1. Stack和Heap
每个线程对应一个stack,线程创建的时候CLR为其创建这个stack,stack主要作用是记录函数的执行情况。值类型变量(函数的参数、局部变量等非成员变量)都分配在stack中,引用类型的对象分配在heap中,在stack中保存heap对象的引用指针。GC只负责heap对象的释放,heap内存空间管理
Heap内存分配

除去pinned object等影响,heap中的内存分配很简单,一个指针记录heap中分配的起始地址,根据对象大小连续的分配内存
Stack结构
每个函数调用时,逻辑上在thread stack中会产生一个帧(stack frame),函数返回时对应的stack frame被释放掉
用个简单的函数查看执行时CLR对栈的处理情况:
{
int r = Sum(2, 3, 4, 5, 6);
}
private static int Sum(int a, int b, int c, int d, int e)
{
return a + b + c + d + e;
}
push 4 ;第3个参数到最后一个参数压栈
push 5
push 6
mov edx,3 ;第1、第2个参数分别放入ecx、edx寄存器
mov ecx,2
call dword ptr ds:[00AD96B8h] ;调用函数Sum,执行call的时候返回地址(即下面这条mov语句的地址)自动压栈了
mov dword ptr [ebp-0Ch],eax ;将函数返回值设置到局部变量r中(函数调用结束返回值在eax寄存器中)
;====函数Sum====
push ebp ;保存原始ebp寄存器
mov ebp,esp ;将当前栈指针保存在ebp中,后面使用ebp对参数和局部变量寻址
sub esp,8 ;分配两个局部变量
mov dword ptr [ebp-4],ecx ;第1个参数放入局部变量
mov dword ptr [ebp-8],edx ;第2个参数放入局部变量
...... ;CLR的检查代码
mov eax,dword ptr [ebp-4] ;a + b + c + d + e
add eax,dword ptr [ebp-8] ;第1个参数+第2个参数(2+3)
add eax,dword ptr [ebp+10h] ;+第3个参数(4)
add eax,dword ptr [ebp+0Ch] ;+第4个参数(5)
add eax,dword ptr [ebp+8] ;+第5个参数(6)
mov esp,ebp ;恢复栈指针(局部变量被释放了)
pop ebp ;恢复原始的ebp寄存器值
ret 0Ch ;函数返回. 1: 返回地址自动出栈; 2: esp减去0Ch(12个字节),即从栈中清除调用参数; 3: 返回值在eax寄存器中

Stack状态变化过程:
a). 调用者将第3、第4、第5个参数压栈,第1、第2个参数分别放入ecx、edx寄存器
b). call指令调用函数Sum,并自动将函数返回地址压栈,代码跳转到函数Sum开始执行
c). 函数Sum先将寄存器ebp压栈保存,并将esp放入ebp,用于后面对参数和局部变量寻址
d). 定义局部变量以及省略掉的是额外代码,跟Sum函数业务无关
e). 执行加法操作,结果保存在eax寄存器中
f). 恢复esp寄存器,这样函数Sum中所有的局部变量以及其他压栈操作全部释放出来
g). 原始ebp的值出栈,恢复ebp,这样栈完全恢复到进入Sum函数调用时的状态
h). ret指令执行函数返回,返回值在eax寄存器中,返回地址为call指令压栈的地址,返回地址自动出栈。0Ch指示处理器在函数返回时释放栈中12个字节,即由被调用者清除压栈的参数。函数返回之后,本次Sum调用的栈分配全部释放
这种调用约定类似__fastcall
结合引用类型变量、值类型的ref参数,下面代码简化的stack状态如下:
代码:
{
int j = 9;
MyClass1 c = new MyClass1();
c.x = 8;
int result = Sum(i, 5, ref j, c);
}
public static int Sum(int a, int b, ref int c, MyClass1 obj)
{
int r = a + b + c + obj.x;
return r;
}
public class MyClass1
{
public int x;
}
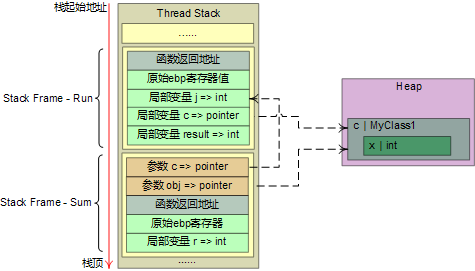
任何时候引用类型都分配在heap中,在stack中只是保存对象的引用地址。Run函数执行完毕之后,heap中的MyClass1对象c成为可回收的垃圾对象,在GC时进行回收
2. Mark-Compact 标记压缩算法
简单把.NET的GC算法看作Mark-Compact算法
阶段1: Mark-Sweep 标记清除阶段
先假设heap中所有对象都可以回收,然后找出不能回收的对象,给这些对象打上标记,最后heap中没有打标记的对象都是可以被回收的
阶段2: Compact 压缩阶段
对象回收之后heap内存空间变得不连续,在heap中移动这些对象,使他们重新从heap基地址开始连续排列,类似于磁盘空间的碎片整理

Heap内存经过回收、压缩之后,可以继续采用前面的heap内存分配方法,即仅用一个指针记录heap分配的起始地址就可以
主要处理步骤:将线程挂起=>确定roots=>创建reachable objects graph=>对象回收=>heap压缩=>指针修复
可以这样理解roots:heap中对象的引用关系错综复杂(交叉引用、循环引用),形成复杂的graph,roots是CLR在heap之外可以找到的各种入口点。GC搜索roots的地方包括全局对象、静态变量、局部对象、函数调用参数、当前CPU寄存器中的对象指针(还有finalization queue)等。主要可以归为2种类型:已经初始化了的静态变量、线程仍在使用的对象(stack+CPU register)
Reachable objects:指根据对象引用关系,从roots出发可以到达的对象。例如当前执行函数的局部变量对象A是一个root object,他的成员变量引用了对象B,则B是一个reachable object。从roots出发可以创建reachable objects graph,剩余对象即为unreachable,可以被回收

指针修复是因为compact过程移动了heap对象,对象地址发生变化,需要修复所有引用指针,包括stack、CPU register中的指针以及heap中其他对象的引用指针
Debug和release执行模式之间稍有区别,release模式下后续代码没有引用的对象是unreachable的,而debug模式下需要等到当前函数执行完毕,这些对象才会成为unreachable,目的是为了调试时跟踪局部对象的内容
传给了COM+的托管对象也会成为root,并且具有一个引用计数器以兼容COM+的内存管理机制,引用计数器为0时这些对象才可能成为被回收对象
Pinned objects指分配之后不能移动位置的对象,例如传递给非托管代码的对象(或者使用了fixed关键字),GC在指针修复时无法修改非托管代码中的引用指针,因此将这些对象移动将发生异常。pinned objects会导致heap出现碎片,但大部分情况来说传给非托管代码的对象应当在GC时能够被回收掉
3. Generational 分代算法
程序可能使用几百M、几G的内存,对这样的内存区域进行GC操作成本很高,分代算法具备一定统计学基础,对GC的性能改善效果比较明显
将对象按照生命周期分成新的、老的,根据统计分布规律所反映的结果,可以对新、老区域采用不同的回收策略和算法,加强对新区域的回收处理力度,争取在较短时间间隔、较小的内存区域内,以较低成本将执行路径上大量新近抛弃不再使用的局部对象及时回收掉
分代算法的假设前提条件:
a). 大量新创建的对象生命周期都比较短,而较老的对象生命周期会更长
b). 对部分内存进行回收比基于全部内存的回收操作要快
c). 新创建的对象之间关联程度通常较强。heap分配的对象是连续的,关联度较强有利于提高CPU cache的命中率
.NET将heap分成3个代龄区域: Gen 0、Gen 1、Gen 2
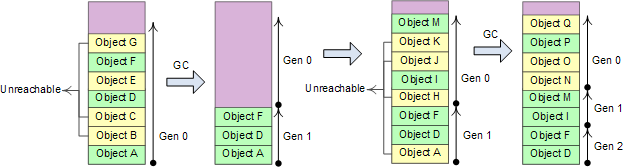
Heap分为3个代龄区域,相应的GC有3种方式: # Gen 0 collections, # Gen 1 collections, # Gen 2 collections。如果Gen 0 heap内存达到阀值,则触发0代GC,0代GC后Gen 0中幸存的对象进入Gen 1。如果Gen 1的内存达到阀值,则进行1代GC,1代GC将Gen 0 heap和Gen 1 heap一起进行回收,幸存的对象进入Gen 2。2代GC将Gen 0 heap、Gen 1 heap和Gen 2 heap一起回收
Gen 0和Gen 1比较小,这两个代龄加起来总是保持在16M左右;Gen 2的大小由应用程序确定,可能达到几G,因此0代和1代GC的成本非常低,2代GC称为full GC,通常成本很高。粗略的计算0代和1代GC应当能在几毫秒到几十毫秒之间完成,Gen 2 heap比较大时full GC可能需要花费几秒时间。大致上来讲.NET应用运行期间2代、1代和0代GC的频率应当大致为1:10:100
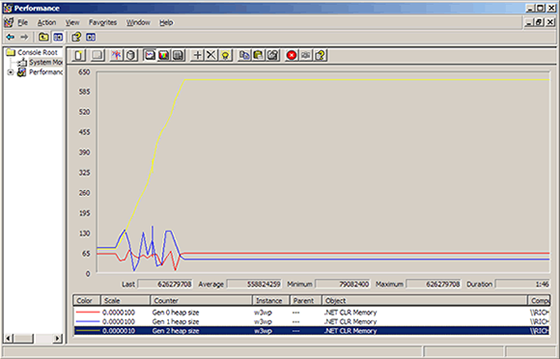
图为一个ASP.NET程序运行的Performance Moniter,Gen 0 heap size(红色)平均6M,Gen 1(蓝色)平均5M,Gen 2(黄色)达到620M,Gen 0+Gen 1平均13.2M,最大19.8M
直观上来看,程序的运行由一系列函数调用组成,函数运行期间会创建很多局部对象,函数结束之后也就产生大量待回收的对象。采用分代算法加强较新代龄的垃圾回收力度,通常能够极大的提高垃圾回收效率,否则就是极特殊的程序,或者是不合理的对象关联设计。例如ASP.NET程序,应当确保绝大部分用于HTTP 请求处理的对象在0代和1代垃圾回收中被释放掉
为heap记录几个指针可以确定代龄区域范围,创建reachable objects graph时根据对象的地址可以确定对象位于哪个代龄区域,0代GC在创建graph时如果遇到1代、2代heap对象,可以直接越过不用继续遍历下去,较老代龄的对象如果引用了较新代龄的对象,可以通过Win32 API GetWriteWatch订阅内存更新通知,记录在"card table"中,辅助较低代龄的GC正确构造graph
4. LOH
.NET 1.1和2.0中,85000字节以下的对象称为小对象,分配在Gen 0 heap中,85000字节以上的对象称为大对象,分配在Large Object Heap中,这是因为GC在heap压缩时移动大的内存块需要消耗大量CPU时间,通过性能调优实践确定了85000字节这样一个阀值
LOH只在2代GC时进行回收,采用Mark-Sweep算法,没有压缩处理,因此LOH中的内存分配是不连续的,使用一个空闲列表free list记录LOH中的空闲空间,对释放出来的空间进行管理

上图中obj1、obj2释放之后,其空间合并起来成为free list的一个节点,随后被分配给obj4
什么时候触发垃圾回收?
前面已经提到,0代和1代垃圾回收主要由阀值控制。初始时Gen 0 heap大小与CPU缓存的大小相关,运行时CLR根据内存请求状态动态调整Gen 0 heap大小,但Gen 0和Gen 1总大小保持在16M左右
Gen 2 heap和LOH都在full GC时进行回收,full GC主要由2类事件触发:
a). 进入Gen 2 heap和LOH的对象很多,超过了一定比例。RegisterForFullGCNotification的参数 maxGenerationThreshold、largeObjectHeapThreshold可以分别为Gen 2 heap和LOH设定这个值
b). 操作系统内存吃紧的时候。CLR会接收到操作系统内存紧张的通知消息,触发full GC
5. Heap细节、扩容与收缩
Heap的代龄是逻辑上的结构,heap实际内存申请和分配以及释放以segment(段)为单位,workstation GC模式segment大小为16M,server GC模式segment大小为64M。Gen 0和Gen 1 heap总是位于同一个段中,叫做ephemeral segment(新生段),因此max(Gen 0 heap size+Gen 1 heap size)≈16M || 64M,Gen 2 heap由0个或多个segments组成,LOH由1个或多个segments组成
.NET程序启动时CLR为heap创建2个segment,一个作为ephemeral segment,另一个用于LOH。.NET使用VirtualAlloc申请和分配heap内存,在LOH中分配新对象时没有足够的空间,或者1代GC 时进入Gen 2的对象过多空间不够,.NET将为LOH或者小对象heap分配新的segment。申请新的segment失败将由EE抛出OutOfMemory异常
Full GC后完全空闲的segments将被释放掉,内存返回给操作系统
.NET 2.0对GC的一个重要改进是尽量改善heap碎片处理。heap碎片主要由pinned objects引起,改善措施主要有2个方面。首先是延迟升级,如果ephemeral segment存在pinned objects,则尽可能的延迟他们升级到Gen 2的时间点,考虑pinned objects的同时尽量充分利用当前ephemeral segment的空间;其次是重复利用Gen 2的空间,如果Gen 2中存在pinned objects的segments释放出了足够空间,该segments可能重新作为ephemeral segment使用
6. GC方式
有Workstation GC with Concurrent GC off、 Workstation GC with Concurrent GC on、Server GC 3种
Workstation GC with Concurrent GC off: 用于单CPU机器实现高吞吐量,采用一系列策略观察内存分配以及每次GC的状况,动态调整GC策略,尽可能使程序随着运行时状态的变化实现高效的GC操作,但进行GC时会冻结所有线程
Workstation GC with Concurrent GC on: 用于响应时间非常重要的交互式程序,例如流媒体的播放等(如果一次full GC导致应用程序中断几秒、十几秒时间,用户将无法忍受)。这种方式利用多CPU对full GC进行并行处理,不是整个full GC期间冻结所有线程,而是将full GC切分成多次很短的时间对线程进行冻结,在线程冻结时间之外,应用程序仍然可以正常运行,进行内存分配,这主要通过将Gen 0 heap size设置的比non-concurrent GC大很多而实现,使得GC操作时线程仍然能够在Gen 0 heap中进行内存分配,但如果Gen 0 heap用完后GC仍然没有结束,线程仍然会出现阻塞。这种方式付出的代价是working set和GC所需时间比non-concurrent GC要大一些
Server GC: 用于多CPU机器的服务器应用程序实现高吞吐量和伸缩性,充分利用服务器的大内存。.NET为每个CPU创建一组heap(包括Gen 0, 1, 2和LOH)和一个GC线程,每个CPU可以独立的为相应的heap执行GC操作,而其他CPU则正常执行处理。最佳的应用场景是多线程之间内存结构基本相同,执行的工作相同或类似
单CPU机器上只能使用workstation GC,默认情况下为Workstation GC with Concurrent GC on方式,单CPU机器上配置为Server GC无效,仍然使用workstation GC;多CPU服务器上的ASP.NET默认使用Server GC方式,Server GC时不能使用concurrent方式
concurrent GC可以用于单CPU机器,它与CPU数量无关
对于ASP.NET程序应当尽量保证一个CPU仅对应一个GC线程,防止同一个CPU上面多个GC线程之间的冲突造成性能问题。如果使用了Web Garden则应当使用Workstation GC with Concurrent GC off。Web Garden为了提高吞吐量会导致多出几倍的内存使用,每个work process的内存有很多重复部分,Web Garden的最佳应用场景是多个进程之间使用一个共享的resource pool,避免内存的重复并尽可能的提高吞吐量。在这一点上Server GC应当与Web Garden类似,但Web Garden在多个进程中,而Server GC是在同一个进程中通过多线程实现,目前没有发现Server GC方面深入一些的资料,很多东西只能根据现有资料做一些猜想
为workstation GC禁用concurrent GC:
<runtime>
<gcConcurrent enabled="false"/>
</runtime>
</configuration>
<runtime>
<gcServer enabled=“true"/>
</runtime>
</configuration>
7. Finalization
具有finalize method的对象在垃圾回收时,.NET先调用finalize method,然后再进行回收,具体处理如下:
a). 在heap创建具有finalize method的对象时,对象指针会放入finalization queue;
b). 垃圾回收时,具有finalize method的对象如果成为unreachable,则将其指针从finalization queue中移除,放入freachable queue,在本次垃圾回收处理中并不对这些对象进行回收;其它没有finalize method的unreachable对象正常回收。freachable queue中的对象是reachable的(它引用到的其他对象也都是reachable的)
c). 垃圾回收结束后,如果freachable queue非空,则一个专门的运行时线程finalizer thread被唤醒,它逐个调用freachable queue中对象的finalize method,然后将其指针从freachable queue中移除
d). 经过步骤c的处理之后,第二次垃圾回收时这些对象就成为unreachable,被正常回收
因为finalize method被设计用于非托管资源的释放,对这些资源的释放可能需要较长的时间,为了优化垃圾回收处理的性能,因此将调用finalize method专门交给一个独立的线程finalizer thread异步进行处理,这样也造成finalize method的对象需要经过2次垃圾回收处理
参考:
Garbage Collection - Past, Present and Future, Patrick Dussud, 中文翻译: .NET垃圾收集器的过去现在和未来(一), (二)
C# Heap(ing) Vs Stack(ing) in .NET Part I, Part II, Part III, Part IV Matthew Cochran
Garbage Collection: Automatic Memory Management in the Microsoft .NET Framework Jeffrey Richter
Garbage Collection Part 2: Automatic Memory Management in the Microsoft .NET Framework Jeffrey Richter
CLR Inside Out: Large Object Heap Uncovered Maoni Stephens
Heap: Pleasures and Pains Murali R. Krishnan
The Dangers of the Large Object Heap Andrew Hunter
Garbage Collection Notifications
Garbage Collector Basics and Performance Hints Rico Mariani
CLR Inside Out: Investigating Memory Issues Claudio Caldato and Maoni Stephens
Understanding Garbage Collection in .NET Andrew Hunter
Using GC Efficiently Part 1, Part 2, Part 3, Part 4 Maoni Stephens
Notes on the CLR Garbage Collector Vineet Gupta
The Mystery of Concurrent GC Mark Smith
Garbage Collection Curriculum Ferreira Paulo, Veiga Luís
Java theory and practice: A brief history of garbage collection Brian Goetz
转自: http://www.cnblogs.com/RicCC/archive/2009/09/01/dotnet-memory-management-and-garbage-collection.html
后记:经历过别人问.Net的GC机制还能做些什么优化后,我跟同事朋友讨论过N次有关于这个问题,今天我突然想到一点:能不能在GC中应用一下Observer Pattern? 即当root变量被回收时,可不可以让他来通知GC做些事情。 我只是突然想到这些,不知道可行不,但至少我想了。