馈路径。
我们展示了无条件钢琴音乐生成后续的定性样本(Dieleman等人,2018),其中我们在原始音频尺度上学习单层VQVAE,并使用一个普通的自回归模型(4层LSTM, 1024单元)来学习离散序列上的先验。我们无条件地使用训练好的递归先验模型对$z_q$进行采样,对y进行单位高斯分布的采样。定性地说,在相同的离散延迟序列的条件下,从全局潜在先验分布中采样会导致低电平的波形变化,如相移,但从感觉上输出听起来非常相似。通过局部编码器($z_q$)获取的离散潜在信息被高度压缩,全局潜在信息能更好地捕捉到数据条件$p(x|z_q,y)$中的随机性,因此对提高重构质量至关重要。我们使用大小为256的潜向量,并使用与mel-谱图反演实验相同的超参数进行训练。我们使用4x、4x、2x和2x比率的上采样层来实现64x上采样。
4 结论及未来工作
我们介绍了一种专为条件音频合成而设计的GAN结构,并对其进行了定性和定量的验证,证明了所提方法的有效性和通用性。我们的模型有以下优点:它非常轻量,可以在单台桌面GPU上快速训练,并且在推理时非常快。我们希望我们的生成器可以是一个即插即用的替代方案,在任何较高水平的音频相关任务中计算量大的替代方案。
虽然该模型能很好地适应训练和生成变长序列的任务,但它受到时间对齐条件信息要求的限制。实际上,它被设计用于输出序列长度是输入序列长度的一个因数的情况下,而在实践中并不总是这样。同样,基于成对的ground truth数据进行特征匹配也存在局限性,因为在某些情况下不可行。对于无条件综合,所提出的模型需要将一系列条件变量的学习延迟到其他更适合的方法,如VQ-VAE。学习用于音频的高质量无条件GAN是未来工作的一个非常有趣的方向,我们相信这将受益于结合在本工作中介绍的特定架构的选择。
5 贡献
作者要感谢NSERC、加拿大CIFAR AI主席、加拿大研究主席和IVADO提供的资助。
参考文献
Arik, S. Ö., Chrzanowski, M., Coates, A., Diamos, G., Gibiansky, A., Kang, Y., Li, X., Miller, J.,Ng, A., Raiman, J., et al. Deep voice: Real-time neural text-to-speech. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 195–204. JMLR. org, 2017.
Chan, C., Ginosar, S., Zhou, T., and Efros, A. A. Everybody dance now. arXiv preprint arXiv:1808.07371, 2018.
Dieleman, S., van den Oord, A., and Simonyan, K. The challenge of realistic music generation:modelling raw audio at scale. In Advances in Neural Information Processing Systems, pp. 7989–7999, 2018.
Donahue, C., McAuley, J., and Puckette, M. Adversarial audio synthesis. arXiv preprint arXiv:1802.04208, 2018a.
Donahue, C., McAuley, J., and Puckette, M. Adversarial audio synthesis. arXiv preprint arXiv:1802.04208, 2018b.
Dosovitskiy, A. and Brox, T. Generating images with perceptual similarity metrics based on deep networks. In Advances in neural information processing systems, pp. 658–666, 2016.
Engel, J., Resnick, C., Roberts, A., Dieleman, S., Norouzi, M., Eck, D., and Simonyan, K. Neural audio synthesis of musical notes with wavenet autoencoders. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1068–1077. JMLR. org, 2017.
Engel, J., Agrawal, K. K., Chen, S., Gulrajani, I., Donahue, C., and Roberts, A. Gansynth: Adversarial neural audio synthesis. arXiv preprint arXiv:1902.08710, 2019a.
Engel, J., Agrawal, K. K., Chen, S., Gulrajani, I., Donahue, C., and Roberts, A. Gansynth: Adversarial neural audio synthesis. arXiv preprint arXiv:1902.08710, 2019b.
Gatys, L. A., Ecker, A. S., and Bethge, M. Image style transfer using convolutional neural networks.In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2414–2423,2016.
Gibiansky, A., Arik, S., Diamos, G., Miller, J., Peng, K., Ping, W., Raiman, J., and Zhou, Y. Deep voice 2: Multi-speaker neural text-to-speech. In Advances in neural information processing systems, pp. 2962–2970, 2017.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative adversarial nets. In Advances in neural information processing systems, pp.2672–2680, 2014.
Griffin, D. and Lim, J. Signal estimation from modified short-time fourier transform. IEEE Transactions on Acoustics, Speech, and Signal Processing, 32(2):236–243, 1984.
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and Courville, A. C. Improved training of wasserstein gans. In Advances in Neural Information Processing Systems, pp. 5767–5777, 2017.
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.1125–1134, 2017.
Ito, K. The lj speech dataset. https://keithito.com/LJ-Speech-Dataset/, 2017.
Jia, Z., Maggioni, M., Staiger, B., and Scarpazza, D. P. Dissecting the nvidia volta gpu architecture via microbenchmarking. arXiv preprint arXiv:1804.06826, 2018.
Johnson, J., Alahi, A., and Fei-Fei, L. Perceptual losses for real-time style transfer and superresolution.In European conference on computer vision, pp. 694–711. Springer, 2016.
Kalchbrenner, N., Elsen, E., Simonyan, K., Noury, S., Casagrande, N., Lockhart, E., Stimberg, F.,Oord, A. v. d., Dieleman, S., and Kavukcuoglu, K. Efficient neural audio synthesis. arXiv preprint arXiv:1802.08435, 2018.
Karras, T., Aila, T., Laine, S., and Lehtinen, J. Progressive growing of gans for improved quality,stability, and variation. arXiv preprint arXiv:1710.10196, 2017.
Karras, T., Laine, S., and Aila, T. A style-based generator architecture for generative adversarial networks. arXiv preprint arXiv:1812.04948, 2018.
Kingma, D. P. and Dhariwal, P. Glow: Generative flow with invertible 1x1 convolutions. In Advances in Neural Information Processing Systems, pp. 10215–10224, 2018.
Larsen, A. B. L., Sønderby, S. K., Larochelle, H., and Winther, O. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015.
Lim, J. H. and Ye, J. C. Geometric gan. arXiv preprint arXiv:1705.02894, 2017.
Mao, X., Li, Q., Xie, H., Lau, R. Y., Wang, Z., and Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision,pp. 2794–2802, 2017.
Mathieu, M., Couprie, C., and LeCun, Y. Deep multi-scale video prediction beyond mean square error. arXiv preprint arXiv:1511.05440, 2015.
Mehri, S., Kumar, K., Gulrajani, I., Kumar, R., Jain, S., Sotelo, J., Courville, A., and Bengio,Y. Samplernn: An unconditional end-to-end neural audio generation model. arXiv preprint arXiv:1612.07837, 2016.
Miyato, T., Kataoka, T., Koyama, M., and Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957, 2018.
Mor, N.,Wolf, L., Polyak, A., and Taigman, Y. Autoencoder-based music translation. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=
HJGkisCcKm.
MORISE, M., YOKOMORI, F., and OZAWA, K. World: A vocoder-based high-quality speech synthesis system for real-time applications. IEICE Transactions on Information and Systems,E99.D(7):1877–1884, 2016. doi: 10.1587/transinf.2015EDP7457.
Neekhara, P., Donahue, C., Puckette, M., Dubnov, S., and McAuley, J. Expediting tts synthesis with adversarial vocoding. arXiv preprint arXiv:1904.07944, 2019.
Odena, A., Dumoulin, V., and Olah, C. Deconvolution and checkerboard artifacts. Distill, 2016. doi:10.23915/distill.00003. URL http://distill.pub/2016/deconv-checkerboard.Oord,
A. v. d., Li, Y., Babuschkin, I., Simonyan, K., Vinyals, O., Kavukcuoglu, K., Driessche, G.v. d., Lockhart, E., Cobo, L. C., Stimberg, F., et al. Parallel wavenet: Fast high-fidelity speech synthesis. arXiv preprint arXiv:1711.10433, 2017.
Park, T., Liu, M.-Y., Wang, T.-C., and Zhu, J.-Y. Semantic image synthesis with spatially-adaptive normalization. arXiv preprint arXiv:1903.07291, 2019.
Ping, W., Peng, K., Gibiansky, A., Arik, S. O., Kannan, A., Narang, S., Raiman, J., and Miller,J. Deep voice 3: Scaling text-to-speech with convolutional sequence learning. arXiv preprint arXiv:1710.07654, 2017.
Ping, W., Peng, K., and Chen, J. Clarinet: Parallel wave generation in end-to-end text-to-speech.arXiv preprint arXiv:1807.07281, 2018.
Prenger, R., Valle, R., and Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3617–3621. IEEE, 2019.
Salimans, T. and Kingma, D. P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Advances in Neural Information Processing Systems, pp.901–909, 2016.
Shen, J., Pang, R., Weiss, R. J., Schuster, M., Jaitly, N., Yang, Z., Chen, Z., Zhang, Y., Wang,Y., Skerrv-Ryan, R., et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), pp. 4779–4783. IEEE, 2018.
Sotelo, J., Mehri, S., Kumar, K., Santos, J. F., Kastner, K., Courville, A., and Bengio, Y. Char2wav: End-to-end speech synthesis. 2017.
Thickstun, J., Harchaoui, Z., Foster, D. P., and Kakade, S. M. Invariances and data augmentation for supervised music transcription. In International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018.
Ulyanov, D., Vedaldi, A., and Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022, 2016.
Van Den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N.,Senior, A. W., and Kavukcuoglu, K. Wavenet: A generative model for raw audio. SSW, 125, 2016.
van den Oord, A., Vinyals, O., et al. Neural discrete representation learning. In Advances in Neural Information Processing Systems, pp. 6306–6315, 2017.
Veaux, C., Yamagishi, J., MacDonald, K., et al. Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit. University of Edinburgh. The Centre for Speech Technology Research(CSTR), 2017.
Wang, T.-C., Liu, M.-Y., Zhu, J.-Y., Liu, G., Tao, A., Kautz, J., and Catanzaro, B. Video-to-video synthesis. In Advances in Neural Information Processing Systems (NIPS), 2018a.
Wang, T.-C., Liu, M.-Y., Zhu, J.-Y., Tao, A., Kautz, J., and Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8798–8807, 2018b.
Wang, Y., Skerry-Ryan, R., Stanton, D., Wu, Y., Weiss, R. J., Jaitly, N., Yang, Z., Xiao, Y., Chen, Z.,Bengio, S., et al. Tacotron: Towards end-to-end speech synthesis. arXiv preprint arXiv:1703.10135,2017.
Yamamoto, R. r9y9/wavenet_vocoder, Oct 2019. URL https://github.com/r9y9/wavenet_vocoder.
Yamamoto, R., Song, E., and Kim, J.-M. Probability density distillation with generative adversarial networks for high-quality parallel waveform generation. arXiv preprint arXiv:1904.04472, 2019.
Zhang, H., Goodfellow, I., Metaxas, D., and Odena, A. Self-attention generative adversarial networks. arXiv preprint arXiv:1805.08318, 2018.
Zhu, J.-Y., Park, T., Isola, P., and Efros, A. A. Unpaired image-to-image translation using cycleconsistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, pp. 2223–2232, 2017.
附录A 模型架构
表6:mel光谱图反演任务的生成器和鉴别器架构


图4 残差堆栈架构
附录B:超参数和训练细节
我们在所有实验中使用的批量大小为16。 Adam的学习速率为0.0001,B 1 = 0.5且B2 = 0.9被用作生成器和鉴别器的优化器。我们使用10作为特征匹配损失项的系数。 我们使用pytorch来实现我们的模型,该模型的源代码随此提交一起提供。对于VQGAN实验,我们使用大小为256的全局潜矢量,其中KL项限制在1.0以下,以避免后部崩溃。 我们在Nvidia GTX1080Ti或GTX 2080Ti上训练了我们的模型。在补充材料中,我们将重建样本显示为历时总数和挂钟时间的函数。 我们发现我们的模型在训练的很早就开始产生可理解的样本。
附录C:评价方法- MOS
我们进行了平均意见评分(MOS)测试,以比较我们的模型与竞争体系结构的性能。 我们通过收集由不同模型生成的样本以及一些原始样本来构建测试。 在训练过程中没有看到所有生成的样本。 MOS得分是根据200个人的总体计算得出的:要求他们每个人通过对1到5个样品进行评分来盲目评估从该样品池中随机抽取的15个样品的子集。对样品进行展示并一次对其进行评级 由测试人员。 测试是使用Amazon Mechanical Turk进行的众包,我们要求测试人员戴上耳机并讲英语。 在收集所有评估之后,通过平均分数$m_i$来估计模型$i$的MOS分数$\mu_i$。 来自不同模型的样本。 此外,我们计算得分的95%置信区间。$\hat{\sigma }_i$是所收集分数的标准偏差。
$$\hat{\mu}_{i}=\frac{1}{N_{i}} \sum_{k=1}^{N_{i}} m_{i, k}$$
$$C I_{i}=\left[\hat{\mu}_{i}-1.96 \frac{\hat{\sigma}_{i}}{\sqrt{N_{i}}}, \hat{\mu}_{i}+1.96 \frac{\hat{\sigma}_{i}}{\sqrt{N_{i}}}\right]$$