引言
本文是对《Microsoft SQL SERVER 2008技术内幕 T-SQL查询》中的第一章做的阅读笔记,这一章的主要内容是分析SQL查询中各子句的执行顺序。如果你对此已了然于胸了,那可以直接略过本文;如果你时间比较珍贵,则可以大致看一下流程图;如果你想更详细地了解,则可以去阅读“T-SQL查询”这本书。
下面我写了几道测试题,如果你对于这些问题不知其所以然,那我还是建议你看看这本书,再不济也应该好好看看本文。(越想走得远,就越应该重视基础)
测试题
1、 对full join、cross join(select * from orders,customers)是否有一个清晰的认识?
SELECT * FROM Orders CROSS JOIN Customers ON Orders.customerid=Customers.customerid;(错)
2、 在创建视图时,如果不包含top时,为什么就不能使用order by?
CREATE VIEW V AS SELECT * FROM orders ORDER BY orderId;(错)
CREATE VIEW V AS SELECT TOP 10 * FROM orders ORDER BY orderId ;(对)
3、 为什么select列表中的别名不能在where子句中使用?
SELECT customerId AS Id FROM orders WHERE Id>5;(错)
4、 使用了group by 子句的查询语句中,为什么having或select子句中列只能是group by 子句中的列或是包裹在聚合函数中?
SELECTorderId,customerId FROM orders GROUP BY orderId HAVING customerId =15;(错)
5、 在多表联接查询时,什么情况下过滤条件加在where或on上的作用是一样的?
逻辑查询处理
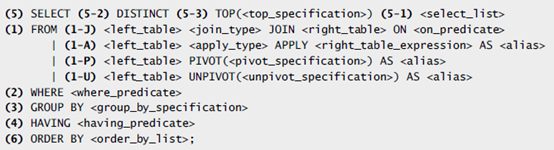
步骤序号:
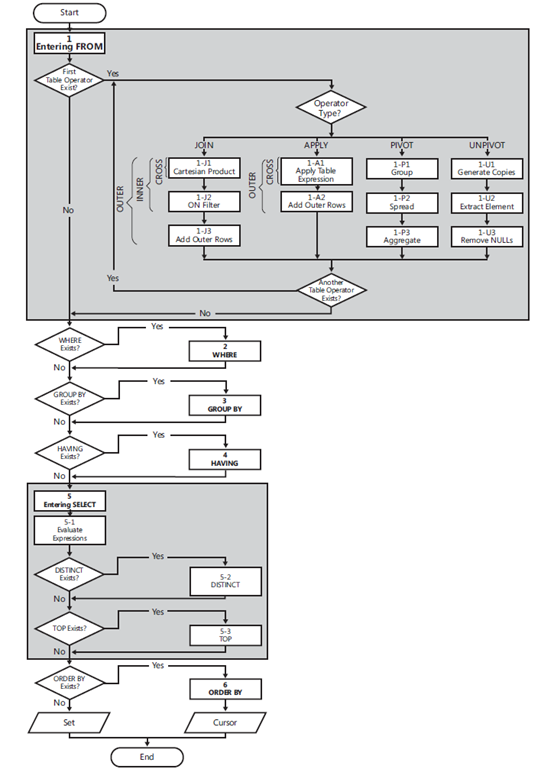
流程图:
处理阶段简介:
(1)FROM 处理表运算符生成虚拟表VT1。以Join运算符为例,join有三个子阶段
(1-J1)笛卡尔积 两个表执行笛卡尔积(交叉联接),生成虚拟表VT1-J1。
(1-J2)ON筛选器 对VT1-J1中的行根据ON子句中的条件进行筛选,只有条件为true的行,才能插入VT1-J2中。
(1-J3)添加外部行 如果指定了outer join,则将保留表(比如用left join时,则左表为保留表)中没有匹配的行,作为外部行添加到VT1-J2,生成VT1-J3。
(2)WHERE 根据where子句中的条件,对VT1中的行进行筛选,只有条件为true的行才会插入VT2中。
(3)GROUP BY 对VT2中的行进行分组,生成VT3。最终,每个分组只有一个结果行。
(4)HAVING 根据having子句的条件,对VT3中的分组进行筛选,只有条件为true的组,才会插入到VT4中。
(5)SELECT 处理select子句中的元素产生VT5。
(5-1)计算表达式 计算select中列的表达式,生成VT5-1。
(5-2)DISTINCT 删除VT5-1中的重复行,生成VT5-2。
(5-3)TOP 根据order by 子句定义的逻辑排序,从VT5-2中选择前面指定数量或百分比的行,生成VT5-3。
(6)ORDER BY 根据order by子句中的列,对VT5-3中的列进行排序,生成游标VC6。
其它表运算符的逻辑查询处理简介
APPLY
APPLY涉及下面两个步骤中的一步或两步(取决于APPLY类型):
- A1: 用左表中的每一行应用与右边的表达式,最后组合生成虚拟表A1。
- A2:添加外部行。(针对于OUTER APPLY)
PIVOT
示例:SELECT * FROM Orders PIVOT (SUM(val) FOR orderYear IN ([2006],[2007]) )AS P
PIVOT涉及以下三个逻辑阶段:
- P1:分组。隐式地对Orders中的行进行分组,分组依据是那些未作为pivot输入的所有列,分组生成虚拟表P1。(从示例查询语句中可以看到Pivot运算符引用Orders的两个列作为输入参数(val,orderYear))。
- P2:扩展。把in列表中的值扩展到它们相应的目标列上。在逻辑上,相当于为in子句中指定的每个目标列使用了case表达式: CASE WHEN orderYear= 2006 THEN val END
- P3:聚合。对每个case表达式应用指定的聚合函数,生成结果列。SUM(CASE WHEN orderYear= 2006 THEN val END) AS [2006]。
UNPIVOT
示例:SELECT * FROM 数据源表 UNPIVOT( val FOR orderYear IN ([2006],[2007])) AS U
UNPIVOT涉及以下三个逻辑阶段:
- U1:生成副本。循环In中的列名,每一列都会生成一个左表的副本。这一步生成的虚拟表如表U1所示。
- U2:提取元素。从来源列中提取出与行的当前副本所代表的转换元素相对应的值。这一步生成的虚拟表如表U2所示。
- U3:删除带NULL的行。这一步生成的虚拟表如表U3所示。