一、预选赛题------文本情感分类模型
本预选赛要求选手建立文本情感分类模型,选手用训练好的模型对测试集中的文本情感进行预测,判断其情感为「Negative」或者「Positive」。所提交的结果按照指定的评价指标使用在线评测数据进行评测,达到或超过规定的分数线即通过预选赛。
二、比赛数据
训练集数据:(6328个样本)

测试集数据(2712个样本)

评价方法:AUC
三、分析
1、加载模块
import pandas as pd import numpy as np import matplotlib.pyplot as plt import re from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score from sklearn.feature_extraction.text import TfidfTransformer,TfidfVectorizer
2、数据读取
train_data = pd.read_csv('./data/train.csv',engine = 'python') test_data = pd.read_csv('./data/20190520_test.csv')
3、数据预处理
test_data.info() ###可以看到有5个缺失值。
###缺失值处理
train_data = train_data.dropna (axis=0,subset = ['label'])
###标签数据处理,label转成(0,1)
train_data['label'] = train_data['label'].replace(to_replace=['Positive', 'Negative'], value=[0, 1])
###评论数据处理
1、去除一些【标点符号、数字、特殊符号、等】
2、分词,去除句子的空格前缀(strip),单词最小化(lower)
3、去除一些【短词】和【停用词】,大多数太短的词起不到什么作用,比如‘pdx’,‘his’,‘all’。
4、提取词干,将不同但同义的词转化成相同的词,如loves,loving,lovable变成love
###评论数据处理 def filter_fun(line): #表示将data中的除了大小写字母之外的符号换成空格,去除一些标点符号、特征符号、数字等 line = re.sub(r'[^a-zA-Z]',' ',line) ##单词小写化 line = line.lower() return line train_data['review'] = train_data['review'].apply(filter_fun) test_data['review'] = test_data['review'].apply(filter_fun) ##把空格前缀去除 train_data['review'] = train_data['review'].str.strip() test_data['review'] = test_data['review'].str.strip() ##删除短单词 train_data['review'] = train_data['review'].apply(lambda x:' '.join([w for w in x.split() if len(w) > 3])) test_data['review'] = test_data['review'].apply(lambda x:' '.join([w for w in x.split() if len(w) > 3])) ##分词 train_data['review'] = train_data['review'].str.split() test_data['review'] = test_data['review'].str.split()
##提取词干,即基于规则从单词中去除后缀的过程。例如,play,player,played,plays,playing都是play的变种。 from nltk.stem.porter import * stemmer =PorterStemmer() train_data['review'] = train_data['review'].apply(lambda x: [stemmer.stem(i) for i in x]) test_data['review'] = test_data['review'].apply(lambda x: [stemmer.stem(i) for i in x]) train_data['review'] = train_data['review'].apply(lambda x:" ".join(x)) test_data['review'] = test_data['review'].apply(lambda x:" ".join(x))
########################以下部分可以不处理##################
3、数据分析
在这次比赛中数据分析没起什么作用,因为评论做了脱敏处理。
####################################
1、数据集中最常见的单词有哪些?【可采用词云】
2、数据集上表述积极和消极的常见词汇有哪些?【可采用词云】
3、评论一般有多少主题标签?
4、我的数据集跟哪些趋势相关?
5、哪些趋势跟情绪相关?他们和情绪是吻合的吗?
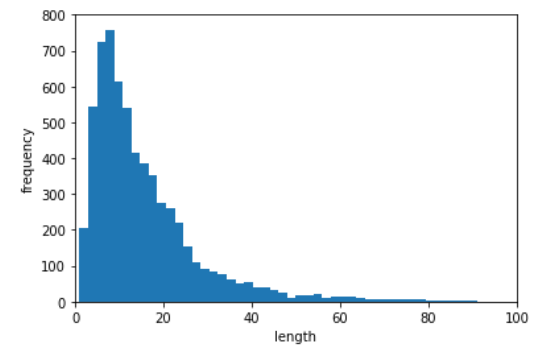
6、词长与频次的关系【画柱状图,此次代码中平均词长为15】
#使用 词云 来了解评论中最常用的词汇 all_words = ' '.join([text for text in combi['review']]) from wordcloud import WordCloud wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=110).generate(all_words) plt.figure(figsize=(10, 7)) plt.imshow(wordcloud, interpolation="bilinear") plt.axis('off') plt.show()

# 积极数据 positive_words =' '.join([text for text in combi['review'][combi['label'] == 0]]) wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=110).generate(positive_words) plt.figure(figsize=(10, 7)) plt.imshow(wordcloud, interpolation="bilinear") plt.axis('off') plt.show() # 消极数据 negative_words = ' '.join([text for text in combi['review'][combi['label'] == 1]]) wordcloud = WordCloud(width=800, height=500,random_state=21, max_font_size=110).generate(negative_words) plt.figure(figsize=(10, 7)) plt.imshow(wordcloud, interpolation="bilinear") plt.axis('off') plt.show() def hashtag_extract(x): hashtags = [] # Loop over the words in the tweet for i in x: ht = re.findall(r"#(w+)", i) hashtags.append(ht) return hashtags # extracting hashtags from non racist/sexist tweets HT_positive = hashtag_extract(combi['review'][combi['label'] == 0]) # extracting hashtags from racist/sexist tweets HT_negative = hashtag_extract(combi['review'][combi['label'] == 1]) # unnesting list HT_positive = sum(HT_positive,[]) HT_negative = sum(HT_negative,[]) # 画积极标签 a = nltk.FreqDist(HT_positive) d = pd.DataFrame({'Hashtag': list(a.keys()),'Count': list(a.values())}) # selecting top 10 most frequent hashtags d = d.nlargest(columns="Count", n = 10) #前十 plt.figure(figsize=(16,5)) ax = sns.barplot(data=d, x= "Hashtag", y = "Count") ax.set(ylabel = 'Count') plt.show() # 画消极标签 b = nltk.FreqDist(HT_negative) e = pd.DataFrame({'Hashtag': list(b.keys()),'Count': list(b.values())}) # selecting top 10 most frequent hashtagse = e.nlargest(columns="Count", n = 10) plt.figure(figsize=(16,5)) ax = sns.barplot(data=e, x= "Hashtag", y = "Count") ax.set(ylabel = 'Count') plt.show()

##数据分析 def split_word(s): return len(s.split()) train_data['word_length'] = train_data['review'].apply(split_word) sum_len , nums ,maxnum , minnum = sum(train_data['word_length']) , len(train_data['word_length']) , max(train_data['word_length']) ,min(train_data['word_length']) print("all words number: {0} , mean word length : {1} ,max word length: {2} and min: {3} ".format(sum_len , sum_len // nums , maxnum,minnum)) ##评论词长---频次 plt.xlabel('length') plt.ylabel('frequency') plt.hist(train_data['word_length'],bins = 150) plt.axis([0,100,0,800]) plt.show()
#######################################################3
4、模型
训练模型----两部分(文本特征提取、文本分类)
1、文本特征提取:词袋模型、TF_IDF、word_embbeding
2、文本分类:逻辑回归、SVM、贝叶斯、LSTM、textCNN等
【在这次预选赛中,效果最好的是 TF_IDF + 贝叶斯 ----0.86】
【试了 词袋模型 + LR 和 TF_IDF + LR(这两种效果最差)、词袋模型 + 贝叶斯 (效果一般)----0.84、TF_IDF + 贝叶斯(效果最好)】
(1)文本特征提取:
①词袋模型
#构建词袋模型 from sklearn.feature_extraction.text import CountVectorizer bow_vectorizer = CountVectorizer(max_df=0.30, max_features=8200, stop_words='english') X_train = bow_vectorizer.fit_transform(train_data['review']) X_test = bow_vectorizer.fit_transform(test_data['review']) print(test_data.describe()) print(X_train.toarray())
②TF-IDF模型
#####TF-IDF模型 ngram = 2 vectorizer = TfidfVectorizer(sublinear_tf=True,ngram_range=(1, ngram), max_df=0.5) X_all = train_data['review'].values.tolist() + test_data['review'].values.tolist() # Combine both to fit the TFIDF vectorization. lentrain = len(train_data) vectorizer.fit(X_all) X_all = vectorizer.transform(X_all) X_train = X_all[:lentrain] # Separate back into training and test sets. X_test = X_all[lentrain:]
(2)文本分类模型
①逻辑回归
# 逻辑回归构建模型 #切分训练集和测试集 # xtrain_bow, xvalid_bow, ytrain, yvalid = train_test_split(X_train, train_data['label'], random_state=42, test_size=0.3) X_train_part,X_test_part,y_train_part,y_test_part = train_test_split(X_train,train_data['label'],test_size = 0.2) # 使用词袋模型特征集合构建模型 lreg = LogisticRegression() lreg.fit(X_train_part, y_train_part) prediction = lreg.predict_proba(X_test_part) # predicting on the validation set prediction_int = prediction[:,1] >= 0.3 prediction_int = prediction_int.astype(np.int) print("回归f",f1_score(y_test_part, prediction_int)) # calculating f1 score fpr, tpr, thresholds = roc_curve(y_test_part, prediction_int) print('回归auc',auc(fpr, tpr)) test_pred = lreg.predict_proba(X_test) print("这里P:",test_pred)
保存测试结果
print(test_pred.size) test_pred_int = test_pred[:,1] #提取我们需要预测的test的label列 print(test_pred_int.size) #看看进过模型预测后的长度是否有变化 print(pd.DataFrame(test_data,columns=["ID"]).size) #看看原始test的数据列有多少 test_data['Pred'] = test_pred_int submission = test_data[['ID','Pred']] submission.to_csv('./result.csv', index=False) # writing data to a CSV file
②贝叶斯模型
from sklearn.model_selection import train_test_split,KFold #from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB,BernoulliNB,MultinomialNB from sklearn.metrics import roc_auc_score,auc,roc_curve #from sklearn.svm import SVC #import xgboost as xgb X_train_part,X_test_part,y_train_part,y_test_part = train_test_split(X_train,train_data['label'],test_size = 0.2) clf = MultinomialNB() clf.fit(X_train_part,y_train_part) y_pred = clf.predict_proba(X_train_part) fpr, tpr, thresholds = roc_curve(y_train_part, y_pred[:,1]) auc(fpr, tpr) ###0.9992496306904572 y_pred = clf.predict_proba(X_test_part) fpr, tpr, thresholds = roc_curve(y_test_part, y_pred[:,1]) auc(fpr, tpr) ###0.8613719824212871
clf = MultinomialNB() clf.fit(X_train,train_data['label']) y_pred_text = clf.predict_proba(X_test) ##保存测试结果 submit = pd.DataFrame() submit['ID'] = test['ID'] submit['Pred'] = y_pred_text[:,1] submit.to_csv('submit_bayes_2.csv',index=False)
参考:https://blog.csdn.net/Strawberry_595/article/details/90205761