1.创建表
这里我们需要创建四张表,之间对应关系如下:
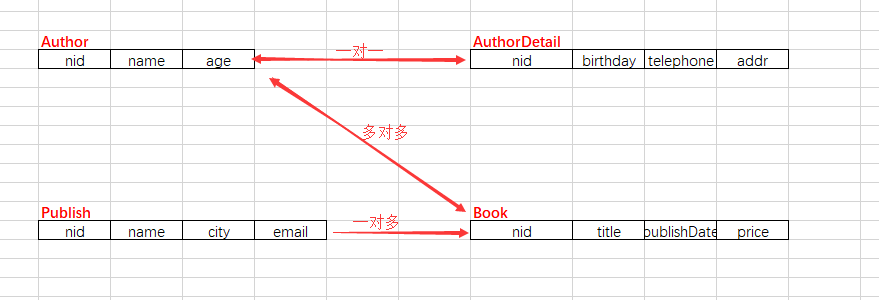
创建一对一的关系:OneToOne("要绑定关系的表名")
创建一对多的关系:ForeignKey("要绑定关系的表名")
创建多对多的关系:ManyToMany("要绑定关系的表名") 会自动创建第三张表
相关代码:
class Author(models.Model): nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) age = models.IntegerField() # 建立一对一关系 authorDetail = models.OneToOneField(to="AuthorDetail",on_delete=models.CASCADE) class AuthorDetail(models.Model): nid = models.AutoField(primary_key=True) birthday = models.DateField() telephone = models.IntegerField() addr = models.CharField(max_length=64) class Publish(models.Model): nid = models.IntegerField(primary_key=True) name = models.CharField(max_length=32) email = models.EmailField() city = models.CharField(max_length=32) class Book(models.Model): nid = models.IntegerField(primary_key=True) title = models.CharField(max_length=32) publishDate = models.DateField() price = models.DecimalField(max_digits=5,decimal_places=2) # 创建一对多关联关系,外键字段建在多的一方 publish = models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) # 创建多对多关联关系,外键关联字段随便创在哪边 authors = models.ManyToManyField(to="Author")
同步后数据库样式如下:



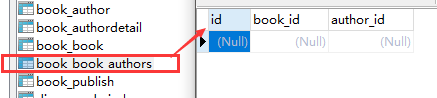
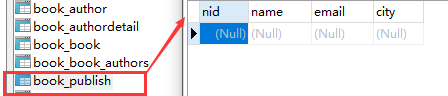
创建表时注意事项:
1.id 字段是自动添加的,自己添加了也没关系
2.外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名,自己不用添加
2.添加数据
2.1一对多添加记录
# 方式1(推荐使用) book_obj = Book.objects.create(nid=4,title="书3",publishDate="2001-4-5",price=50,publish_id=1) # 方式2 pubobj = Publish.objects.filter(name="出版社2").first() Book.objects.create(nid=8,title="书3",publishDate="1528-5-5",price=10,publish=pubobj) # 方式3 pubobj = Publish.objects.get(name="出版社1") book1 = Book(nid=4,title="书1",publishDate="2008-5-5",price=102,publish=pubobj) book1.save()
# 这里由于之前添加数据时忘记添加了主键自增,本应该让django自动创建,手贱添加了,现在添加记录必须加上nid,否则会报错
2.2多对多添加记录
先找见书对象,在找见关于该书的这几个作者对象,在通过使用add方法绑定多对多的关系
# 创建书籍对象 book_obj = Book.objects.create(nid=9,title="书5",publishDate="2015-5-5",price=166,publish_id=1) # 给书籍绑定作者对象 luffy_obj = Author.objects.filter(name="luffy").first() zoro_obj = Author.objects.filter(name="zoro").first() # 绑定多对多关系,像book_author关系表中添加记录 book_obj.authors.add(luffy_obj,zoro_obj)
相关API
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[]) book_obj.authors.clear() #清空被关联对象集合 book_obj.authors.set() #先清空再设置
3.查找数据
3.1一对一查询(authorDetail与author)
# 正向查询:关联属性在author表中,所以author对象找关联作者详细信息对象,正向查询 # 查找luffy所在的地址 luffy_obj = Author.objects.filter(name="luffy").first() print(luffy_obj.authorDetail.addr) # 反向查询:关联属性在author表中,所以authordetail对象找关联作者对象,反向查询 # 查找手机号是1546的作者的姓名 detail_obj = AuthorDetail.objects.filter(telephone=1561).first() print(detail_obj.author.name)
3.2一对多查询(publish与book)
正向查询(按字段:publish):
反向查询(按表名:book_set)
# 查询主键为1的书籍的出版社所在的城市
# 这里的book_obj.publish主键为1的书籍对象关联的出版社对象
book_obj = Book.objects.filter(nid=1).first()
print(book_obj.publish.city)
# 查询出版社2出版过的所有书籍名称
pub_obj = Publish.objects.filter(name="出版社2").first()
book_obj = pub_obj.book_set.all().values("title")
# values之后得到一个字典queryset类型
for obj_dic in book_obj:
print(obj_dic.get("title"))
# 或这样写
pub_obj = Publish.objects.get(name="出版社2")
book_list = pub_obj.book_set.all()
for obj in book_list:
print(obj.title)
# 这里重点要掌握反向查询中的FOO_set的使用
3.3多对多查询(authors与book_set)
正向查询(按字段authors)
反向查询(按表名book_set)
# 查询关于书5的所有的作者的姓名和年龄
book_query = Book.objects.filter(title="书5")
for obj in book_query:
auth_query = obj.authors.values("name", "age")
print(auth_query)
# 查询luffy出版的相关书籍信息
luffy_query = Author.objects.filter(name="luffy")
for obj in luffy_query:
author_query = obj.book_set.values("title","price")
print(author_query)
3.4 releated_name的使用技巧
在一对多ForeignKey(),多对多ManyToManyField的反向查询中,我们可以在它的定义中设置 related_name 的值来覆写 FOO_set 的名称,例如我们在多对多的字段定义中再添加一个属性
authors = models.ManyToManyField(to="Author",related_name="book_list")
此时查询luffy出版的相关书籍
luffy_obj = Author.objects.filter(name="luffy").first() book_obj = luffy_obj.book_list.all()
这么做说白了就给他反向查询中换个名字而已
3.5 一对多正向查询(book→publish)和多对多(book→author)正向查询的区别:
一对多:没有all属性,可以直接以obj.字段.name获取name值
多对多:要获取name值,必须以obj.字段.all()获取所有,在通过循环获取name值
4.基于双下划线的跨表查询
遵循原则:
正向查询按字段,反向查询按表名,表名小写
# 一对多
# 出版社2出版过的所有的书籍名字与价格
# 正向查
ret = Book.objects.filter(publish__name="出版社2").values("title","price")
# 反向查
ret = Publish.objects.filter(name="出版社2").values("book__title","book__price")
# 多对多
# 张三出版过的所有的书籍的名字
# 正向查
ret = Book.objects.filter(authors__name="张三").values("title")
# 反向查
ret = Author.objects.filter(name="张三").values("book__title")
# 查询luffy出版的相关书籍信息
author_query = Author.objects.filter(name="luffy").values("book__title","book__price")
print(author_query)
# 一对一
# 查询authorDetail的id是1的人方名字
# 正向查
ret = Author.objects.filter(authorDetail__nid=1).values("name")
# 反向查
ret = AuthorDetail.objects.filter(nid=1).values("author__name")
4.1连续跨表查询
# 查询出版社1出版过的所有书籍名字以及作者姓名
# 正查
ret = Book.objects.filter(publish__name="出版社1").values("title","authors__name")
# 反查
ret = Publish.objects.filter(name="出版社1").values("book__title","book__authors__name")
# 居住在湖北的作者出版过的所有书籍名称以及出版社名称
# 正查
ret = Book.objects.filter(authors__authorDetail__addr="湖北").values("title","publish__name")
# 反查(这个本来此想着直接从AuthorDetail下手,但是不行,好好想想为什么)
ret = Author.objects.filter(authorDetail__addr="湖北").values("book__title","book__publish__name")
5.聚合查询与分组查询
5.1聚合
aggregate(*args, **kwargs),只对一个组进行聚合
# 计算所有图书的平均价格
from django.db.models import Avg,Count,Max,Min
ret=Book.objects.all().aggregate(avg=Avg("price"))
# {'avg': 147.5}
aggregate()是QuerySet 的一个终止子句,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。
键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
如果希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数
from django.db.models import Avg, Max, Min
Book.objects.aggregate(Avg('price'), Max('price'), Min('price'))
5.2分组
annotate():为QuerySet中每一个对象都生成一个独立的汇总值。
是对分组完之后的结果进行的聚合,结果是queryset类型
# 记住先导入分组函数啊
from django.db.models import Count, Avg, Sum, Max, Min
# 统计每本书的作者
ret = Book.objects.all().annotate(authnum=Count("authors__name"))
# 统计每一个出版社最便宜的书
ret = Book.objects.all().annotate(minprice=Min("price"))
ret = Book.objects.annotate(minprice=Min("price")) # 这两者结果是一样的
# 统计每一本以书字开头的书籍的作者个数
ret = Book.objects.filter(title__startswith="书").annotate(count=Count("authors__name"))
# 统计不止一个作者的书籍名称
ret = Book.objects.annotate(numauth=Count("authors__name")).filter(numauth__gt=1).values("title", "numauth")
# 根据一本图书作者数量的多少对查询集 QuerySet进行排序
ret = Book.objects.all().annotate(numauth=Count("authors__name")).order_by("numauth")
# 查询各个作者出的书的总价格
ret = Author.objects.all().annotate(sums=Sum("book__price")).values("name", "sums")
ret = Book.objects.all().values("authors__name").annotate(sums=Sum("price")).values("authors__name", "sums")
6.F查询和Q查询
对字段之间的值进行比较
6.1 F查询
# 查询评论数大于收藏数的书籍
from django.db.models import F
Book.objects.filter(commnetNum__lt=F('keepNum'))
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
# 查询评论数大于收藏数2倍的书籍
Book.objects.filter(commnetNum__lt=F('keepNum') * 2)
通过F查询,我们也可以在修改操作中对当中的数进行增加或减少
Book.objects.all().update(price=F("price")+30)
6.2 Q查询
Q查询源码:
class Q(tree.Node):
"""
Encapsulates filters as objects that can then be combined logically (using
`&` and `|`).
"""
# Connection types
AND = 'AND'
OR = 'OR'
default = AND
def __init__(self, *args, **kwargs):
super(Q, self).__init__(children=list(args) + list(kwargs.items()))
def _combine(self, other, conn):
if not isinstance(other, Q):
raise TypeError(other)
obj = type(self)()
obj.connector = conn
obj.add(self, conn)
obj.add(other, conn)
return obj
def __or__(self, other):
return self._combine(other, self.OR)
def __and__(self, other):
return self._combine(other, self.AND)
def __invert__(self):
obj = type(self)()
obj.add(self, self.AND)
obj.negate()
return obj
def resolve_expression(self, query=None, allow_joins=True, reuse=None, summarize=False, for_save=False):
# We must promote any new joins to left outer joins so that when Q is
# used as an expression, rows aren't filtered due to joins.
clause, joins = query._add_q(self, reuse, allow_joins=allow_joins, split_subq=False)
query.promote_joins(joins)
return clause
传入条件进行查询
q1 = Q()
q1.connector = 'OR'
q1.children.append(('id', 1))
q1.children.append(('id', 2))
q1.children.append(('id', 3))
models.Tb1.objects.filter(q1)
合并条件进行查询
con = Q()
q1 = Q()
q1.connector = 'OR'
q1.children.append(('id', 1))
q1.children.append(('id', 2))
q1.children.append(('id', 3))
q2 = Q()
q2.connector = 'OR'
q2.children.append(('status', '在线'))
con.add(q1, 'AND')
con.add(q2, 'AND')
models.Tb1.objects.filter(con)
这里重点掌握三个语法与,或,非
from django.db.models import Q # 查询id大于1并且评论数大于100的书 ret = Book.objects.filter(nid__gt=1,commentNum__gt=100) ret = Book.objects.filter(Q(nid__gt=1)&Q(commentNum__gt=100)) # 查询评论数大于100或者阅读数小于200的书 ret = Book.objects.filter(Q(commentNum__gt=100)|Q(readNum__lt=200)) # 查询年份不是2017年或者价格大于200的书 ret = Book.objects.filter(~Q(publishDdata__year=2017)&Q(price__gt=200))